cmd/asm: refactor the framework of the arm64 assembler #44734
Description
I propose to refactor the framework of the arm64 assembler.
Why ?
1, The current framework is a bit complicated, not easy to understand, maintain and extend. Especially the handling of constants and the design of optab.
2, Adding a new arm64 instruction is taking more and more effort. For some complex instructions with many formats, a lot of modifications are needed. For example, https://go-review.googlesource.com/c/go/+/273668, https://go-review.googlesource.com/c/go/+/233277, etc.
3, At the moment, we are still missing ~1000 assembly instructions, including NEON and SVE. The potential cost for adding those instructions are high.
People is paying more and more attention to arm64 platform, and there are more and more requests to add new instructions, see #40725, #42326, #41092 etc. Arm64 also has many new features, such as SVE. We hope to construct a better framework to solve the above problems and make future work easier.
Goals for the changes
1, More readable and easy to maintain.
2, Easy to add new instructions.
3, Friendly to testing, Can be cross checked with GNU tools.
4, Share instruction definition with disassembly to avoid mismatch between assembler and disassembler.
How to refactor ?
First let's take a look of the current framework.
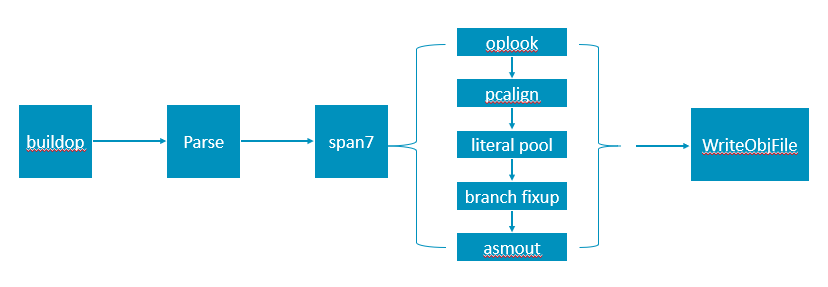
We mainly focus on the span7 function which encodes a function's Prog list. The main idea of this function is that for a specific Prog, first find its corresponding item in optab (by oplook function), and then encode it according to optab._type (in asmout function).
In oplook, we need to handle the matching relationship between a Prog and an optab item, which is quite complex especially those constant types and constant offset types. In optab, each format of an instruction has an entry. In theory, we need to write an encoding function for each entry, fortunately we can reuse some similar cases. However sometimes we don't know whether there is a similar implementation, and as instructions increase, the code becomes more and more complex and difficult to maintain.
We propose to change this logic to: separate the preprocessing and encoding of a Prog. The specific method is to first unfold the Prog into a Prog corresponding to only one machine instruction (by hardcode), and then encode it according to the known bits and argument types. Namely: encoding_of_P = Known_bits | arg1 | arg2 | ... | argn
The control flow of span7 becomes:
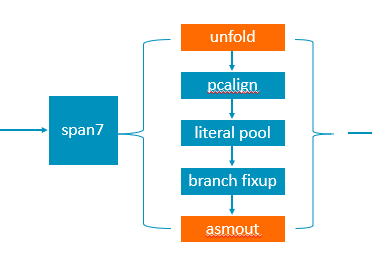
We basically have a complete argument type description list and arm64 instruction table, see argument types and instruction table When we know the known bits and parameter types of an instruction, it is easy to encode it.
With this change, we don't need to handle the matching relationship between the Prog and the item of optab any more, and we won't encode a specific instruction but the instruction argument type. The number of the instruction argument type is much less than the instruction number, so theoretically the reusability will increase and complexity will decrease. In the future to add new instructions we only need to do this:
1, Set an index to the goal instruction in the arm64 instruction table.
2, Unfold a Prog to one or multiple arm64 instructions.
3, Encode the parameters of the arm64 instruction if they have not been implemented.
I have a prototype patch for this proposal, including the complete framework and support for a few instructions such as ADD, SUB, MOV, LDR and STR. See https://go-review.googlesource.com/c/go/+/297776. The patch is incomplete, more work is required to make it work. If the proposal is accepted, we are committed to taking charge of the work.
TODO list:
1, Enable more instructions.
2, Add more tests.
3, Fix the assembly printing issue.
4, Cross check with GNU tools.