Suomen johtava Rails-talo Kisko järjestää kurssilaisille illanvieton pe 16.12. klo 16-18
Jos haluat mukaan, kysy ilmoittautumislinkkiä matti.luukkainen@helsinki.fi tai Discordissa kurssikanavalla tai @mluukkai
Jatkamme sovelluksen rakentamista siitä, mihin jäimme viikon 6 lopussa. Allaoleva materiaali olettaa, että olet tehnyt kaikki edellisen viikon tehtävät. Jos et tehnyt kaikkia tehtäviä, voit täydentää ratkaisusi tehtävien palautusjärjestelmän kautta näkyvän esimerkivastauksen avulla.
Viikolla 2 tutustuimme debuggeriin ja viime viikolla oli muistutus debuggerin käytösä. Eli vielä kertauksena kun kohtaat ongelman, turvaudu arvailun sijaan debuggeriin!
Rails-konsolin käytön tärkeyttä sovelluskehityksen välineenä on yritetty korostaa läpi kurssin. Eli kun teet jotain vähänkin epätriviaalia, testaa asia ensin konsolissa. Joissain tilanteissa voi olla jopa parempi tehdä kokeilut debuggerin avulla avautuvassa konsolissa, sillä tällöin on mahdollista avata konsolisessio juuri siihen kontekstiin, mihin koodia ollaan kirjoittamassa. Näin ollen päästään käsiksi esim. muuttujiin params, sessions ym. suorituskontekstista riippuvaan dataan.
Osa tämän viikon tehtävistä saattaa hajottaa jotain edellisinä viikkoina tehtyjä testejä. Voit merkitä tehtävät testien hajoamisesta huolimatta, eli testien ja GitHub Actionsin pitäminen kunnossa on vapaaehtoista.
Päätetään toteuttaa oluiden listalle toiminnallisuus, jonka avulla oluet voidaan järjestää eri sarakkeiden perusteella. Välitetään tieto halutusta järjestyksestä kontrollerille HTTP-pyynnön parametrina. Muutetaan näkymässä app/views/beers/index.html.erb olevaa taulukkoa seuraavasti:
<table class="table table-striped table-hover">
<thead>
<tr>
<th><%= link_to "Name", beers_path(order: "name")%></th>
<th><%= link_to "Style", beers_path(order: "style")%></th>
<th><%= link_to "Brewery", beers_path(order: "brewery")%></th>
<th><%= link_to "Rating", beers_path(order: "rating")%></th>
</tr>
</thead>
...
</table>eli taulukon sarakkeiden otsikoista on nyt tehty linkit, jotka johtavat takaisin samalle sivulle mutta lisäävät pyyntöön query parametrin :order, joka määrittelee halutun järjestyksen. Käytännössä parametri välitetään urlin mukana liittäen se "normaalin" urlin perään kysymysmerkillä erottaen. Esim. jos klikataan tyylisaraketta, tulee urliksi beers?order=style
Kontrolleri pääsee HTTP-pyynnön parametriin käsiksi params-hashin avulla ja kuten olettaa saattaa, suunnan määrittelevän parametrin arvo on params[:order].
Laajennetaan oluiden kontrolleria siten, että se testaa onko pyynnössä parametria, ja jos on, oluet järjestetään halutulla tavalla:
def index
@beers = Beer.all
order = params[:order] || 'name'
@beers = case order
when "name" then @beers.sort_by(&:name)
when "brewery" then @beers.sort_by { |b| b.brewery.name }
when "style" then @beers.sort_by { |b| b.style.name }
when "rating" then @beers.sort_by(&:average_rating).reverse
end
endKoodi määrittelee järjestämisen tapahtuvan oletusarvoisesti nimen perusteella. Tämä tapahtuu seuraavasti
order = params[:order] || 'name'Normaalisti order saa arvon params[:order], jos parametria :order ei ole asetettu, eli sen arvo on nil, tulee arvoksi ||:n jälkeinen osa eli 'name'.
