![]()
VGGR is a Deep-Learning Image Classification project, answering questions nobody is asking.
-
Install Python 3.10 or newer.
-
Clone the repository with
git clone https://github.com/m4cit/VGGR.gitor download the latest source code.
-
Download the latest train, test, and validation img zip-files in releases.
-
Unzip the train, test, and validation img files inside their respective folders located in ./data/.
-
Install PyTorch.
5.1 Either with CUDA
- Windows:
pip3 install torch==2.2.2 torchvision==0.17.2 --index-url https://download.pytorch.org/whl/cu121 - Linux:
pip3 install torch==2.2.2 torchvision==0.17.2
5.2 Or without CUDA
- Windows:
pip3 install torch==2.2.2 torchvision==0.17.2 - Linux:
pip3 install torch==2.2.2 torchvision==0.17.2 --index-url https://download.pytorch.org/whl/cpu
- Windows:
-
Navigate to the VGGR main directory.
cd VGGR -
Install dependencies.
pip install -r requirements.txt
Note: The provided train dataset does not contain augmentations.
- Football / Soccer
- First Person Shooter (FPS)
- 2D Platformer
- Racing
- FIFA 06
- Call of Duty Black Ops
- Call of Duty Modern Warfare 3
- DuckTales Remastered
- Project CARS
- PES 2012
- FIFA 10
- Counter Strike 1.6
- Counter Strike 2
- Ori and the Blind Forest
- Dirt 3
- Left 4 Dead 2
- Oddworld Abe's Oddysee
- FlatOut 2
--demo | Demo predictions with the test set
--augment | Data Augmentation
--train | Train mode
--predict | Predict / inference mode
--input (-i) | File input for predict mode (URL or local image path)
--model (-m) | Model selection
- cnn_v1 (default)
- cnn_v2
- cnn_v3
--device (-d) | Device selection
- cpu (default)
- cuda
- ipu
- xpu
- mkldnn
- opengl
- opencl
- ideep
- hip
- ve
- fpga
- ort
- xla
- lazy
- vulkan
- mps
- meta
- hpu
- mtia
python VGGR.py --demo
or
python VGGR.py --demo -m cnn_v1 -d cpu
or
python VGGR.py --demo --model cnn_v1 --device cpu
python VGGR.py --predict -i path/to/img.png
or
python VGGR.py --predict -i https://website/img.png
or
python VGGR.py --predict -i path/to/img.png -m cnn_v1 -d cpu
python VGGR.py --train -m cnn_v1 -d cpu
Delete the existing model to train from scratch.
