An experiment to build a simple RAG Application, capable of run any llamacpp-compatible LLM and any HuggingFace-compatible BERT Embedding/Sentence Transformer model. Using ChromaDB as VectorStore and Flask-SocketIO as Webserver.
- Download an LLM model according to README.md in models/ folder.
- Change config.py according to the chosen model.
- Install Docker
- Run:
- In Windows run
build_docker.batandrun_docker.bat - In Linux/Other run
sh build_docker.shandsh run_docker.sh
Screehshot
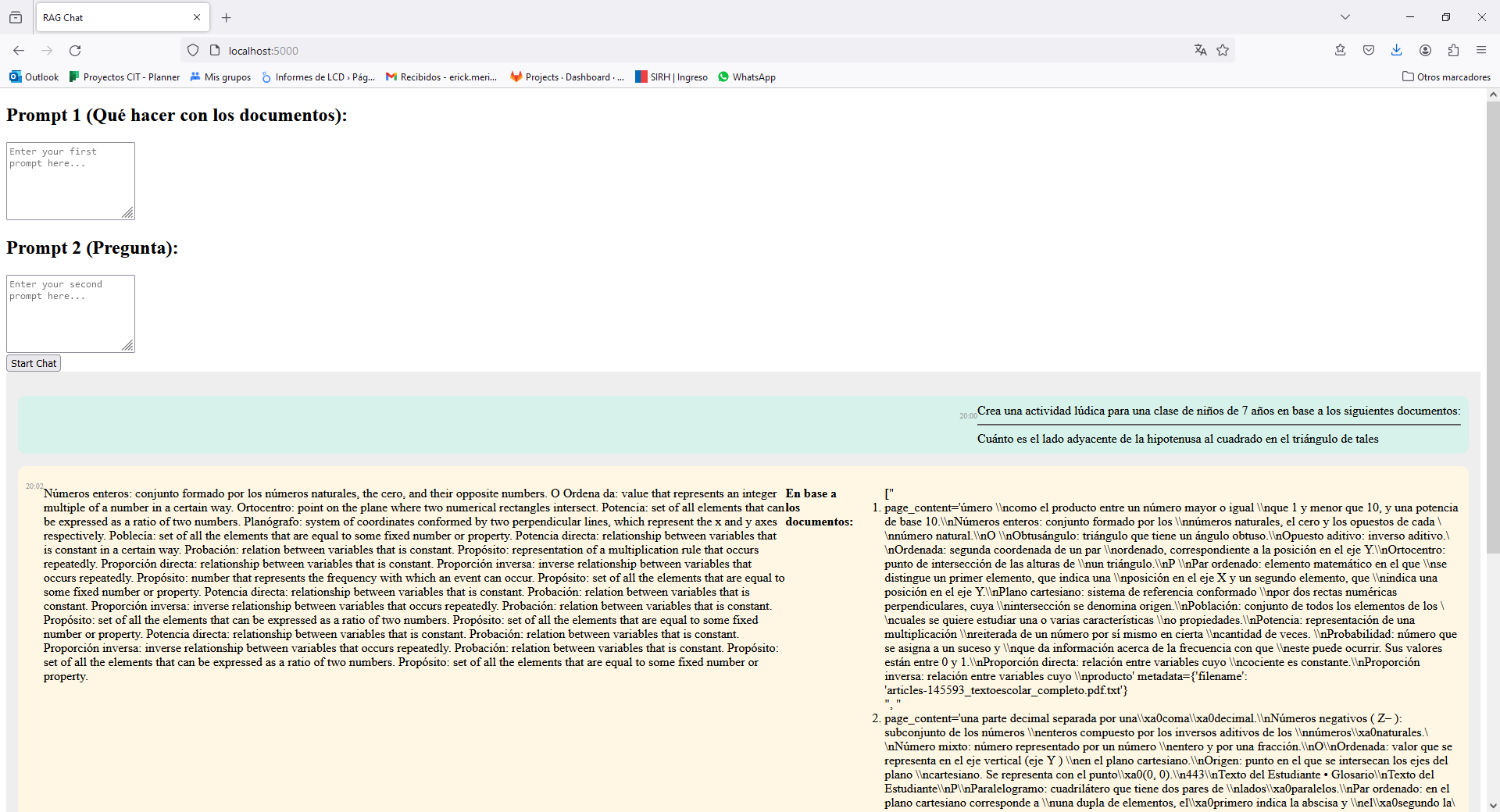
Sequence diagram of the App:

Class Diagram (without dependencies):

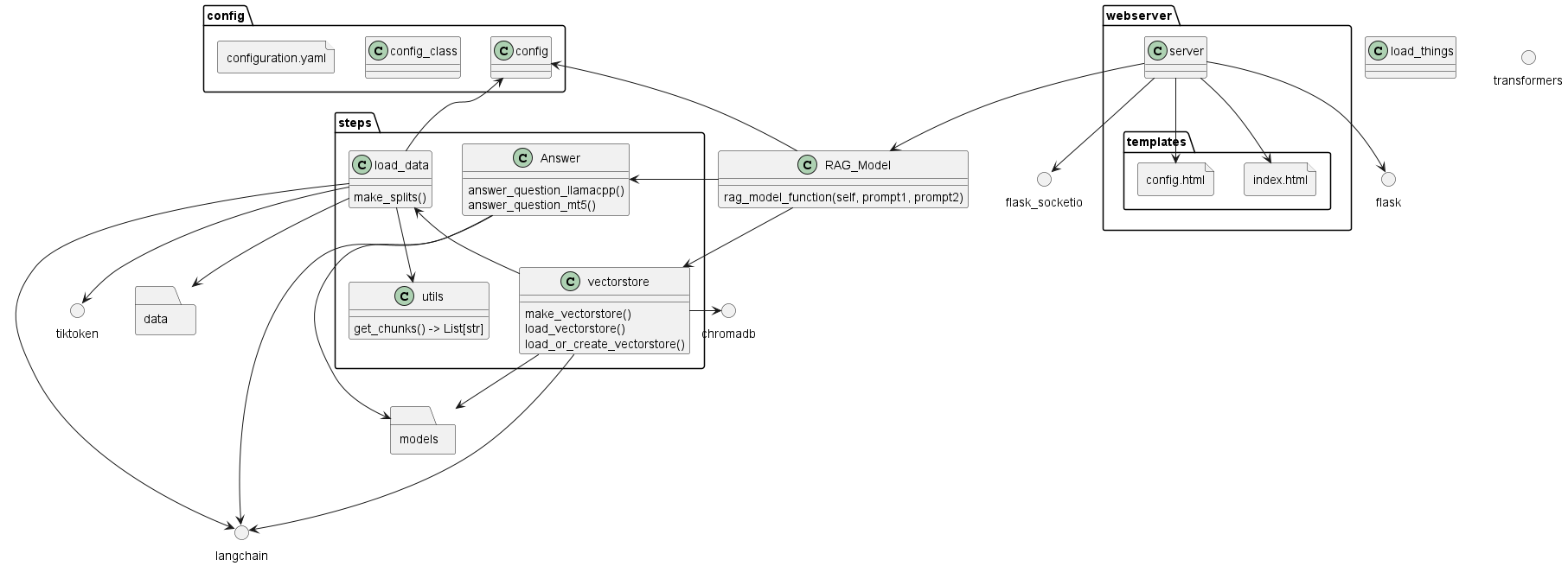
Class Diagram (with dependencies):
- Pydoc documentation
- Config HTML View
- Split Config and make a Class with Singleton
- Download LLM models automatically