Integrate PHP parser server #256
Conversation
|
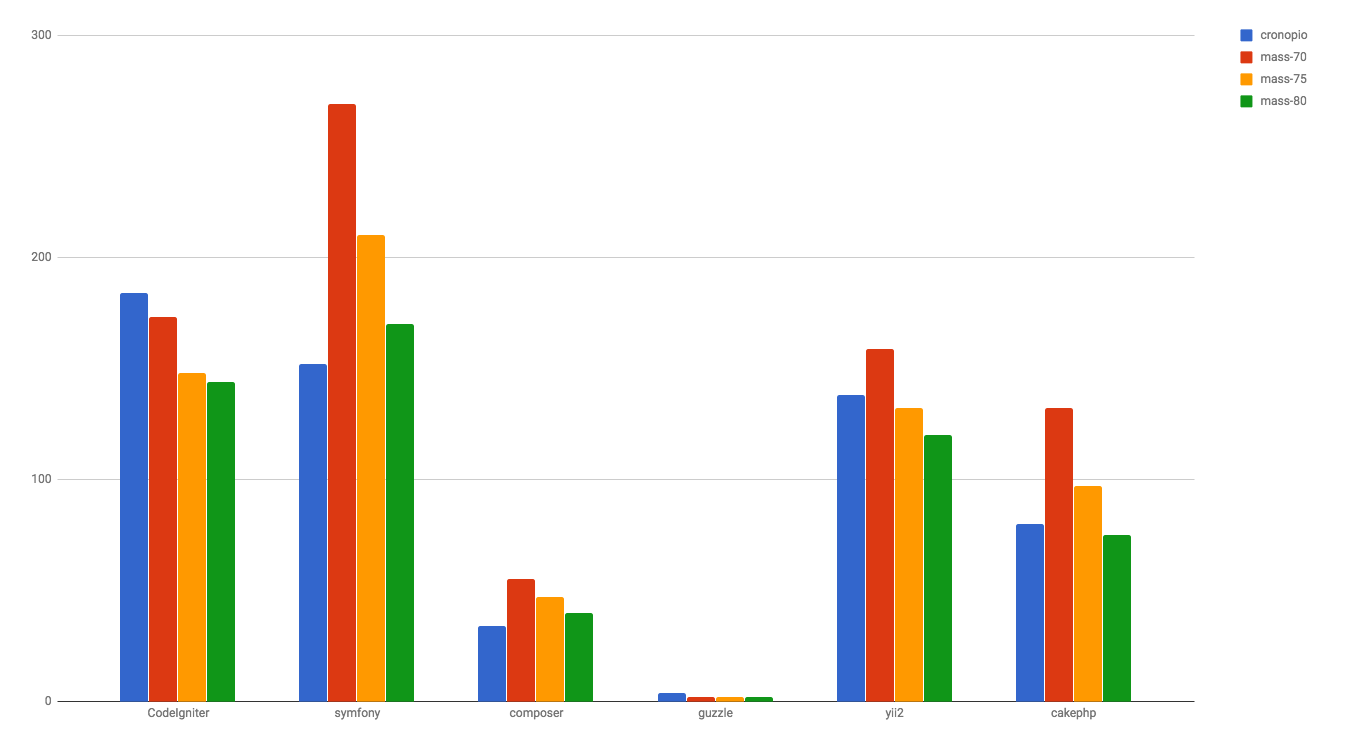
It looks like getting the threshold right is a little more art than science. I collected data from a handful of popular PHP respositories here for a few different mass thresholds in this spreadsheet. I'm thinking a value of
|
|
I'm asking Devon to review instead of me if he has time: he helped break ground on switching these languages to the parser, and I don't think I have time to effectively review this today. |
lib/cc/engine/analyzers/php/main.rb
Outdated
| ].freeze | ||
| POINTS_PER_OVERAGE = 100_000 | ||
| REQUEST_PATH = "/php" | ||
| COMMENT_MATCHER = Sexp::Matcher.parse("(_ (comments ___) ___)") |
There was a problem hiding this comment.
Is is possible to add this to DEFAULT_FILTERS instead of deleting the nodes?
There was a problem hiding this comment.
Unfortunately, it's not. That's the first thing I tried! Adding this to DEFAULT_FILTERS causes the entire function to be omitted from analysis.
There was a problem hiding this comment.
Hmmm, what about (comments ___) as a filter? Would that match just the comment instead of the entire function?
There was a problem hiding this comment.
It doesn't, please see the test output below.
I discussed this with @wfleming, too, and he said that while this is not entirely desirable behavior, this is how we originally intended filtering to work.
