Avec autant d'architectures Transformer différentes, il peut être difficile d'en créer une pour votre ensemble de poids (aussi appelés "weights" ou "checkpoint" en anglais). Dans l'idée de créer une librairie facile, simple et flexible à utiliser, 🤗 Transformers fournit une AutoClass qui infère et charge automatiquement l'architecture correcte à partir d'un ensemble de poids donné. La fonction from_pretrained() vous permet de charger rapidement un modèle pré-entraîné pour n'importe quelle architecture afin que vous n'ayez pas à consacrer du temps et des ressources à l'entraînement d'un modèle à partir de zéro. Produire un tel code indépendant d'un ensemble de poids signifie que si votre code fonctionne pour un ensemble de poids, il fonctionnera avec un autre ensemble - tant qu'il a été entraîné pour une tâche similaire - même si l'architecture est différente.
Rappel, l'architecture fait référence au squelette du modèle et l'ensemble de poids contient les poids pour une architecture donnée. Par exemple, BERT est une architecture, tandis que google-bert/bert-base-uncased est un ensemble de poids. Le terme modèle est général et peut signifier soit architecture soit ensemble de poids.
Dans ce tutoriel, vous apprendrez à:
- Charger un tokenizer pré-entraîné.
- Charger un processeur d'image pré-entraîné.
- Charger un extracteur de caractéristiques pré-entraîné.
- Charger un processeur pré-entraîné.
- Charger un modèle pré-entraîné.
Quasiment toutes les tâches de traitement du langage (NLP) commencent avec un tokenizer. Un tokenizer convertit votre texte initial dans un format qui peut être traité par le modèle.
Chargez un tokenizer avec [AutoTokenizer.from_pretrained]:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")Puis, transformez votre texte initial comme montré ci-dessous:
>>> sequence = "In a hole in the ground there lived a hobbit."
>>> print(tokenizer(sequence))
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}Pour les tâches de vision, un processeur d'image traite l'image pour la formater correctment.
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")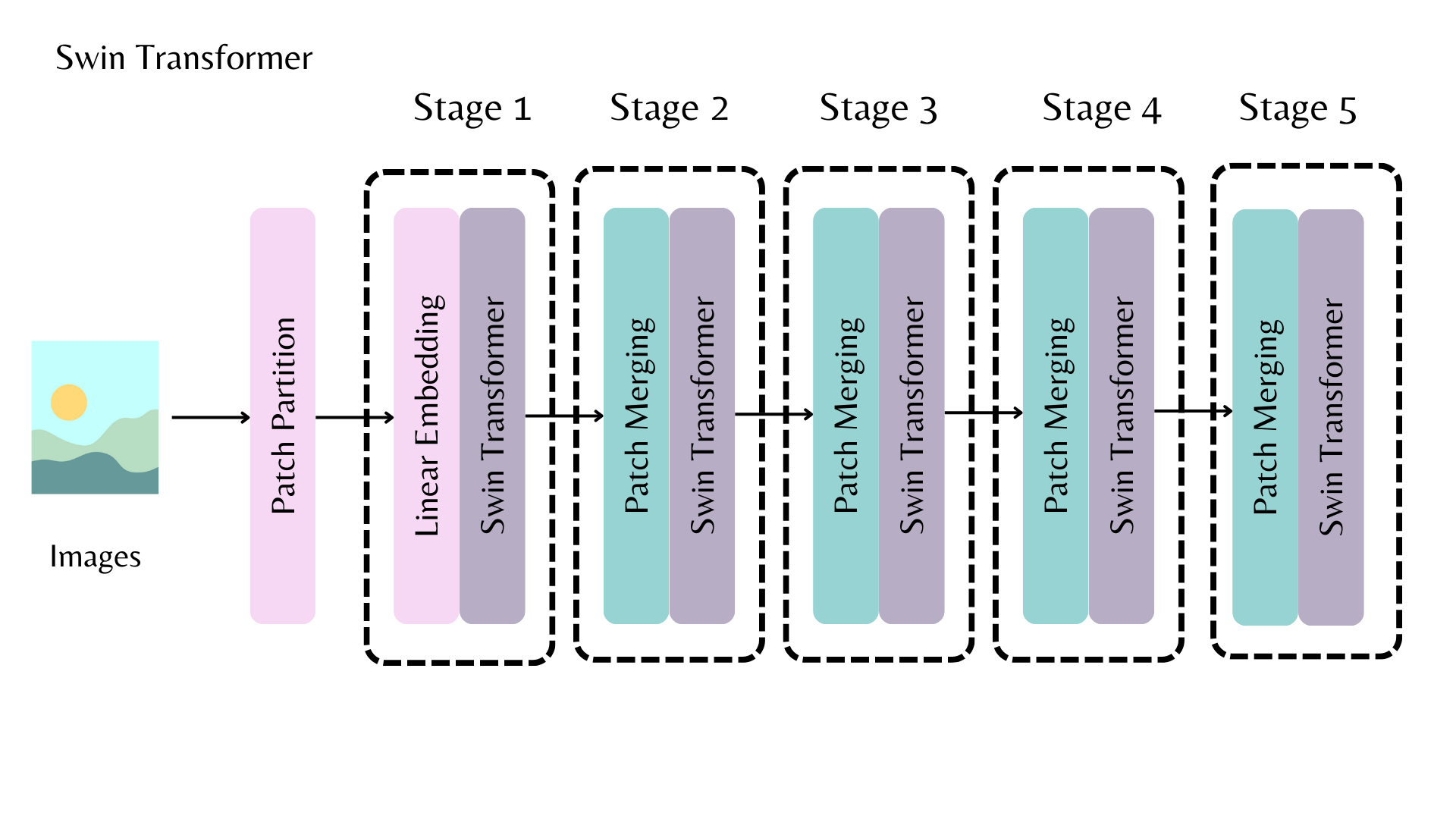 Un backbone Swin avec plusieurs étapes pour produire une carte de caractéristiques.
