runtime: investigate possible Go scheduler improvements inspired by Linux Kernel's CFS #51071
Description
First, please let me pay tribute to your contributions. You guys are awesome! And Go is so marvelous!
It has been more than ten years, and Go has already been very successful. So, I think it is time to give Go a better scheduler -- maybe like the CFS scheduler of Linux kernel.
The current implementation of the scheduling strategy of the Go runtime scheduler is basically Round-Robin scheduling. But in practical application scenarios, priority relationships may need to exist between different types of tasks or even between tasks of the same type. For example, if we want to use Go to implement a storage engine, in general, I/O tasks should have higher priority than any other CPU intensive tasks. Because in this case, the system bottleneck is more likely to be in disk I/O, not CPU. For another example, we may use Go to implement a network service, which is required to ensure the latency of some certain lightweight tasks even while other goroutines are quite CPU intensive. However, in the current implementation of Go runtime, if there are a certain number of CPU intensive tasks that need to run for a long time, it will inevitably impact the scheduling latency. Therefore, we need a real mature Go scheduler like the CFS scheduler in kernel.
From another perspective, we could compare the thread model provided by kernel with the goroutine model provided by Go. In addition to the inherent low-cost and high-concurrency advantages of goroutine over threads, some very useful mechanisms in the kernel thread model cannot be found in the goroutine model of Go, at least not yet. For example, dynamic modification of scheduling policy and priority mechanism including adaptive priority adjustment.
The scheduler of the initial versions of Linux kernel, e.g. v0.01, is quite primitive. But with the continuous development of the kernel, more and more applications have higher and higher requirements for schedulers, and the kernel scheduler has been keeping evolving until today's CFS scheduler.
That should also apply to Go. A real mature scheduler will make Go even greater.
I have already developed a customized scheduler over Go runtime as a demo and which proves my proposal is feasible and such scheduler would benefit many applications which have high requirements from the perspective of latency and throughput.
Terminology
Event intensive task: Most of the time in its life cycle is waiting for events (just name it off CPU), and only a very small part of the time is doing CPU computing.
CPU intensive task: Most of or even all of its life cycle is doing CPU computing (just name it on CPU), and only a very small part of its time or has never been in the state of waiting for events.
Description
Basically, the idea of CFS scheduling is to give every thread a logical clock which records the duration of thread's on-cpu time. Different priority settings of threads, different speed time passes of its logical clock. And CFS scheduler would prefer to choose the thread which has the most behind logical clock to run. Because the scheduler thinks it is quite unfair to make such thread even more behind. After all, the scheduler's name CFS stands for Completely Fair Scheduler. So, if one thread is event intensive, then it would have a higher de facto priority. And if one thread is cpu intensive, then it would have a lower de facto priority. That we could call it adaptive priority adjustment. That is a quite important feature which could ensure the scheduling latency of event intensive threads will not be very high even current system is under high cpu load due to the existence of some cpu intensive threads.
Although this demo only implements some part of CFS scheduling, the result is quite promising.
Demo
package main
import (
"crypto/rand"
"fmt"
"hash/crc32"
"log"
_ "net/http/pprof"
mathrand "math/rand"
"net/http"
"runtime"
"time"
"github.com/hnes/cpuworker"
)
var glCrc32bs = make([]byte, 1024*256)
func cpuIntensiveTask(amt int) uint32 {
var ck uint32
for range make([]struct{}, amt) {
ck = crc32.ChecksumIEEE(glCrc32bs)
}
return ck
}
func cpuIntensiveTaskWithCheckpoint(amt int, checkpointFp func()) uint32 {
