A local-first Benchmark Harness for LLM agents
Stop playing script whack-a-mole with your benchmarks & start looking at reproducable results.
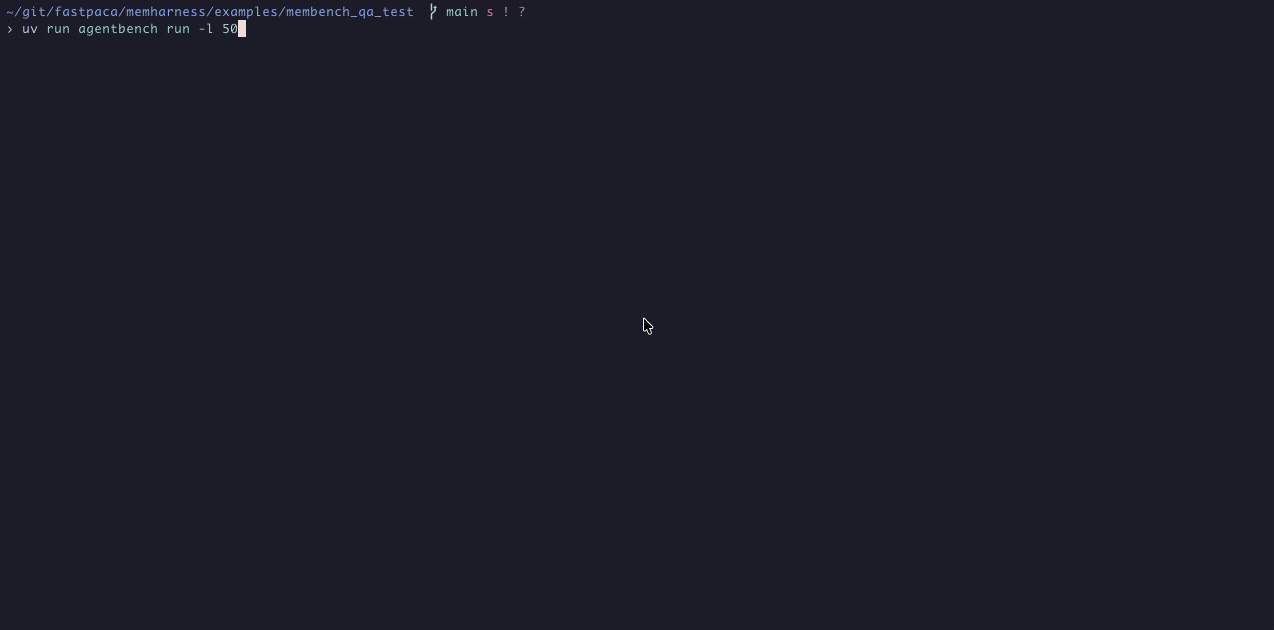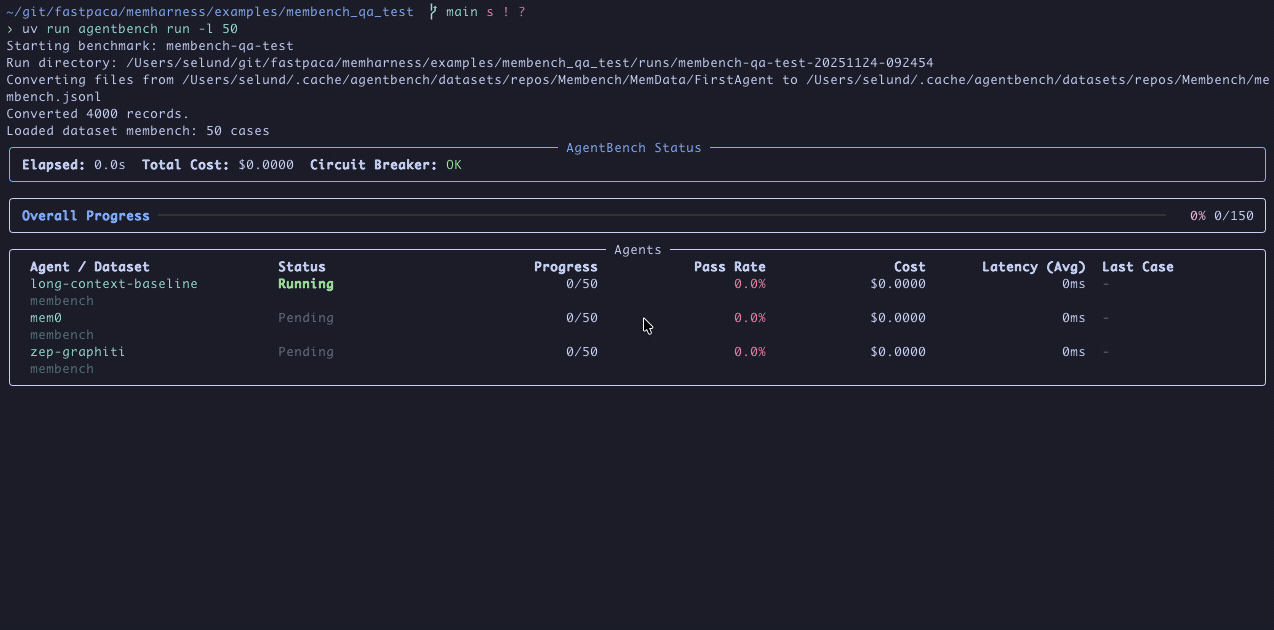