This repository has some examples of using Spark and SparkSQL with Python through PySpark
We will work with the Profeco dataset, which you can download here: Profeco , is a daily historical record of more than 2,000 products, as of 2015, in various establishments in Mexico
- How many records are there?
- How many categories are there?
- How many trade chains are being monitored (and therefore reported in that database)?
- What are the most monitored products in each state of the country?
- What is the trade chain with the greatest variety of monitored products?
I will separate in another file "tweets_geo.csv" all the different tweets with their geographic data information, this will help in the manipulation of this data in a query with sparkSQL
Check the data preparation code here
The details of the code for the API REST is in the folder API in this repository
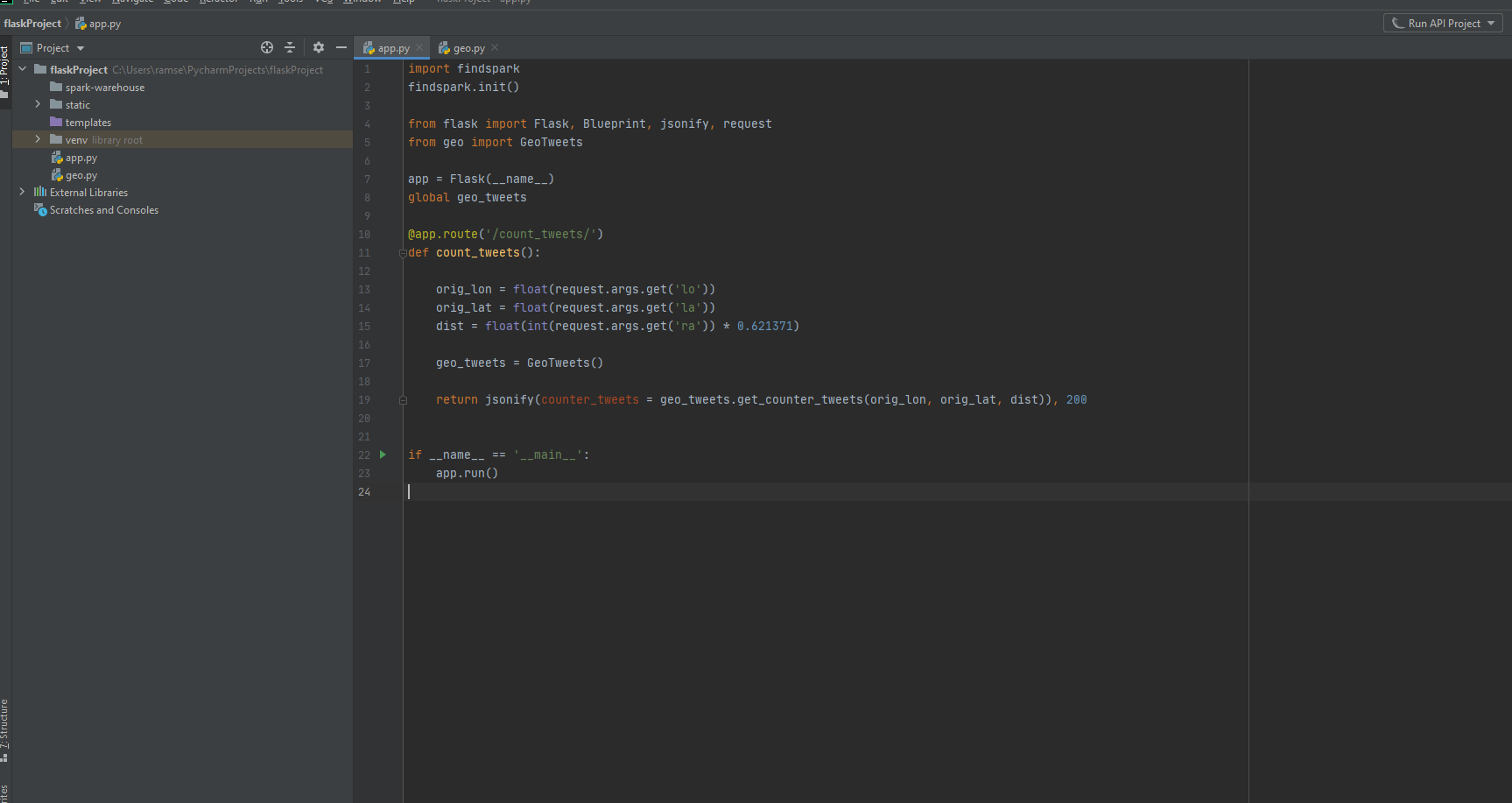
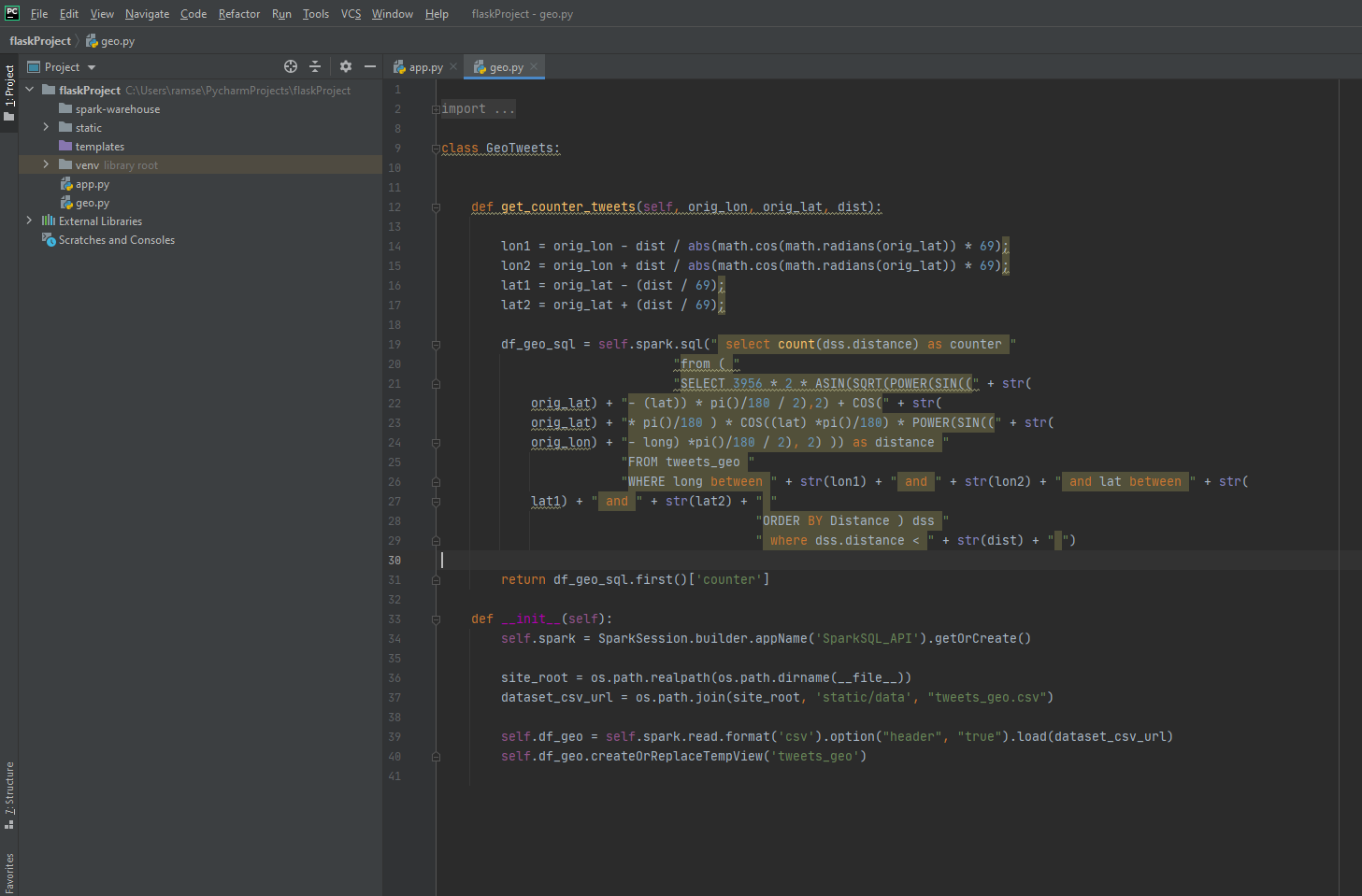
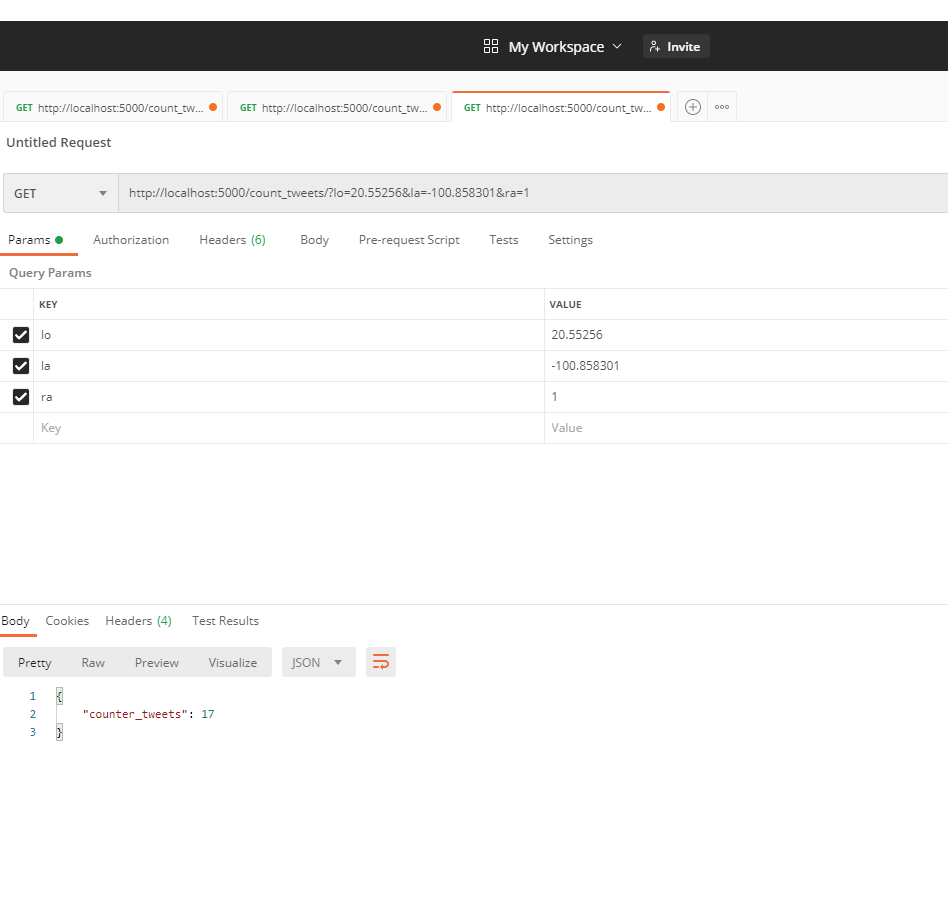
Any ideas or feedback about this repository?. Help me to improve it.
- Created by Ramses Alexander Coraspe Valdez
- Created on 2020
This project is licensed under the terms of the MIT license.