var ck uint32
for range make([]struct{}, amt) {
ck = crc32.ChecksumIEEE(glCrc32bs)
checkpointFp()
}
return ck
}
func handleChecksumWithCpuWorkerAndHasCheckpoint(w http.ResponseWriter, _ *http.Request) {
ts := time.Now()
var ck uint32
cpuworker.Submit1(func(checkpointFp func()) {
ck = cpuIntensiveTaskWithCheckpoint(10000+mathrand.Intn(10000), checkpointFp)
}).Sync()
w.Write([]byte(fmt.Sprintln("crc32 (with cpuworker and checkpoint):", ck, "time cost:", time.Now().Sub(ts))))
}
func handleChecksumSmallTaskWithCpuWorker(w http.ResponseWriter, _ *http.Request) {
ts := time.Now()
var ck uint32
cpuworker.Submit(func() {
ck = cpuIntensiveTask(10)
}).Sync()
w.Write([]byte(fmt.Sprintln("crc32 (with cpuworker and small task):", ck, "time cost:", time.Now().Sub(ts))))
}
func handleChecksumWithoutCpuWorker(w http.ResponseWriter, _ *http.Request) {
ts := time.Now()
var ck uint32
ck = cpuIntensiveTask(10000 + mathrand.Intn(10000))
w.Write([]byte(fmt.Sprintln("crc32 (without cpuworker):", ck, "time cost:", time.Now().Sub(ts))))
}
func handleDelay(w http.ResponseWriter, _ *http.Request) {
t0 := time.Now()
wCh := make(chan struct{})
go func() {
time.Sleep(time.Millisecond)
wCh <- struct{}{}
}()
<-wCh
w.Write([]byte(fmt.Sprintf("delayed 1ms, time cost %s :)\n", time.Now().Sub(t0))))
}
func main() {
rand.Read(glCrc32bs)
nCPU := runtime.GOMAXPROCS(0)
cpuP := cpuworker.GetGlobalWorkers().GetMaxP()
fmt.Println("GOMAXPROCS:", nCPU, "DefaultMaxTimeSlice:", cpuworker.DefaultMaxTimeSlice,
"cpuWorkerMaxP:", cpuP, "length of crc32 bs:", len(glCrc32bs))
http.HandleFunc("/checksumWithCpuWorker", handleChecksumWithCpuWorkerAndHasCheckpoint)
http.HandleFunc("/checksumSmallTaskWithCpuWorker", handleChecksumSmallTaskWithCpuWorker)
http.HandleFunc("/checksumWithoutCpuWorker", handleChecksumWithoutCpuWorker)
http.HandleFunc("/delay1ms", handleDelay)
log.Fatal(http.ListenAndServe(":8080", nil))
}The server cpuworker/example/demo.go is running at an aws instance c5d.12xlarge and with the env GOMAXPROCS set to 16.
$ GOMAXPROCS=16 ./cpuworker-demo
GOMAXPROCS: 16 cpuWorkerMaxP: 12 length of crc32 bs: 262144The benchmark tool is running at an aws instance c5d.4xlarge. The two machines is running at the same cluster placement group.
# please complete the server IP
SeverIP=x.x.x.x
# cmd 1
while true; do sleep 1;ab -s10000000 -c 100 -n 60000 http://$SeverIP:8080/delay1ms; done
# cmd 2
while true; do sleep 1;ab -s10000000 -c 100 -n 10000 http://$SeverIP:8080/checksumWithoutCpuWorker; done
# cmd 3
while true; do sleep 1;ab -s10000000 -c 100 -n 10000 http://$SeverIP:8080/checksumWithCpuWorker; done
# cmd 4
while true; do sleep 1;ab -s10000000 -c 100 -n 10000 http://$SeverIP:8080/checksumSmallTaskWithCpuWorker; doneStep 1: Killall already existing cmd x, then run the cmd 1 (run the standalone benchmark of delay1ms).
$ ab -s10000000 -c 100 -n 60000 http://$SeverIP:8080/delay1ms
This is ApacheBench, Version 2.3 <$Revision: 1879490 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 172.31.47.63 (be patient)
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
Completed 10000 requests
Finished 10000 requests
Server Software:
Server Hostname: 172.31.47.63
Server Port: 8080
Document Path: /delay1ms
Document Length: 37 bytes
Concurrency Level: 100
Time taken for tests: 0.225 seconds
Complete requests: 10000
Failed requests: 1066
(Connect: 0, Receive: 0, Length: 1066, Exceptions: 0)
Total transferred: 1538813 bytes
HTML transferred: 368813 bytes
Requests per second: 44413.06 [#/sec] (mean)
Time per request: 2.252 [ms] (mean)
Time per request: 0.023 [ms] (mean, across all concurrent requests)
Transfer rate: 6674.16 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.2 0 1
Processing: 1 2 0.4 2 4
Waiting: 1 2 0.4 1 4
Total: 1 2 0.5 2 5
ERROR: The median and mean for the waiting time are more than twice the standard
deviation apart. These results are NOT reliable.
Percentage of the requests served within a certain time (ms)
50% 2
66% 2
75% 2
80% 2
90% 3
95% 3
98% 4
99% 4
100% 5 (longest request)Step 2: Killall already existing cmd x, then run the cmd 1 and cmd 2 simultaneously (run the benchmark of delay1ms with a very heavy cpu load which is scheduled by the original Go scheduler).
