Py: refactor regex tracking to type-trackers #12552
Conversation
025b49d to
33c8069
Compare
e8ab4fe to
9423df1
Compare
There was a problem hiding this comment.
Overall LGTM, but think this could use the eyes of our local RegExp expert @yoff as well 👀
I see that we already have RegExpInterpretation in Ruby, but I don't quite feel it matches how we usually approach these things with concepts in Python. Have you considered adding it as a top-level concept next to RegexExecution? This matches pretty well what we currently do for SQLConstruction/XPathConstruction (we could even use the name RegexConstruction).
I've also been wondering if we could streamline the way flags are handled a bit. In particular, I not happy about the split between where RegexExecution is modeled, and the flags is modeled -- I found that the re_member_flags_arg doesn't have information for fullmatch which is included in the RegexExecution modeling, but it's not apparent without looking at the code side by side.
I think it would be natural to add a getFlagsArg member predicate to the RegexExecution concept (and potential RegexConstruction). This can be used when tracking the flags argument back to the modes (FindRegexMode::getAMode).
Personally I think it would make sense to expose the final mode (MULTILINE/DOTALL) they represent on the concept itself (Like we do for the tracking of mime type in the concept for HTTP responses), but I'm a little indifferent on that part 🤷
| result.asExpr() instanceof Bytes or | ||
| result.asExpr() instanceof Unicode |
There was a problem hiding this comment.
| result.asExpr() instanceof Bytes or | |
| result.asExpr() instanceof Unicode | |
| result.asExpr() instanceof StrConst |
| /** | ||
| * Gets a reference to a string that reaches any regular expression execution. | ||
| * This is the forwards exploratory phase of the analysis. | ||
| */ | ||
| private DataFlow::TypeTrackingNode forwards(DataFlow::TypeTracker t) { | ||
| t.start() and | ||
| result = backwards(DataFlow::TypeBackTracker::end()) and | ||
| result.flowsTo(strStart()) | ||
| or | ||
| exists(DataFlow::TypeTracker t2 | result = forwards(t2).track(t2, t)) and | ||
| result = backwards(_) | ||
| } |
There was a problem hiding this comment.
I don't understand why we need the forward part of the first phase.
Specifically I don't understand that part about the .flowsTo(strStart()), will the following QL ever have results? (my assumption is no, since I assume that any StrConst that can flow to a regex will also be a LocalSourceNode)
result = backwards(DataFlow::TypeBackTracker::end()) and
result.flowsTo(strStart()) and
not result = strStartThere was a problem hiding this comment.
will the following QL ever have results?
You're right, that QL will not have results.
All it means is that the flowsTo call was redundant, the code still worked.
I've refactored it a bit.
| /** | ||
| * Provides predicates that track strings to where they are used as regular expressions. | ||
| * This is implemented using TypeTracking in two phases: | ||
| * | ||
| * 1: An exploratory backwards analysis that imprecisely tracks all nodes that may be used as regular expressions. | ||
| * The exploratory phase ends with a forwards analysis from string constants that were reached by the backwards analysis. | ||
| * This is similar to the exploratory phase of the JavaScript global DataFlow library. | ||
| * | ||
| * 2: A precise type tracking analysis that tracks constant strings to where they are used as regular expressions. | ||
| * This phase keeps track of which strings and regular expressions end up in which places. | ||
| */ |
There was a problem hiding this comment.
Does this setup give better performance than the simple solution below?
private DataFlow::TypeTrackingNode regExpBacktracker(
DataFlow::TypeBackTracker t, DataFlow::Node regExpUse
) {
t.start() and
regExpUse = regSink() and
result = regExpUse.getALocalSource()
or
exists(DataFlow::TypeBackTracker t2 | result = regExpBacktracker(t2, regExpUse).backtrack(t2, t))
}
DataFlow::Node regExpSourceSimple(DataFlow::Node re) {
re = regSink() and
result = regExpBacktracker(DataFlow::TypeBackTracker::end(), re) and
result = strStart()
}There was a problem hiding this comment.
Yes. At least it did when I wrote the same thing for Ruby.
Your simple solution will have more tuples because the regExpBacktracker predicate could track many paths that never reach any string-constants.
And I the number of tuples is low in the exploratory phase because it doesn't keep track of which source/sink flow came from.
It's the same basic idea in the first phase of the global dataflow library (at least in JavaScript, I assume the shared dataflow library does some of the same).
| @@ -0,0 +1,1074 @@ | |||
| /** | |||
| * Library for parsing for Python regular expressions. | |||
There was a problem hiding this comment.
NIT
| * Library for parsing for Python regular expressions. | |
| * Library for parsing Python regular expressions. |
| DataFlow::Node use; | ||
|
|
||
| RegExp() { | ||
| (this instanceof Bytes or this instanceof Unicode) and |
There was a problem hiding this comment.
| (this instanceof Bytes or this instanceof Unicode) and | |
| this instanceof StrConst and |
| this = | ||
| API::moduleImport("re").getMember(any(string name | name != "escape")).getACall().getArg(0) |
There was a problem hiding this comment.
