This is a data analysis writeup (as of 02/04/14) for the R Shiny application - Labor Force Statistics, built to visualize labor statistics trends over a number of variables e.g. races and genders.
The project is hosted on an AWS EC2 instance and all code and implementation is open-source and made available on Github.
- Summary
- Labor Force Trends
- Employment by Occupation
- Employment by Education
- Conclusion
- Data
- Resources
In this visualization application, we want to draw conclusions and trends about labor statistics in the US, by comparing employment and unemployment rates across races, genders, occupations, and education levels.
The original datasets are derived from the Current Population Survey (CPS) released by the Bureau of Labor Statistics. The native HTML table presentation of the data makes it difficult to visualize and derive trends.
Take a look at this:

as opposed to this:

We will delve into details on some interesting topics revolved around:
The writeup will go into detailed analysis on some of the more interesting findings in the visualization sections.
An in-depth overview on data gathering, cleaning, and transformation of the original datasets will be outlined in
the Data section.
At any time, feel free to experiment and draw your own conclusions with the interactive web application and refer to
the .R files found on the Github project site if you need details on code implementation.
(back to contents)

It appears that the US population is still growing. In addition, note that the population of women is higher than men.
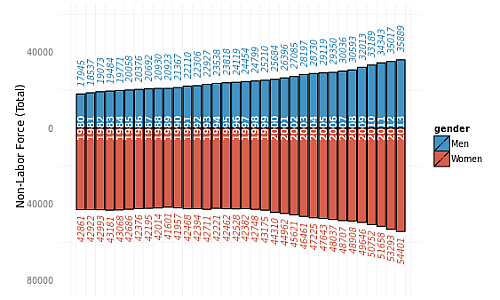
We see that a proportionately larger number of women are still not in the labor force, despite a slightly larger women population.
The next bar chart provides another view on the labor force by gender, by looking at employment rates instead of raw population headcount as displayed in the previous graph.

We observe that there has been an increase in women being employed in the labor force over time (from 47.7% in 1980 to 53.2% in 2013). This is a good sign and hopefully things continue to trend towards gender equality.
Let's take a quick look at the agriculture industry sector, where we intuitively identify manual labor being employed more readily in men than women.
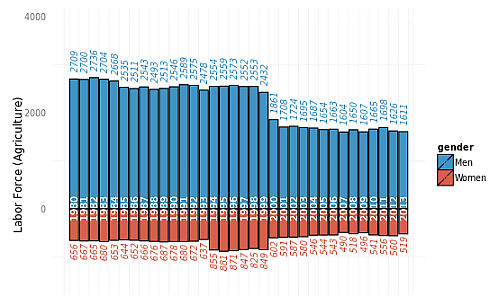
Whoa! This makes intuitive sense, but there are some other interesting questions that can be gathered from this visualization:
- Why is there a slight jump in women agriculture labor force from 1994-1999?
- Why is there a sudden decrease in agriculture labor force recent years after 2000?
These are questions that require research outside of the dataset, but I thought a few resources that I read online are potentially interesting explanations for some of the questions raised out of curiosity:
- I have not found a possible answer for this, but I'll leave it for the audience to dig into why there is a slight jump in women agriculture labor force involvement from 1994-1999.
- This maybe due to the fact that farm decline stabilized around 1997, as detailed in this USDA article, as total land for farms remained the same after a decline in overall farms (i.e. farms stabilized into larger farms, which probably consolidated equipment and labor requirements over time)
From this bar chart, we see that both men and women suffer through economic recessions.
For some interesting facts, here are some details on major recessions that occurred in the US. I'm not an expert in labor statistics, but it seems that unemployment rates straggle a few more years after the recession periods before recovery. And we seem to be experiencing some kind of recession every 10 years, although this is more of an observation and not a conclusive statement with the small dataset we are working with
- Early 1980s Recession (1981 - 1982)
- Early 1990s Recession (1990 - 1991)
- The Great Recession (2007 - 2009)
This wraps up some of the visualizations that I found interesting. Feel free to play with the webapp to discover more findings! In the next section, we will study in more detail how each race and gender group perform in various occupations and industries at certain age groups.
(back to contents)
The next facet plot visualization helps us get a quick overview on relative percentages of employed people across genders and races in various occupations and industries, sliced by age groups.