Current CPU load of the server-side (and please note that the load average is already reaching the GOMAXPROCS, i.e. 16 in this case):
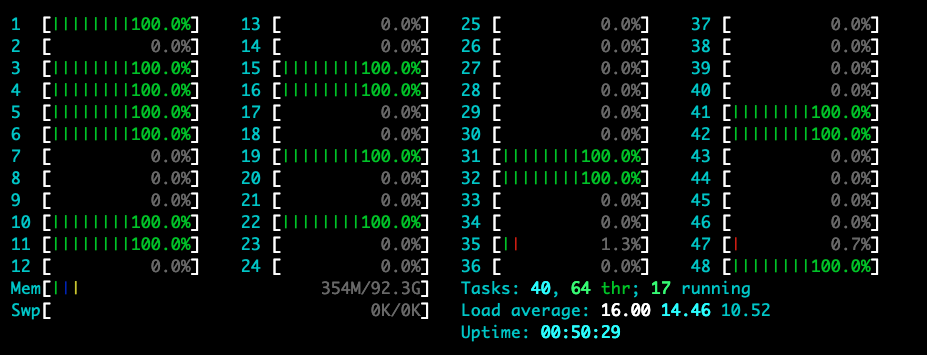
$ ab -s10000000 -c 100 -n 60000 http://$SeverIP:8080/delay1ms
This is ApacheBench, Version 2.3 <$Revision: 1879490 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 172.31.47.63 (be patient)
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
Completed 10000 requests
Finished 10000 requests
Server Software:
Server Hostname: 172.31.47.63
Server Port: 8080
Document Path: /delay1ms
Document Length: 38 bytes
Concurrency Level: 100
Time taken for tests: 31.565 seconds
Complete requests: 10000
Failed requests: 5266
(Connect: 0, Receive: 0, Length: 5266, Exceptions: 0)
Total transferred: 1553977 bytes
HTML transferred: 383977 bytes
Requests per second: 316.80 [#/sec] (mean)
Time per request: 315.654 [ms] (mean)
Time per request: 3.157 [ms] (mean, across all concurrent requests)
Transfer rate: 48.08 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.1 0 1
Processing: 50 314 99.3 293 1038
Waiting: 11 305 102.5 292 1038
Total: 50 314 99.3 293 1038
Percentage of the requests served within a certain time (ms)
50% 293
66% 323
75% 353
80% 380
90% 454
95% 504
98% 604
99% 615
100% 1038 (longest request)As we can see, the latency becomes very high and unstable.
Step 3: Killall already existing cmd x, then run the cmd 1 and cmd 3 simultaneously (run the benchmark of delay1ms with a very heavy cpu load which is scheduled by our own scheduler over the original Go scheduler).
Current CPU load of the server-side (and please note that the load average is near the cpuWorkerMaxP, i.e. 12 in this case, and you could set this parameter by yourself):
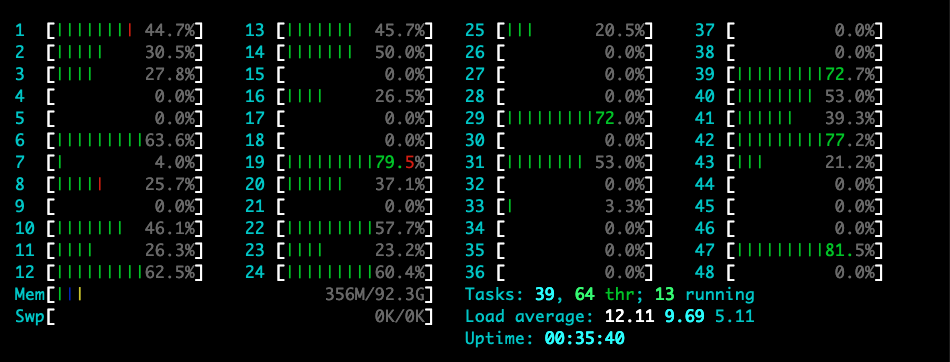
$ ab -s10000000 -c 100 -n 60000 http://$SeverIP:8080/delay1ms
This is ApacheBench, Version 2.3 <$Revision: 1879490 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 172.31.47.63 (be patient)
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
Completed 10000 requests
Finished 10000 requests
Server Software:
Server Hostname: 172.31.47.63
Server Port: 8080
Document Path: /delay1ms
Document Length: 37 bytes
Concurrency Level: 100
Time taken for tests: 0.234 seconds
Complete requests: 10000
Failed requests: 1005
(Connect: 0, Receive: 0, Length: 1005, Exceptions: 0)
Total transferred: 1538877 bytes
HTML transferred: 368877 bytes
Requests per second: 42655.75 [#/sec] (mean)
Time per request: 2.344 [ms] (mean)
Time per request: 0.023 [ms] (mean, across all concurrent requests)
Transfer rate: 6410.35 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.2 0 1
Processing: 1 2 0.5 2 4
Waiting: 1 2 0.4 2 4
Total: 1 2 0.5 2 5
Percentage of the requests served within a certain time (ms)
50% 2
66% 2
75% 2
80% 3
90% 3
95% 4
98% 4
99% 4
100% 5 (longest request)Now the latency becomes fine again even it is running with many CPU intensive tasks!
Step 4: Killall already existing cmd x, then run the cmd 1, cmd 3, and cmd 4 simultaneously (run the benchmark of delay1ms and checksumSmallTaskWithCpuWorker with a very heavy cpu load which is scheduled by our own scheduler over the original Go scheduler).