I was about to suggest we remove this class altogether, because RegExpInterpretation is always used together with any(Concepts::RegexExecution exec).getRegex(), but I can see that if a compiled regex is never executed , it will not become a RegexExecution 🤔 (this can also happen if our tracking of it fails to determine it reaches an execution)
So how about the following?
| this = | |
| API::moduleImport("re").getMember(any(string name | name != "escape")).getACall().getArg(0) | |
| this = | |
| API::moduleImport("re").getMember("compile").getACall().getParameter(0, "pattern").asSink() |
Also, could we move this into Stdlib.qll next to the other regex modeling?
|
Merged in main to bring in fixes for broken ql tests. |
5654493 to
538a572
Compare
|
I think I've addressed your review comments. Except for the parsing of flags, which I feel belongs in some followup work instead. |
There was a problem hiding this comment.
Nice, thanks for doing all this cleanup 👍 I think it's ok to leave the flags handling for follow up work. Do you agree that this could be a nice thing to do?
RegExpInterpretation 🚲🧃🥶
I want to do a little bit of bike-shedding around the name RegExpInterpretation, since we have RegexExecution in Concepts.qll already. I think it would be nice to have consistent naming.
After doing some research on how widely used the terms RegExp vs Regex I realized I don't really care much what it is called1. The files currently use a mix of both, so we're already in a bit of a mess. But the ReDoS libs and shared implementation around that use RegExp, so I guess we can go with that long term and phase out Regex.
If we have agreement around this, I think we should just merge this PR with current RegExp naming, and make a PR to change the name of RegexExecution.
research on regexp vs regex
I did a little reading on Regex vs. RegExp:
Seems like some languages (at least JS, Ruby, and Go) are using RegExp, while most other languages (at least C++, Python, C#, Java, Haskell, Swift) use Regex.
I also did a little google trends search, where it seems like regex is the clear winner.
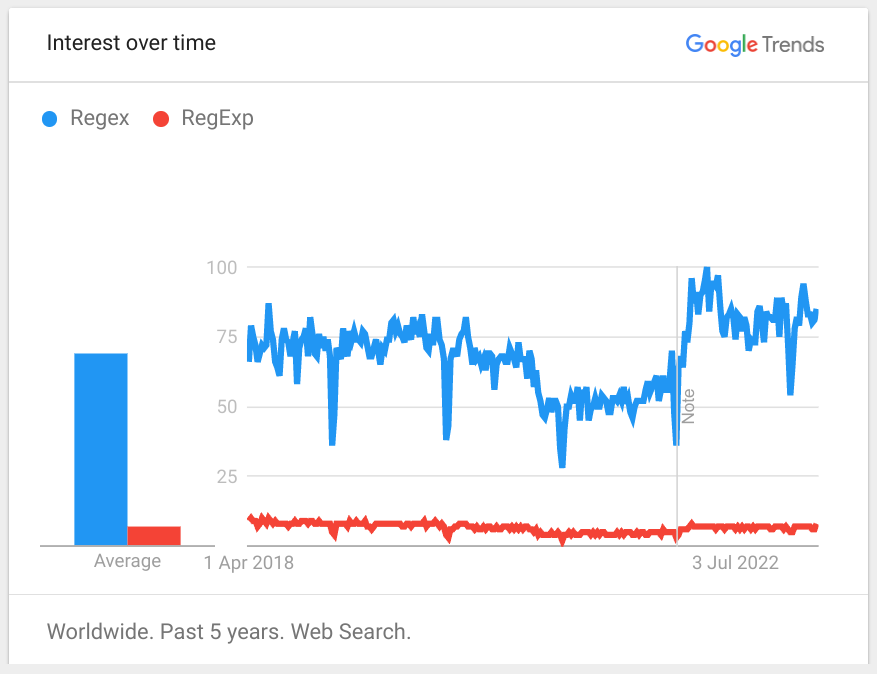
suffix
Besides the RegExp/Regex discussion, what were your thoughts on the RegexConstruction/RegExpConstruction naming? (which matches what we've done for other such cases).
Footnotes
-
although regexp is hard on my muscle memory 😂 ↩
Yes. I'm not sure what will come of it, but seems worth looking into.
Yes, JS has an build-in
Sounds like we have agreement.
I went for the suffix that Ruby had, and I think it makes sense. |
There was a problem hiding this comment.
Sorry for the long review time, I somehow found this harder to review than normal. One thing that might have helped is if moving RegexTreeView.qll and changing it had happened in two separate commits, then I would not have had to generate the diff manually (the diff turned out to be trivial, so I can see why it was tempting to do it this way).
