
1. Overview [Paper] [Project Webpage] [PyNET PyTorch]
This repository provides the implementation of the deep learning-based bokeh effect rendering approach presented in this paper. The model is trained to map the standard narrow-aperture images into shallow depth-of-field photos captured with a professional Canon 7D DSLR camera. The presented approach is camera independent, does not require any special hardware, and can also be applied to the existing images. More visual results of this method on the presented EBB! dataset and its comparison to the Portrait Mode of the Google Pixel Camera app can be found here.
- Python: scipy, numpy, imageio and pillow packages
- TensorFlow 1.x / 2.x + CUDA cuDNN
- Nvidia GPU
- Download the pre-trained VGG-19 model and put it into
vgg_pretrained/folder. - Download the pre-trained PyNET model and put it into
models/original/folder. - Download the EBB! dataset and extract it into
ebb_dataset/folder.
This folder should contain two subfolders:train/andtest/
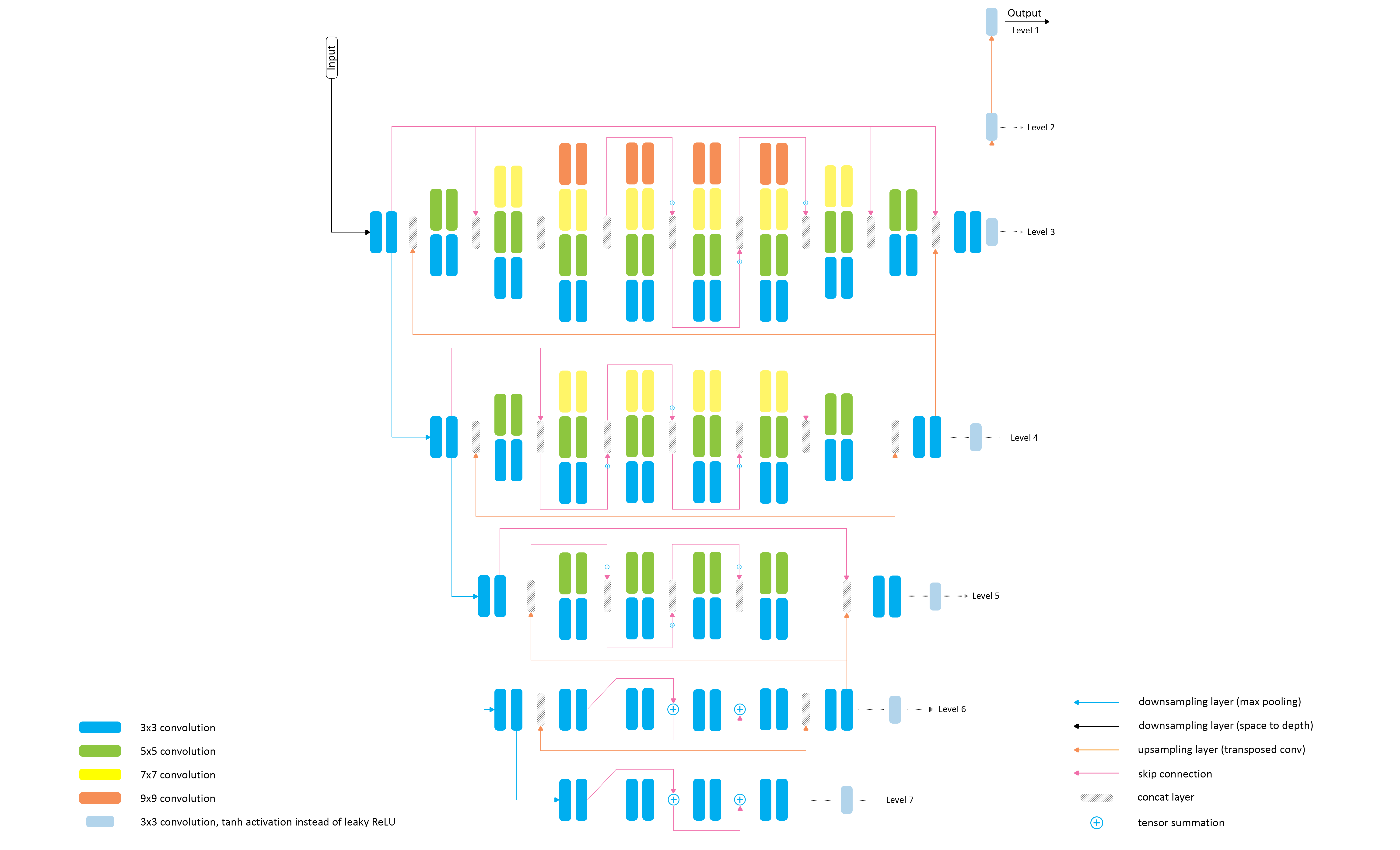
The proposed PyNET-based architecture has an inverted pyramidal shape and is processing the images at seven different scales (levels). The model is trained sequentially, starting from the lowest 7th layer, which allows to achieve good semantically-driven reconstruction results at smaller scales that are working with images of very low resolution and thus performing mostly global image manipulations. After the bottom layer is pre-trained, the same procedure is applied to the next level till the training is done on the original resolution. Since each higher level is getting upscaled high-quality features from the lower part of the model, it mainly learns to reconstruct the missing low-level details and refines the results. In this work, we additionally use two transposed convolutional layers on top of the main model (Levels 1, 2) that upsample the images to their target size.