Un backbone Swin avec plusieurs étapes pour produire une carte de caractéristiques.
[AutoBackbone] vous permet d'utiliser des modèles pré-entraînés comme backbones pour obtenir des cartes de caractéristiques à partir de différentes étapes du backbone. Vous devez spécifier l'un des paramètres suivants dans [~PretrainedConfig.from_pretrained] :
out_indicesest l'index de la couche dont vous souhaitez obtenir la carte de caractéristiquesout_featuresest le nom de la couche dont vous souhaitez obtenir la carte de caractéristiques
Ces paramètres peuvent être utilisés de manière interchangeable, mais si vous utilisez les deux, assurez-vous qu'ils sont alignés l'un avec l'autre ! Si vous ne passez aucun de ces paramètres, le backbone renvoie la carte de caractéristiques de la dernière couche.
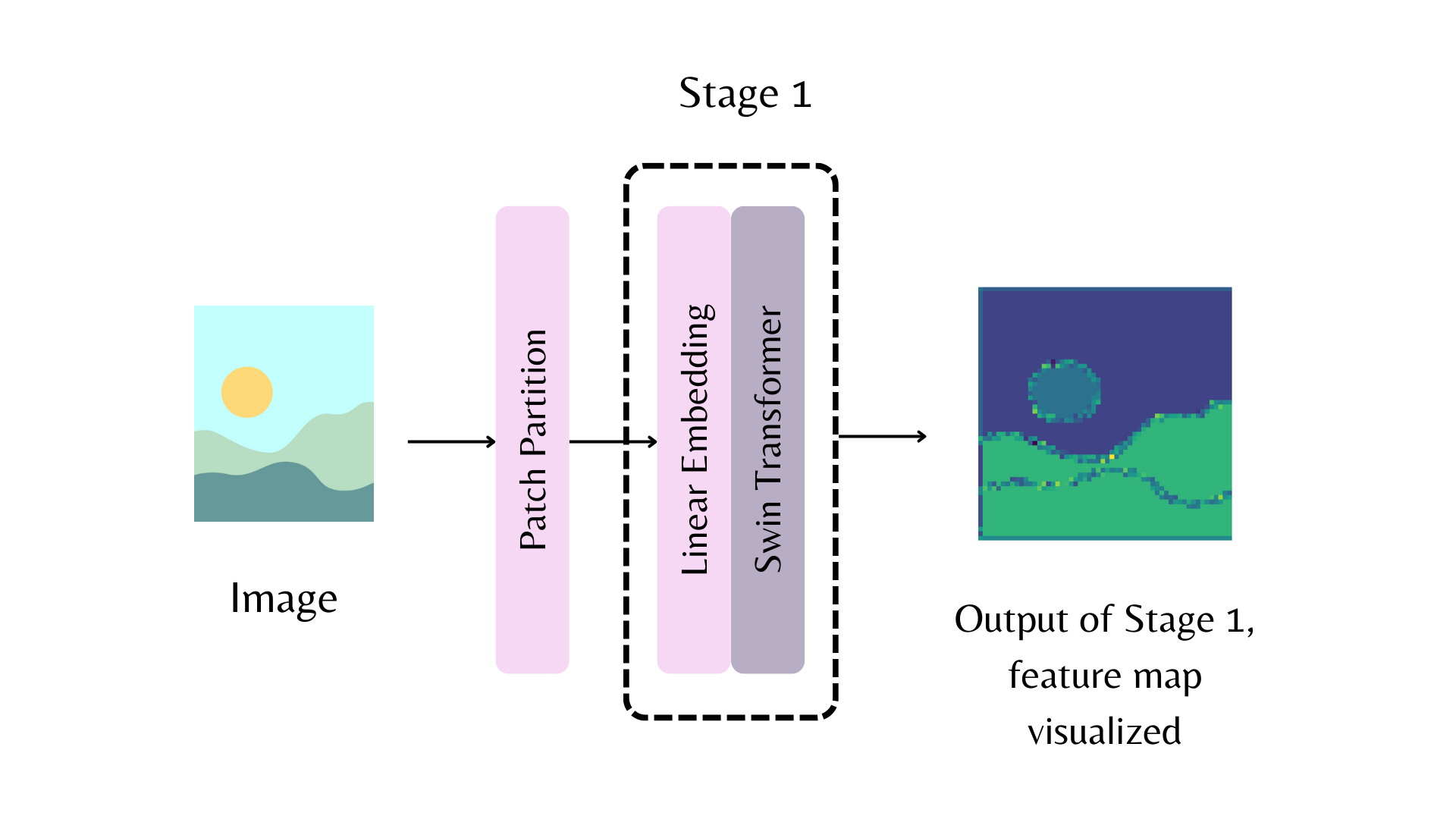 Une carte de caractéristiques de la première étape du backbone. La partition de patch fait référence à la tige du modèle.