Failures:
1) CC::Engine::Analyzers::Php::Main#run comments ignores PHPDoc comments
Failure/Error: expect(issues.length).to be > 0
expected: > 0
got: 0
# ./spec/cc/engine/analyzers/php/main_spec.rb:232:in `block (4 levels) in <top (required)>'
# ./spec/spec_helper.rb:27:in `block (4 levels) in <top (required)>'
# ./spec/spec_helper.rb:26:in `chdir'
# ./spec/spec_helper.rb:26:in `block (3 levels) in <top (required)>'
# ./spec/spec_helper.rb:23:in `block (2 levels) in <top (required)>'
2) CC::Engine::Analyzers::Php::Main#run comments ignores one-line comments
Failure/Error: expect(issues.length).to be > 0
expected: > 0
got: 0
# ./spec/cc/engine/analyzers/php/main_spec.rb:266:in `block (4 levels) in <top (required)>'
# ./spec/spec_helper.rb:27:in `block (4 levels) in <top (required)>'
# ./spec/spec_helper.rb:26:in `chdir'
# ./spec/spec_helper.rb:26:in `block (3 levels) in <top (required)>'
# ./spec/spec_helper.rb:23:in `block (2 levels) in <top (required)>'
There was a problem hiding this comment.
while this is not entirely desirable behavior, this is how we originally intended filtering to work
Well, it's how the author of the filtering intended it to work, clearly. I'm not sure it's how "we" as in the product team intended it to work. I honestly don't know if if was what we intended or it was miscommunicated requirements & not appropriately QAed.
| }) | ||
| expect(json["remediation_points"]).to eq(900_000) | ||
| expect(json["remediation_points"]).to eq(2_200_000) |
There was a problem hiding this comment.
Should we adjust our remediation point multiplier as well so that the same duplication issues are given a similar remediation estimate?
There was a problem hiding this comment.
Ah, I didn't know there was a multiplier to adjust. I'll take a look at that. 👍
There was a problem hiding this comment.
Please see here for response!
23f109a to
5332b2a
Compare
|
@dblandin, I've adjusted the SymfonyCronopio260,400,000 total points This branch (40,000 points per overage)318,800,000 total points (+58,400,000) CodeigniterCronopio565,200,000 total points This branch (40,000 points per overage)594,360,000 total points (-29,160,000) |
Replace all the existing PHP parsing code with an integration of the PHP parser server. There are some major differences between the old and new parsers worth noting: 1. The AST is now much deeper overall. For example, an `else` branch from a unit test case has gone from 4 to 8 levels of depth. As a result, the masses have increased across the board, invalidating all `fingerprint` values and necessitating a change to the `DEFAULT_MASS_THRESHOLD` to keep the number of issues roughly consistent. 2. The AST now includes `comments` nodes, which need to be filtered out to avoid having them contribute to analysis. 3. The AST now has the correct `end` position for functions (the closing curly brace). 4. The new name for `use` statement nodes is `Stmt_Use`. Task: codeclimate/app#5898. Adjust mass threshold to 75 (for now) Points
5332b2a to
26e244d
Compare
|
Hi! I've created a new tab on the spreadsheet I've been using for analysis to expand upon the |
|
|
Includes a `POINTS_PER_OVERAGE` adjustment to 35K which unblocks this change (please see #256). Reverts the following commits from #259 (when we reverted the integration): * Use `SexpLines` for PHP parser (ef0b926) * Revert "Integrate PHP parser server" (89e795a) Original PHP parser server integration commit: 95a6d4e.
Includes a `POINTS_PER_OVERAGE` adjustment to 35K which unblocks this change (please see #256). Reverts the following commits from #259 (when we reverted the integration): * Use `SexpLines` for PHP parser (ef0b926) * Revert "Integrate PHP parser server" (89e795a) Original PHP parser server integration commit: 95a6d4e.
Replace all the existing PHP parsing code with an integration of the PHP parser server.
There are some major differences between the old and new parsers worth noting:
The AST is now much deeper overall. For example, an
elsebranch from a unit test case has gone from 4 to 8 levels of depth. As a result, the masses have increased across the board, invalidating allfingerprintvalues and necessitating a change to theDEFAULT_MASS_THRESHOLDto keep the number of issues roughly consistent.The AST now includes
commentsnodes, which need to be filtered out to avoid having them contribute to analysis.The AST now has the correct
endposition for functions (the closing curly brace).The new name for
usestatement nodes isStmt_Use.Task: codeclimate/app#5898.
TODO
DEFAULT_MASS_THRESHOLDand find bugs. While this is being reviewed, I'm going to find and test with a few more.