The model is trained level by level, starting from the lowest (7th) one:
python train_model.py level=<level>Obligatory parameters:
level:7, 6, 5, 4, 3, 2, 1
Optional parameters and their default values:
batch_size:50- batch size [small values can lead to unstable training]
train_size:4894- the number of training images randomly loaded each 1000 iterations
eval_step:1000- eacheval_stepiterations the accuracy is computed and the model is saved
learning_rate:5e-5- learning rate
restore_iter:None- iteration to restore (when not specified, the last saved model for PyNET'slevel+1is loaded)
num_train_iters:5K, 5K, 20K, 20K, 30K, 80K, 100K (for levels 5 - 0)- the number of training iterations
vgg_dir:vgg_pretrained/imagenet-vgg-verydeep-19.mat- path to the pre-trained VGG-19 network
dataset_dir:ebb_dataset/- path to the folder with the EBB! dataset
Below we provide the commands used for training the model on the Nvidia Tesla V100 GPU with 16GB of RAM. When using GPUs with smaller amount of memory, the batch size and the number of training iterations should be adjusted accordingly:
python train_model.py level=7 batch_size=50 num_train_iters=5000
python train_model.py level=6 batch_size=50 num_train_iters=5000
python train_model.py level=5 batch_size=40 num_train_iters=20000
python train_model.py level=4 batch_size=14 num_train_iters=20000
python train_model.py level=3 batch_size=9 num_train_iters=30000
python train_model.py level=2 batch_size=9 num_train_iters=80000
python train_model.py level=1 batch_size=5 num_train_iters=100000python test_model.py orig=trueOptional parameters:
use_gpu:true,false- run the model on GPU or CPU
dataset_dir:ebb_dataset/- path to the folder with the EBB! dataset
python test_model.pyOptional parameters:
restore_iter:None- iteration to restore (when not specified, the last saved model for level=<level>is loaded)
use_gpu:true,false- run the model on GPU or CPU
dataset_dir:ebb_dataset/- path to the folder with the EBB! dataset
models/- logs and models that are saved during the training process
models/original/- the folder with the provided pre-trained PyNET model
ebb_dataset/- the folder with the EBB! dataset
results/- visual results for image crops that are saved while training
results/full-resolution/- full-resolution image results saved during the testing
vgg-pretrained/- the folder with the pre-trained VGG-19 network
load_dataset.py- python script that loads training data
model.py- PyNET implementation (TensorFlow)
train_model.py- implementation of the training procedure
test_model.py- applying the pre-trained model to full-resolution test images and computing the numerical results
utils.py- auxiliary functions
vgg.py- loading the pre-trained vgg-19 network
Copyright (C) 2020 Andrey Ignatov. All rights reserved.
Licensed under the CC BY-NC-SA 4.0 (Attribution-NonCommercial-ShareAlike 4.0 International).
The code is released for academic research use only.
@article{ignatov2020rendering,
title={Rendering Natural Camera Bokeh Effect with Deep Learning},
author={Ignatov, Andrey and Patel, Jagruti and Timofte, Radu},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
pages={0--0},
year={2020}
}
Please contact Andrey Ignatov (andrey@vision.ee.ethz.ch) for more information