Current CPU load of the server-side (and please note that the load average is near the cpuWorkerMaxP, i.e. 12 in this case, and you could set this parameter by yourself):
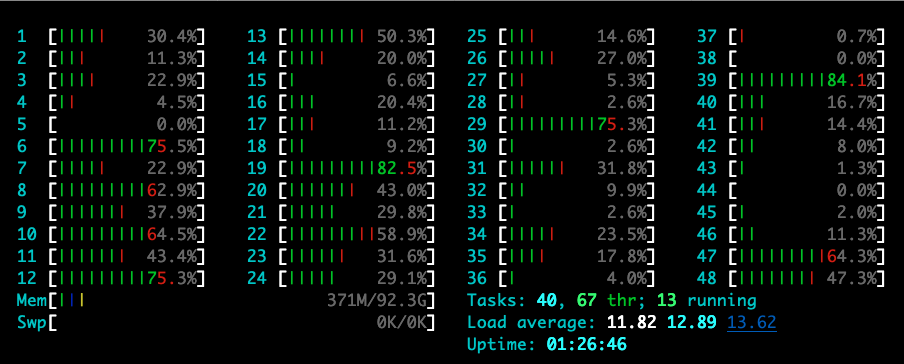
$ ab -s10000000 -c 100 -n 60000 http://$SeverIP:8080/delay1ms
This is ApacheBench, Version 2.3 <$Revision: 1879490 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 172.31.47.63 (be patient)
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
Completed 10000 requests
Finished 10000 requests
Server Software:
Server Hostname: 172.31.47.63
Server Port: 8080
Document Path: /delay1ms
Document Length: 37 bytes
Concurrency Level: 100
Time taken for tests: 0.238 seconds
Complete requests: 10000
Failed requests: 1038
(Connect: 0, Receive: 0, Length: 1038, Exceptions: 0)
Total transferred: 1538857 bytes
HTML transferred: 368857 bytes
Requests per second: 42031.11 [#/sec] (mean)
Time per request: 2.379 [ms] (mean)
Time per request: 0.024 [ms] (mean, across all concurrent requests)
Transfer rate: 6316.39 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.2 0 1
Processing: 1 2 0.5 2 5
Waiting: 1 2 0.4 1 5
Total: 1 2 0.6 2 5
ERROR: The median and mean for the waiting time are more than twice the standard
deviation apart. These results are NOT reliable.
Percentage of the requests served within a certain time (ms)
50% 2
66% 2
75% 2
80% 3
90% 3
95% 4
98% 4
99% 4
100% 5 (longest request)
$ ab -s10000000 -c 100 -n 10000 http://$SeverIP:8080/checksumSmallTaskWithCpuWorker
This is ApacheBench, Version 2.3 <$Revision: 1879490 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 172.31.47.63 (be patient)
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
Completed 10000 requests
Finished 10000 requests
Server Software:
Server Hostname: 172.31.47.63
Server Port: 8080
Document Path: /checksumSmallTaskWithCpuWorker
Document Length: 71 bytes
Concurrency Level: 100
Time taken for tests: 0.469 seconds
Complete requests: 10000
Failed requests: 9157
(Connect: 0, Receive: 0, Length: 9157, Exceptions: 0)
Total transferred: 1889624 bytes
HTML transferred: 719624 bytes
Requests per second: 21333.56 [#/sec] (mean)
Time per request: 4.687 [ms] (mean)
Time per request: 0.047 [ms] (mean, across all concurrent requests)
Transfer rate: 3936.76 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.3 0 2
Processing: 1 4 3.3 3 13
Waiting: 1 4 3.3 3 13
Total: 2 5 3.4 3 13
Percentage of the requests served within a certain time (ms)
50% 3
66% 4
75% 6
80% 9
90% 11
95% 11
98% 12
99% 12
100% 13 (longest request)The latency of both of them are fine :-)
This demonstration is only to prove that this proposal is feasible and will have obvious benefits to those applications which cares about latency. Moreover, for many applications, throughput is directly affected by latency, so this proposal can also optimize the throughput of those applications
Proposal
Option 1: Bring Go a better scheduler just like Linux Kernel's CFS Scheduler. Support adaptive priority adjustment. Goroutine Setpriority like syscall.Setpriority could also be supported which only influences the speed time passes of the logical clock.
Option 2: Give users the ability to customize their own scheduler without the need to modify their already existing Go codes. I didn't get a very detailed idea yet. Look forward to your excellent ideas.
You might say that one could achieve this goal in the application layer like the way of cpuworker did, but for most applications with already a very large amount of Go codes, such change is just too expensive. And such change in runtime would be more efficient. Therefore, I tend to hope that Go could provide a similar mechanism rather than expect users to achieve this goal by themselves in the application layer.
Thanks a lot for your time to watch this proposal :-)