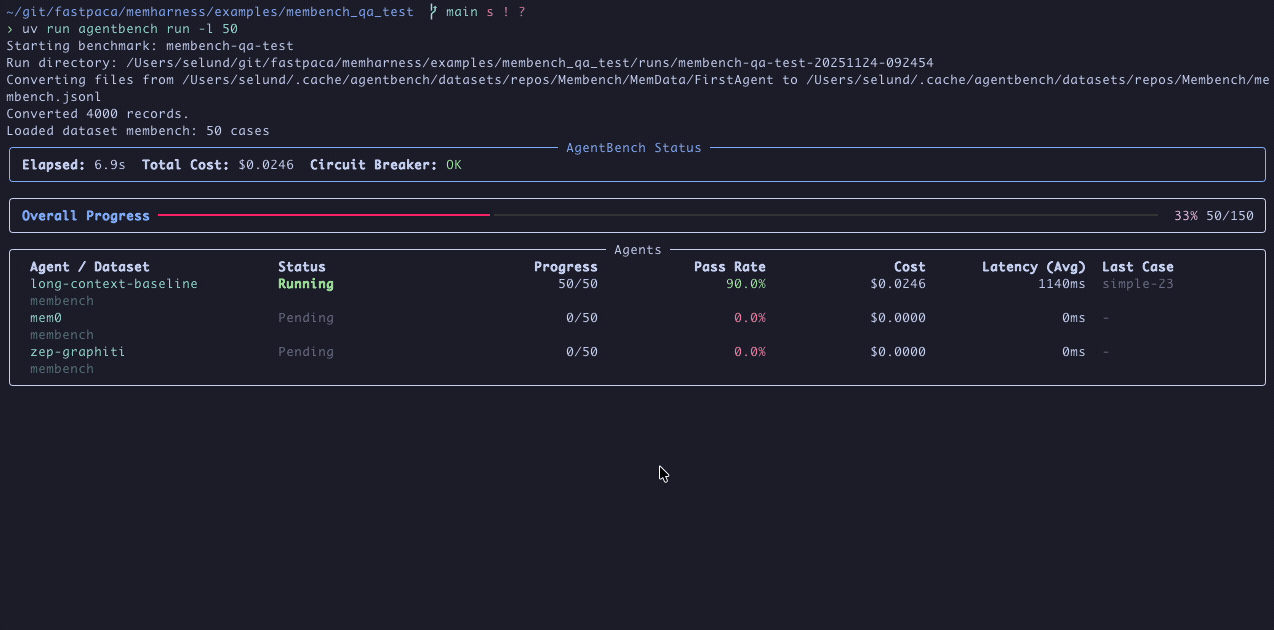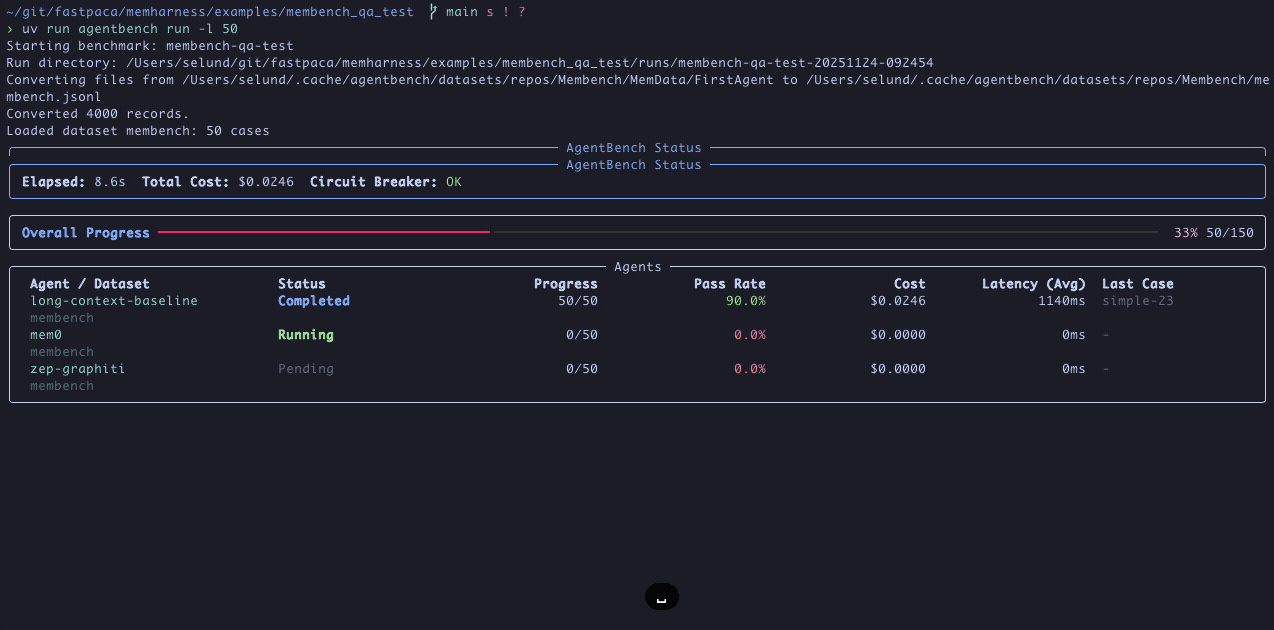
Benchmarking LLM agents should be simple. In reality it usually looks like this
- A long run fails at 13% due to an API hiccup after ~5hrs.