Une carte de caractéristiques de la première étape du backbone. La partition de patch fait référence à la tige du modèle.
Par exemple, dans le diagramme ci-dessus, pour renvoyer la carte de caractéristiques de la première étape du backbone Swin, vous pouvez définir out_indices=(1,) :
>>> from transformers import AutoImageProcessor, AutoBackbone
>>> import torch
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
>>> model = AutoBackbone.from_pretrained("microsoft/swin-tiny-patch4-window7-224", out_indices=(1,))
>>> inputs = processor(image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> feature_maps = outputs.feature_mapsVous pouvez maintenant accéder à l'objet feature_maps de la première étape du backbone :
>>> list(feature_maps[0].shape)
[1, 96, 56, 56]Pour les tâches audio, un extracteur de caractéristiques (aussi appelés "features" en anglais) traite le signal audio pour le formater correctement.
Chargez un extracteur de caractéristiques avec [AutoFeatureExtractor.from_pretrained]:
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )Les tâches multimodales nécessitent un processeur qui combine deux types d'outils de prétraitement. Par exemple, le modèle LayoutLMV2 nécessite un processeur d'image pour traiter les images et un tokenizer pour traiter le texte ; un processeur combine les deux.
Chargez un processeur avec [AutoProcessor.from_pretrained]:
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")Réutilisez facilement le même ensemble de poids pour charger une architecture pour une tâche différente :
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased")Pour les modèles PyTorch, la fonction from_pretrained() utilise torch.load() qui utilise pickle en interne et est connu pour être non sécurisé. En général, ne chargez jamais un modèle qui pourrait provenir d'une source non fiable, ou qui pourrait avoir été altéré. Ce risque de sécurité est partiellement atténué pour les modèles hébergés publiquement sur le Hugging Face Hub, qui sont scannés pour les logiciels malveillants à chaque modification. Consultez la documentation du Hub pour connaître les meilleures pratiques comme la vérification des modifications signées avec GPG.
Les points de contrôle TensorFlow et Flax ne sont pas concernés, et peuvent être chargés dans des architectures PyTorch en utilisant les arguments from_tf et from_flax de la fonction from_pretrained pour contourner ce problème.
En général, nous recommandons d'utiliser les classes AutoTokenizer et AutoModelFor pour charger des instances pré-entraînées de tokenizers et modèles respectivement. Cela vous permettra de charger la bonne architecture à chaque fois. Dans le prochain tutoriel, vous apprenez à utiliser un tokenizer, processeur d'image, extracteur de caractéristiques et processeur pour pré-traiter un jeu de données pour le fine-tuning.
Enfin, les classes TFAutoModelFor vous permettent de charger un modèle pré-entraîné pour une tâche donnée (voir ici pour une liste complète des tâches disponibles). Par exemple, chargez un modèle pour la classification de séquence avec [TFAutoModelForSequenceClassification.from_pretrained]:
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")Réutilisez facilement le même ensemble de poids pour charger une architecture pour une tâche différente :
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased")En général, nous recommandons d'utiliser les classes AutoTokenizer et TFAutoModelFor pour charger des instances pré-entraînées de tokenizers et modèles respectivement. Cela vous permettra de charger la bonne architecture à chaque fois. Dans le prochain tutoriel, vous apprenez à utiliser un tokenizer, processeur d'image, extracteur de caractéristiques et processeur pour pré-traiter un jeu de données pour le fine-tuning.