Some quick observations and comments:
- We will use percentages to convey the data instead of raw head counts, which will skew the visualization towards the White demographic.
- All percentages within a race (column) sums up to 100% in a given age group, this helps us determine the relative gender and racial distribution for each age group across occupations and industries.
- We observe that for age group 1 (16-19 years), most younger people in the labor force are engaged in Wholesale/Retail as well as Leisure Services occupations, and for age group 4 (55 years and older), most older people are engaging in Education/Health Services. This seems to make intuitive sense: younger people engage in industries that require higher energy and attention while older people fit better in less energetic industries.
- Men-dominated industries include Transportation/Utilities, Mining/Extraction, Manufacturing, and Construction, while women-dominated industries include Education/Health Services. The rest of the industry seem to have relatively equal gender distributions across all races.
Knowing that men are better suited at labor-intensive roles, we can take a closer look at the primary industry sector comprised of Transportation/Utilities, Mining/Extraction, Manufacturing, and Construction.

A few interesting things stand out:
- Most of the primary industry sector labor force is in the age group 2 and 3 (20-24 years and 25-54 years).
- We see a general trend of lower Mining/Extraction and Construction jobs in favor of Transportation/Utilities and Manufacturing jobs for the higher age groups, which makes intuitive sense as manual labor-intensive jobs are better suited for the younger population.
- There is another observation that Hispanic males are disproportionately involved in the Construction industry sector (as circled in red above, e.g. 19.9% Hispanics vs 13.6% White for age group 3)
By highlighting a specific age group (e.g. 20-24 years), and focusing on the blue columns which represent men labor force, we can see some variations among the races in the occupations they engage in.

For age group 2 (20-24 years):
- Asians are engaged more in Manufacturing.
- Blacks are engaged more in Transportation/Utilities.
- Hispanics are engaged more in Construction
- Whites are engaged slightly more evenly in Manufacturing and Construction.
In the next sections, we will take a close look at some specific industries across the dimensions of race, gender and age groups.
First up, we have the Education/Health sector, where we can obviously identify it as a women-dominated sector.

Here is a summary of the distribution across age groups in Education/Health:
- Asians have roughly equivalent distribution across age groups.
- All the other races seem to have growing distribution towards working in the Education/Health sector as the labor force gets older.
There is a clear increase of older labor force participating in the Public Administration industry sector, with roughly equal gender distributions.

A quick look at the visualization suggests that younger people (age groups 1 and 2) are more engaged in Wholesale/Retail, while the older people (age groups 3 and 4) are engaged in Professional/Business Services and Finance Services.
Gender distributions across these service sector look roughly equivalent.

This wraps up some detailed facet plot visualizations of multi-dimensional analysis of labor force statistics across industry, occupations, gender, races and age groups.
(back to contents)
We all hear the saying that getting a Bachelor's degree is necessary to finding jobs. We will take a deeper look into the dataset provided by CPS.
Here are some quick numbers of the labor force by education level attainment.

Most people in the US seem to have attained Bachelor degrees, or attended college with some associate or no degree.
When we zone in on the unemployment rates, we find an inverse correlation with educational level and unemployment rate. People holding bachelor degrees or attended college earning an associate degree have much lower unemployment rates than individuals who have not attended college or earned any degree.
Judging by the numbers, it is recommended that you should try to earn at least an associate degree in college, since the unemployment rates of graduating high school and attending college earning no degree are roughly the same.

The next section filters the results by race instead of gender.
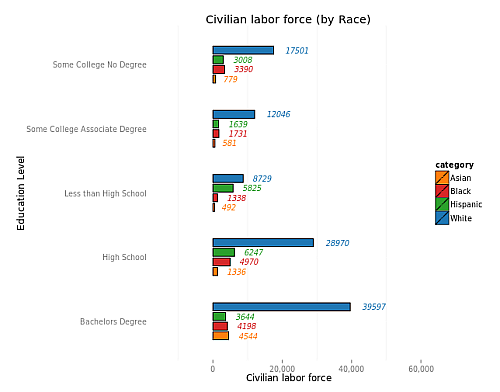
The unemployment rate trend is essentially the same as we observed in the gender overview i.e. a higher education degree confers better chances of getting a job.