- You restart from scratch.
- Some cases silently succeed while others crash your scripts.
- You copy JSON blobs around trying to recover partial results and write one-off scripts to juggle it.
- You don't know how many tokens were actually used or how long responses truly took.
What should be a "start it, walk away, come back for results" evaluation turns into a multi-day slog of brittle scripts, half-finished results, and unreliable metrics.
Benchmarks shouldn't be harder than building the agent.
You don't need an enterprise platform that takes weeks to integrate. You need a tool that works.
PacaBench is a harness built for the reality of agentic LLM development. It handles the messy parts of benchmarking so you can focus on your agents.
- It doesn't crash. Agents run in isolated processes. If one crashes, the harness records the failure and keeps moving.
- It remembers where it left off. State is saved after every single case. If you kill the process or your machine restarts, you resume exactly where you stopped.
- It handles the retry loop. Run the suite, let it finish, then run
pacabench retryto target failures. - It measures reality. A built-in proxy sits between your agent and the LLM provider to track exact latency and token usage. No more guessing or relying on self-reported metrics.
Documentation | Examples | Issues
pip install pacabenchInitialize a new project:
pacabench initRun your suite:
pacabench runIf you see wonky failures, retry the failed cases:
pacabench retryView the final report:
pacabench analyzeDefine your entire benchmark in one pacabench.yaml file. Configure it once, run it forever.
name: memory-benchmark
description: Evaluating long-term memory capabilities
version: "1.0.0"
config:
concurrency: 4
timeout_seconds: 60
agents:
- name: "mem0-agent"
command: "python agents/mem0_agent.py"
env:
OPENAI_API_KEY: "${OPENAI_API_KEY}"
datasets:
- name: "membench"
source: "git:https://github.com/import-myself/Membench.git"
prepare: "python scripts/prepare_membench.py"
input_map:
input: "question"
expected: "ground_truth"
evaluator:
type: "llm_judge"
model: "gpt-4o-mini"
output:
directory: "./runs"Because you should be able to describe a benchmark, not build a bespoke system for every new test suite.
Your agent needs to read JSON from stdin and write JSON to stdout. No new SDK to learn here.
| Input (STDIN) | Output (STDOUT) |
|---|---|
{"case_id": "1", "input": "Hi"} |
{"output": "Hello!", "error": null} |
Write your agent as a hook, or straight up usage in python, golang, rust, node, whatever you fancy.
Because I was sick of my own benchmarks blowing up. I tried running serious agent benchmarks locally and kept hitting the same wall:
- Runs would fail at 60% or 20% because of one bad response.
- I ended up with script spaghetti just to get through a single dataset.
- Re-running failures meant copy/pasting JSON blobs and praying nothing broke.
- I didn’t want a heavyweight enterprise system like Arize. I wanted something that just works.
- I wanted a tool I could configure once, leave overnight, then run and re-run locally without thinking.
Benchmarking agents became a game of whack-a-mole:
run → isolate failures → rerun → inspect → repeat → rage
PacaBench exists because I wanted to stop fighting my tools and start getting actual signal from my agents.
PacaBench isolates your code from the harness.
graph LR
H[Harness] -->|1. Spawn| R[Runner Process]
R -->|2. Input JSON| A[Your Agent]
A -->|3. API Call| P[Metrics Proxy]
P -->|4. Forward| O[OpenAI/LLM Provider]
O -->|5. Response| P
P -->|6. Record Metrics| H
P -->|7. Return| A
A -->|8. Output JSON| R
R -->|9. Result| H
- Harness: Manages the run loop, persistence, and retries.
- Proxy: Intercepts API calls to provide ground-truth metrics (
OPENAI_BASE_URLinjection). - Runners: Worker processes that ensure a bad agent doesn't kill the benchmark.
- Evaluator: Flexible scoring (LLM judges, regex, F1, exact match, etc).
| Command | Description |
|---|---|
pacabench run |
Execute a benchmark run. |
pacabench retry |
Retry failed cases from a previous run. |
pacabench list-runs |
List previous runs and their status. |
pacabench analyze |
Generate a report for a specific run. |
pacabench init |
Create a new project scaffold. |
We welcome contributions. See Contributing Guidelines.
Apache 2.0 - see LICENSE