The --demo mode creates html files with the predictions and corresponding images inside the results folder.
There are three Convolutional Neural Network (CNN) models available:
- cnn_v1 | F-score of 75 %
- cnn_v2 | F-score of 58.33 %
- cnn_v3 | F-score of 64.58 %
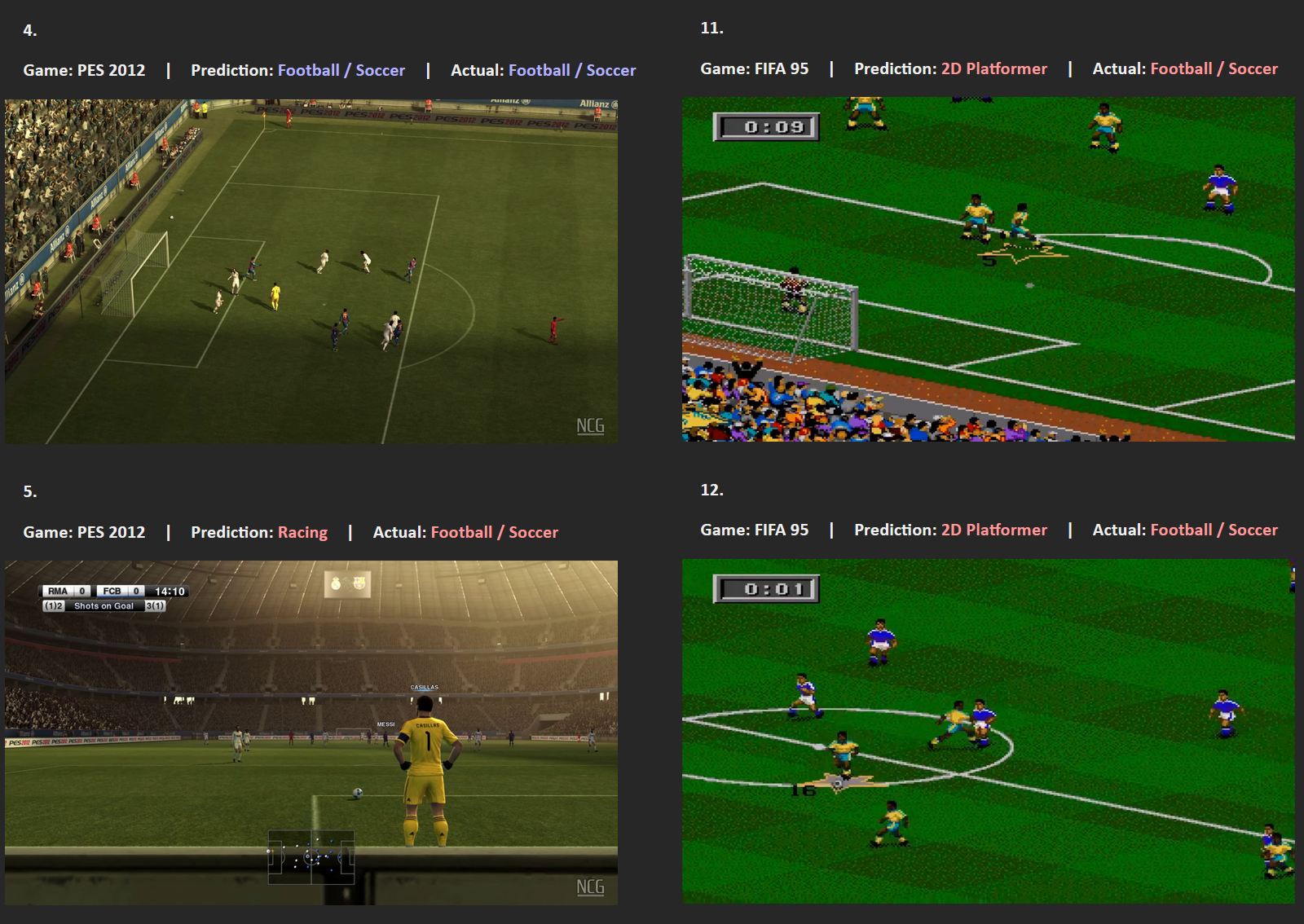
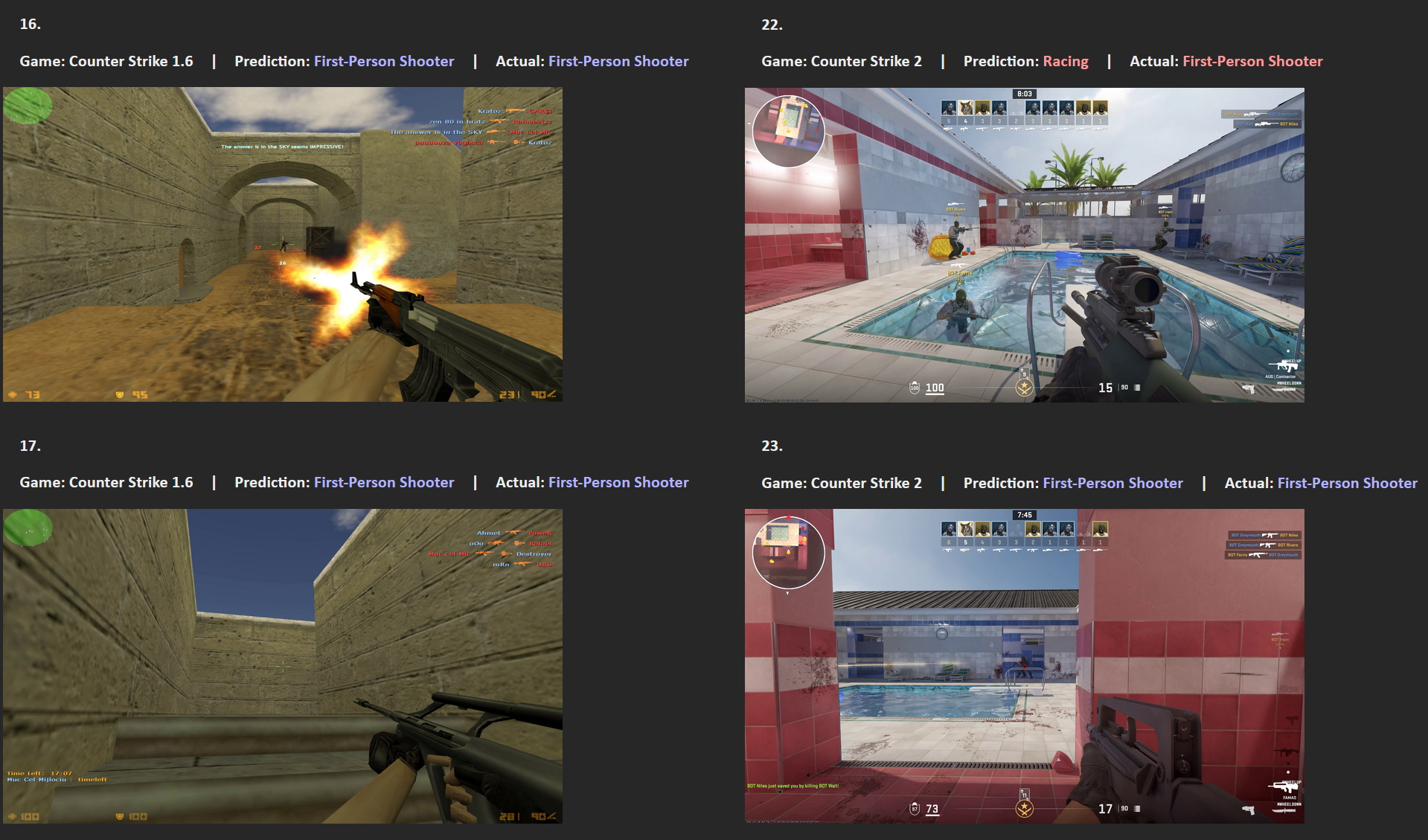
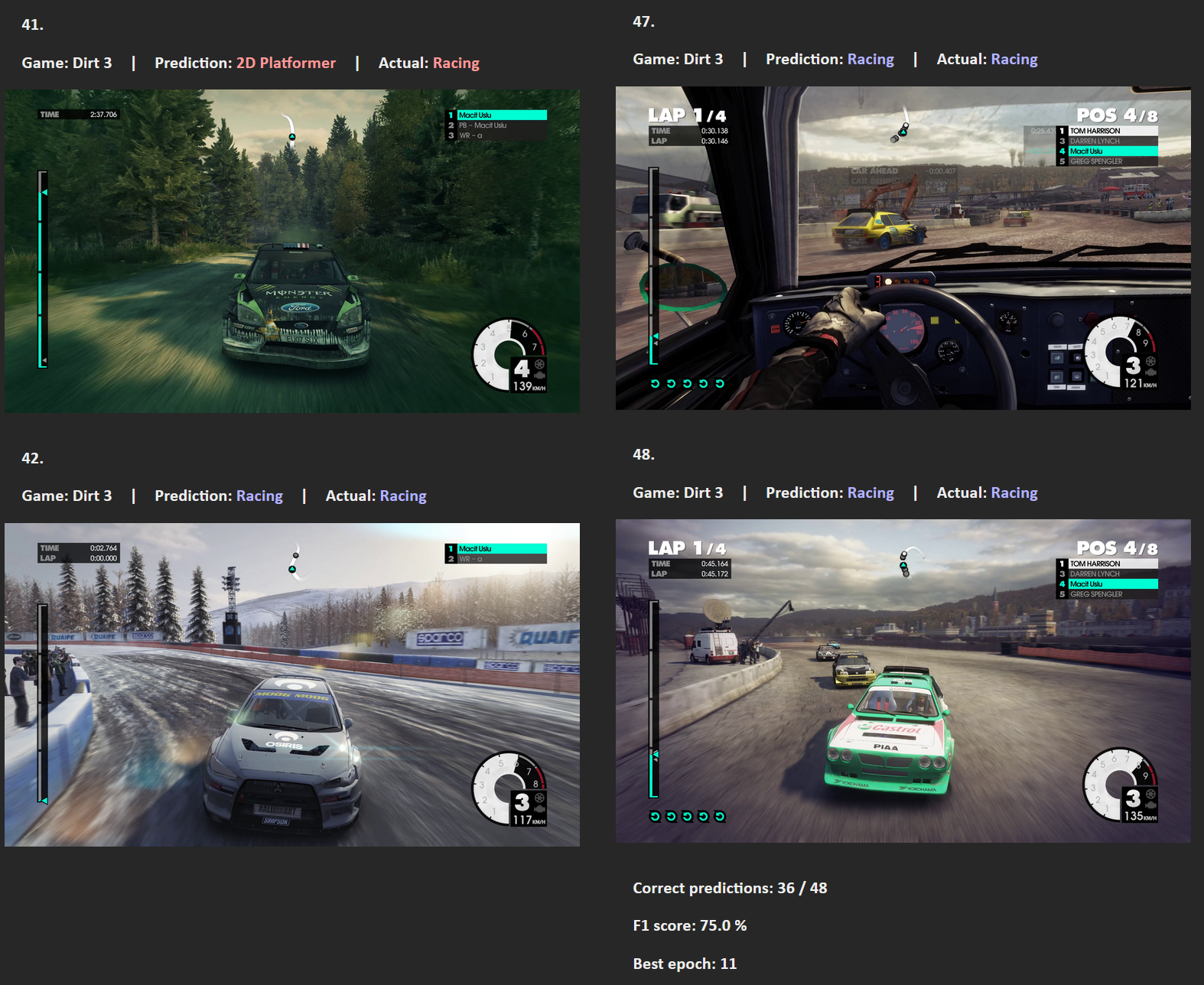
Most of the images are from my own gameplay footage. The PES 2012 and FIFA 10 images are from videos by No Commentary Gameplays, and the FIFA 95 images are from a video by 10min Gameplay (YouTube).
The train dataset also contained augmentations (not in the provided zip-file).
To augment the train data with jittering, inversion, and 5 part cropping, copy-paste the metadata of the images into the augment.csv file located in ./data/train/metadata/.
Then run
python VGGR.py --augment
The metadata of the resulting images are subsequently added to the metadata.csv file.
All images are originally 2560x1440p, and get resized to 1280x720p before training, validation, and inference. 4:3 images are stretched to 16:9 to avoid black bars.