Generally, this is great! There is one comment that I hope I have improved, because otherwise I did not understand what is going on after all :-)
| exists(DataFlow::CallCfgNode callNode | | ||
| call = callNode and | ||
| result = | ||
| mode_from_node([ | ||
| callNode | ||
| .getArg(re_member_flags_arg(callNode.(DataFlow::MethodCallNode).getMethodName())), | ||
| callNode.getArgByName("flags") | ||
| ]) |
There was a problem hiding this comment.
call is already a CallCfgNode, so introducing callNode is redundant:
| exists(DataFlow::CallCfgNode callNode | | |
| call = callNode and | |
| result = | |
| mode_from_node([ | |
| callNode | |
| .getArg(re_member_flags_arg(callNode.(DataFlow::MethodCallNode).getMethodName())), | |
| callNode.getArgByName("flags") | |
| ]) | |
| result = | |
| mode_from_node([ | |
| call | |
| .getArg(re_member_flags_arg(call.(DataFlow::MethodCallNode).getMethodName())), | |
| call.getArgByName("flags") | |
| ]) |
| private DataFlow::Node sink; | ||
|
|
||
| RegExpPatternSource() { astNode = this.asExpr() } | ||
| RegExpPatternSource() { this = regExpSource(sink) } |
There was a problem hiding this comment.
I am tempted to turn the predicate RegExpSource::regSink into the charpred of a class, just so I could annotate the result type of RexExpSource::regExpSource with it. Then we could see it here as:
private RegExpSink sink;
RegExpPatternSource() { this = regExpSource(sink) }
(where I imagine the class was called RegExpSink). I think this might clarify the constraints on sink a little bit.
| private string getUnicode() { | ||
| result = Numbers::parseHexInt(this.getText().suffix(2)).toUnicode() | ||
| } |
There was a problem hiding this comment.
This qldoc seems to have gotten lost during the move
| private string getUnicode() { | |
| result = Numbers::parseHexInt(this.getText().suffix(2)).toUnicode() | |
| } | |
| /** | |
| * Gets the unicode char for this escape. | |
| * E.g. for `\u0061` this returns "a". | |
| */ | |
| private string getUnicode() { | |
| result = Numbers::parseHexInt(this.getText().suffix(2)).toUnicode() | |
| } |
| * A node that is not a regular expression literal, but is used in places that | ||
| * may interpret it as one. Instances of this class are typically strings that | ||
| * flow to method calls like `re.compile`. |
There was a problem hiding this comment.
I find it confusing that this talks about strings that flow to places. Is the point of this refactor not, that this concept only includes those places (where strings are being interpreted as regular expressions)?
The definition of regSink suggest that we do tracking based on the RegExpInterpretation concept among other things.
Also, I think we do not have regular expression literals in Python.
| * A node that is not a regular expression literal, but is used in places that | |
| * may interpret it as one. Instances of this class are typically strings that | |
| * flow to method calls like `re.compile`. | |
| * A node where a string is interpreted as a regular expression, | |
| * for instance an argument to `re.compile`. |
There was a problem hiding this comment.
Yes, your comment is better, and yes the concept only includes the places where a string is interpreted as a regular expression.
Also, I think we do not have regular expression literals in Python.
Too much copy-paste from my end.
| * A node that is not a regular expression literal, but is used in places that | ||
| * may interpret it as one. Instances of this class are typically strings that | ||
| * flow to method calls like `re.compile`. |
There was a problem hiding this comment.
If we change the above, we should remember to change this also.
| * A node that is not a regular expression literal, but is used in places that | |
| * may interpret it as one. Instances of this class are typically strings that | |
| * flow to method calls like `re.compile`. | |
| * A node where a string is interpreted as a regular expression, | |
| * for instance an argument to `re.compile`. |
…TreeView.qll into a regexp folder
…use the rest is handled by RegexExecution
b319a8b to
d5029c9
Compare
|
I did a rebase on |
|
I wonder if the last commit could be avoided, had we not changed the result type of |
It could have been avoided. |
Two main things are happening in this PR.
1: Use type-tracking instead of global dataflow to track string constants to where they are used as regular expressions .
A similar change in Ruby improved performance A LOT: #11879
But the library is simpler here for two reasons: no regex literals, and less implicit regex executions.
2: Refactor lots of code, split code into more files, rename some concepts, and thereby make the structure very similar to Ruby.
I figured out things a bit as I went, and that shows in the commits.
There are ugly hacks and TODO comments along the way, but each commit should work on their own.
I did not like the
RegexStringinterface.A natural separation of responsibilities is that the library models are responsible for saying which values are interpreted as regular expressions. But with
RegexStringthey instead had to specify which string-constants are regular expressions.And with that interface it's very hard to get tracking of string-constants to where they are used as regular expressions (unless implemented manually in each library model).
Also, the difference between
RegexStringandRegexwas very confusing with the previous API.I've replaced it with
RegExpInterpretation(taken from Ruby), where the library models are instead responsible for specifying which dataflow-nodes are used as regular expressions, and we get tracking of constants to regular expressions for free.This also allowed for a much cleaner implementation in
RegExpTracking.qll(see theregSinkpredicate).Evaluation looks OK. 2% gained performance on code-scanning in this evaluation.
Two lost results, and they could be re-gained from adding array-related steps to type-tracking.