However something stands out.
We see that the Black and Hispanic populations have higher unemployment rates than the other races at each education level attainment. This may or may not be due to racial discrimination, but if we made the assumption that education has delivered equal opportunities to individuals developing skills for work, then this is an area of improvement we can work on if racial discrimination exists.
(back to contents)
Despite the focus on expressing gender and racial equality statistics on labor force, I strongly believe that the topic of labor statistics should revolve around ability equality and not around gender and racial equality.
As seen in the example of agricultural jobs, women lack the natural ability to perform in this industry, and this should not be interpreted as discrimination when we evaluate people's ability to do certain work.
We need to be careful about over-emphasizing the obsession in optimizing "gender/racial-equal" numbers, which in my opinion, is another form of discrimination by overly stressing the concepts of genders and races, when our ultimate goal is to hopefully not create concepts of races and genders when we are engaging in professional evaluations of people.
Our solutions in education and government policies should be geared towards empowering individuals with equal opportunities to pursue what they want to achieve in their careers, and it is very important that pre-employment education is provided for every individual fairly, so that the true test of employment can be judged on a merit basis, instead on trying to optimize "gender/racial-equal" metrics.
In the future, it is my hope that all gender and race data in these visualizations contained can be collapsed,
providing us with a simple analysis on our labor force statistics (as shown in the bar chart below without grouping
by gender and race), one that is evaluated from all human individuals, as opposed to one evaluated based on races
and genders.

(back to contents)
This section provides details on the data source and processes that go towards scraping and munging the initial unorganized data into a consolidated R dataframe that is used in the Shiny app. We will make references to the files on the Github project.
All data is owned by the Current Population Survey (CPS) made available by the Bureau of Labor Statistics. I am not affiliated with CPS, and this writeup and application is purely for practicing and sharing thoughts behind data management and visualization.
If you are not interested in the data background and processes, feel free to jump back to the visualization sections!
We will be using the following CPS datasets:
-
cps-02: Time series of employment statistics by gender.
-
cps-14: Most recent employment statistics by industry, age, gender, and race.
-
cps-07: Most recent employment statistics by education level, gender, and race.


