C++: isChiForAllAliasedMemory recursion through inexact Phi operands
#2917
Conversation
… inexact PhiInstructions
|
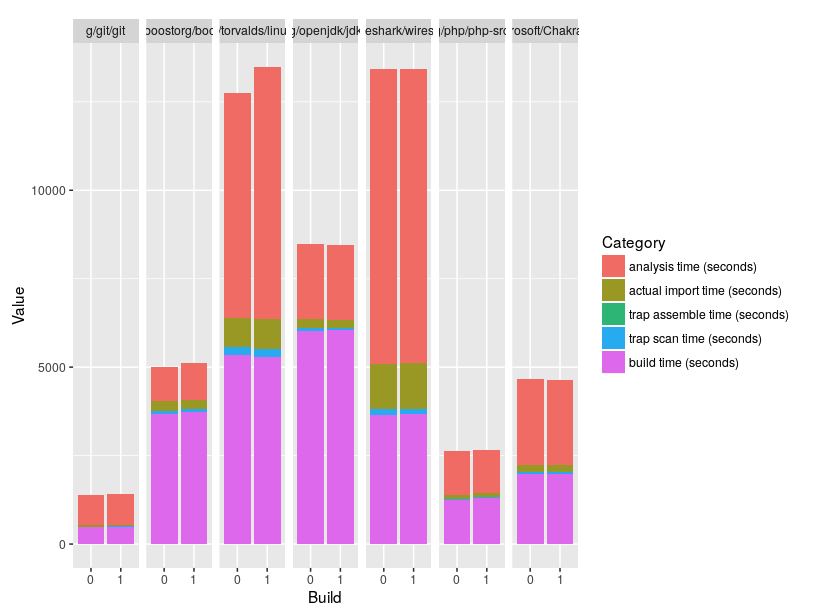
I don't expect crazy performance changes, but I've started a CPP-difference run to be sure: https://jenkins.internal.semmle.com/job/Changes/job/CPP-Differences/863/ |
|
I'm not exactly sure why
|
|
The Linux performance regression looks bad enough that it needs to be investigated. I'll be surprised if it's caused by the number of tuples in the modified predicate -- it's practically impossible for a unary linear predicate to be slow unless there's a bad join order inside it. |
I'll take a look at it later today then. |
|
Removing the |
|
We've failed to isolate the performance bug. It doesn't seem to be connected to this PR in any meaningful way even though it's somehow triggered by it. See https://github.slack.com/archives/CP0LHP150/p1583231417117500. |
On some projects (notably
git/git) it can happen that aPhiInstructionhas inexact operands (See https://github.com/github/codeql-c-analysis-team/issues/30):This causes
isChiForAllAliasedMemoryto fail because it expects theChichain to have exact operands forPhiInstructions.The real fix is most likely to avoid this situation altogether, but this easy workaround PR modifies the definition of
isChiForAllAliasedMemoryto allow recursion through inexactPhiInstructionoperands. I haven't observed any need to modify the case forChiInstructions, so I'll leave that one to only recurse through exact operands.