Careful observation of the native data presentation suggests that the data tables involve some nesting. For a general workflow with R and Shiny visualizations, we would need to collapse the data into a flat dataframe structure.
Luckily, it looks like the HTML tables themselves follow some kind of pattern. The fact that some consistent structure exists means that we can put our data munging skills to good use and transform the data into a better structure for reusable code in future programs.
But first, let's scrape the data before cleaning it up!
For the following section, we will walk through only one example of a data scraping/munging step abstracted in the
function get_labor_trend in the /data/parser.R file. We will refer the readers to dig into the other functions
in detail at their own pace (most of them are similar in construction and abstraction).
Open the /data/parser.R file and locate the get_labor_trend function.
In general, it is a good idea to build your data processing steps into multiple readable functions, so that they can be called in future applications and programs.
We will use the package XML for reading a HTML table into an R dataframe with the help of the function
readHTMLTable.
We first define the url and colnames variables, where the url points to the CPS dataset URL, and colnames is
a convenient named vector to pass both the column names and column types to the dataframe we are creating with
readHTMLTable.
url <- "http://www.bls.gov/cps/cpsaat02.htm"
colnames <- c("year" = "integer",
"Total Population" = "FormattedInteger",
"Labor Force (Total)" = "FormattedInteger",
"% Labor Force (Total)" = "numeric",
"Labor Force (Employed)" = "FormattedInteger",
"% Labor Force (Employed)" = "numeric",
"Labor Force (Agriculture)" = "FormattedInteger",
"Labor Force (Non-agriculture)" = "FormattedInteger",
"Labor Force (Unemployed)" = "FormattedInteger",
"% Labor Force (Unemployed)" = "numeric",
"Non-Labor Force (Total)" = "FormattedInteger")
tables <- readHTMLTable(url, stringsAsFactors=FALSE, colClasses=unname(colnames))The use of a named vector for
colnamesallows us to easily extract two sets of information in one variable i.e.names(colnames)extracts the names whileunname(colnames)extracts the format types of the named vectorcolnames.
We pass in stringsAsFactors=FALSE to prevent conversion of string variables into factors, which will be quite a
pain to deal with for future processes, so let's just keep to primitive data types used in common programming
languages.
By using the R-console and a couple of print statements, we learn that the variable tables is a list of HTML
tables that are found on the URL.
If you are interested, you can view the source page of the URL and check that there are indeed the same number of tables as the dimensions of our
tables.
Assuming that CPS keeps the format of their dataset/webpage in the same format, we can locate the data we want as the second table in the URL.
Let's assign this to the variable df.
df <- tables[[2]]Try printing the value ofdf.
It looks a little unstructured, despite living in a dataframe. Our goal now is to reshape the dataframe into a flat
and long format, and this is best accomplished using the great dplyr library produced by Hadley Wickham, which
beautifully abstracts common reshaping workflows in R into a concise and readable syntax and implementation
The rest of the data section assumes elementary knowledge of
dplyr. We assume familiarity with methods such as:%>%,mutate,select,arrange,rename. Please check out the officialdplyrofficial guide if you need additional resources.
With dplyr and reshape2, it's time to hack and slash!
Let's do some very basic cleaning steps to rename the columns and remove NA records (caused by nesting in the
original HTML table that produces whitespaces during the data import through readHTMLTable).
colnames(df) <- names(colnames) # rename columns
df <- df %>% na.omit() # remove NAsThe next step is to spend some time carefully observe the cps-02 dataset and its structure and patterns:
And see if we can wrangle it to, perhaps, this preferred nice, flat and long structure:

Notice that the original data structure has column headers which can be pivoted into values under a new variable
population. This will allow us to pivot and reshape the wide dataframe into a long dataframe if we pivot on the
variables year and gender.
However, there is one pesky problem.
The gender in the original data structure is located in a subtotal row. We need to find a way to populate the
"Men" and "Women" gender values in all the data records, while potentially acknowledging that the dataset
records can vary (inclusion or exclusion of years for each gender).
Our human skills of observation and pattern recognition intuitively suggests to us that this dataset contains twice
the amount of record for each gender. By observation, we also note note that the initial data is sorted by "Men",
then by "Women".
This suggests that we can generate a dynamic genders vector with number of records dependent on the size of the
dataframe itself i.e. genders=c("Men", "Men", ..., "Women", "Women"). R does this nicely for us through the use:
genders <- rep(c("Men", "Women"), each=nrow(df)/2) # create genders column to correct lengthPrint the variable genders to see for yourself, we indeed have a vector genders=c("Men", "Men", ..., "Women", "Women") that we can integrate into our dataframe df using dplyr's mutate method.
df <- df %>% mutate(gender = genders) # add gender columnThe last step for the data munging process is to pivot the dataframe from wide to long format on the variables
gender and year. This collapses all the column headers into data values under a new column variable, which we
will call population.
Reassign the "melted" dataframe to itself again, and convert the population column into a character column
(BOOOO to factors unless we absolutely need it!), and finally do some cosmetic sorting with the arrange method.
df <- melt(df, id=c("year", "gender")) %>% # melt from wide to long
rename(population = variable) %>%
mutate(population = as.character(population)) %>%
arrange(gender, population)Try printing df again:
Woohoo! This looks clean and long, just what we need for data post-processing and visualizations!
Please feel free to go over the other functions and data manipulation steps. The general idea is common across all of them, and they are summarized below.
- Abstract data gathering and processes into functions.
- Define variables, and utilize the strengths of named vectors through the R functions
namesandunname. - Load the HTML tables into dataframes initially with
readHTMLTable. - Build vectors using
rep(vector, each)by careful observation of the original data structure and desired final data structure. - Include all missing columns into the dataframe before the final pivot step to collapse the dataframe from wide
to long, with the help of
reshape2'smeltfunction.
(back to contents)
(back to contents)