Huom1: käytämme oluiden järjestämiseen Rubyn case when-komentoa
@beers = case order
when 'name' then @beers.sort_by{ |b| b.name }
when 'brewery' then @beers.sort_by{ |b| b.brewery.name }
when 'style' then @beers.sort_by{ |b| b.style.name }
endjoka toimii oleellisesti samoin kuin seuraava
@beers =
if order == 'name'
@beers.sort_by{ |b| b.name }
elsif orded == 'brewery'
@beers.sort_by{ |b| b.brewery.name }
elsif orded == 'style'
@beers.sort_by{ |b| b.style.name }
endHuom2: esimerkissä oluet haetaan ensin tietokannasta ja sen jälkeen järjestetään ne keskusmuistissa. Oluiden lista olisi mahdollista järjestää myös tietokantatasolla:
# oluet nimen perusteella järjestettynä
Beer.order(:name)
# oluet panimoiden nimien perusteella järjestettynä
Beer.includes(:brewery).order("breweries.name")
# oluet tyylin nimien perusteella järjestettynä
Beer.includes(:style).order("style.name")Muuta olutseurat listaavaa sivua siten, että seurat voidaan järjestää nimen mukaiseen aakkosjärjestykseen, perustamisvuoden mukaiseen järjestykseen tai kaupungin nimen mukaiseen aakkosjärjestykseen. Nimen mukainen järjestys on oletusarvoinen.
HUOM jos et ole toteuttanut sovellukseesi olutkerhoja, voit toteuttaa tämän tehtävän toiminnallisuuden panimoiden sivulle (ja olettaa että aktiiviset ja lopettaneet panimot järjestetään aina samalla tavalla).
Ratkaisumme oluiden listan järjestämiseen on melko hyvä. Suorituskyvyn kannalta hieman ongelmallista on tosin se, että aina järjestettäessä tehdään kutsu palvelimelle, joka generoi uudessa järjestyksessä näytettävän sivun.
Järjestämistoiminnallisuus voitaisiin toteuttaa myös selaimen puolella JavaScriptillä. Vaikka kurssi keskittyy palvelinpuolen toiminnallisuuteen, näytetään seuraavassa esimerkki siitä, miten järjestämistoiminnallisuus toteutettaisiin selainpuolella. Tässä ratkaisussa palvelin tarjoaa ainoastaan oluiden listan json-muodossa, ja selaimessa suoritettava JavaScript-koodi hoitaa myös oluet listaavan taulukon muodostamisen.
Emme korvaa nyt olemassaolevaa oluiden listaa, eli sivun beers toiminnallisuutta, sen sijaan tehdään toiminnallisuutta varten kokonaan uusi, osoitteessa beerlist toimiva sivu. Tehdään sivua varten reitti tiedostoon routes.rb:
get 'beerlist', to: 'beers#list'
Käytämme siis olutkontrollerissa olevaa list-metodia. Metodin ei tarvitse tehdä mitään:
class BeersController < ApplicationController
before_action :ensure_that_signed_in, except: [:index, :show, :list]
# muut before_actionit ennallaan
def list
end
...
endHUOM lisäsimme metodin list niihin, joita ennen ei tarvitse suorittaa ensure_that_signed_in-metodia, eli oluiden JavaScriptilla tuotetun listan näkeminen ei edellytä sivulle kirjautumista!
Myös näkymä views/beers/list.html.erb on minimalistinen:
<h2>Beers</h2>
<div id="beers"></div>Eli näkymä ainoastaan sijoittaa sivulle div-elementin, jolle annetaan id:ksi (eli viitteksi, jolla elementtiin päästään käsiksi) "beers".
Kuten odotettua, osoitteessa http://localhost:3000/beerlist ei nyt näy mitään muuta kuin h2-elementin sisältö.
Alamme nyt kirjoittamaan toimintalogiikan toteutusta JavaScriptiä hyödyntäen.
Rails-sovelluksen tarvitsema JavaScript-koodi kannattaa sijoittaa hakemistoon app/javascript/custom. Tehdään hakemistoon tiedosto utils.js jolla on seuraava sisältö:
const hello = () => {
document.getElementById("beers").innerText = "Hello from JavaScript";
console.log("hello console!");
}
export { hello };Tämän lisäksi meidän pitää ottaa hello-funktio käyttöön sovelluksessa. Tehdään se lisäämällä app/javascript/application.js tiedostoon seuraavat rivit:
import { hello } from "custom/utils";
hello();Otetaan myös custom-hakemistossa sijaitseva JavaScript käyttöön sovelluksen importmapissä, eli lisätään config/importmap.rb tiedostoon rivi:
pin_all_from "app/javascript/custom", under: "custom"Kun sivu nyt avataan uudelleen, haetaan ensin JavaScriptillä id:n beers omaavaan omaava elementti, jonka jälkeen sen tekstiksi asetetaan "Hello form JavaScript". Seuraava komento kirjoittaa JavaScript-konsoliin tervehdyksen.
JavaScript-ohjelmoinnissa selaimessa oleva konsoli on erittäin tärkeä työväline. Konsolin saa avattua Chromessa tools-valikosta tai painamalla ctrl, shift, j (linux) tai alt, cmd, i (mac):
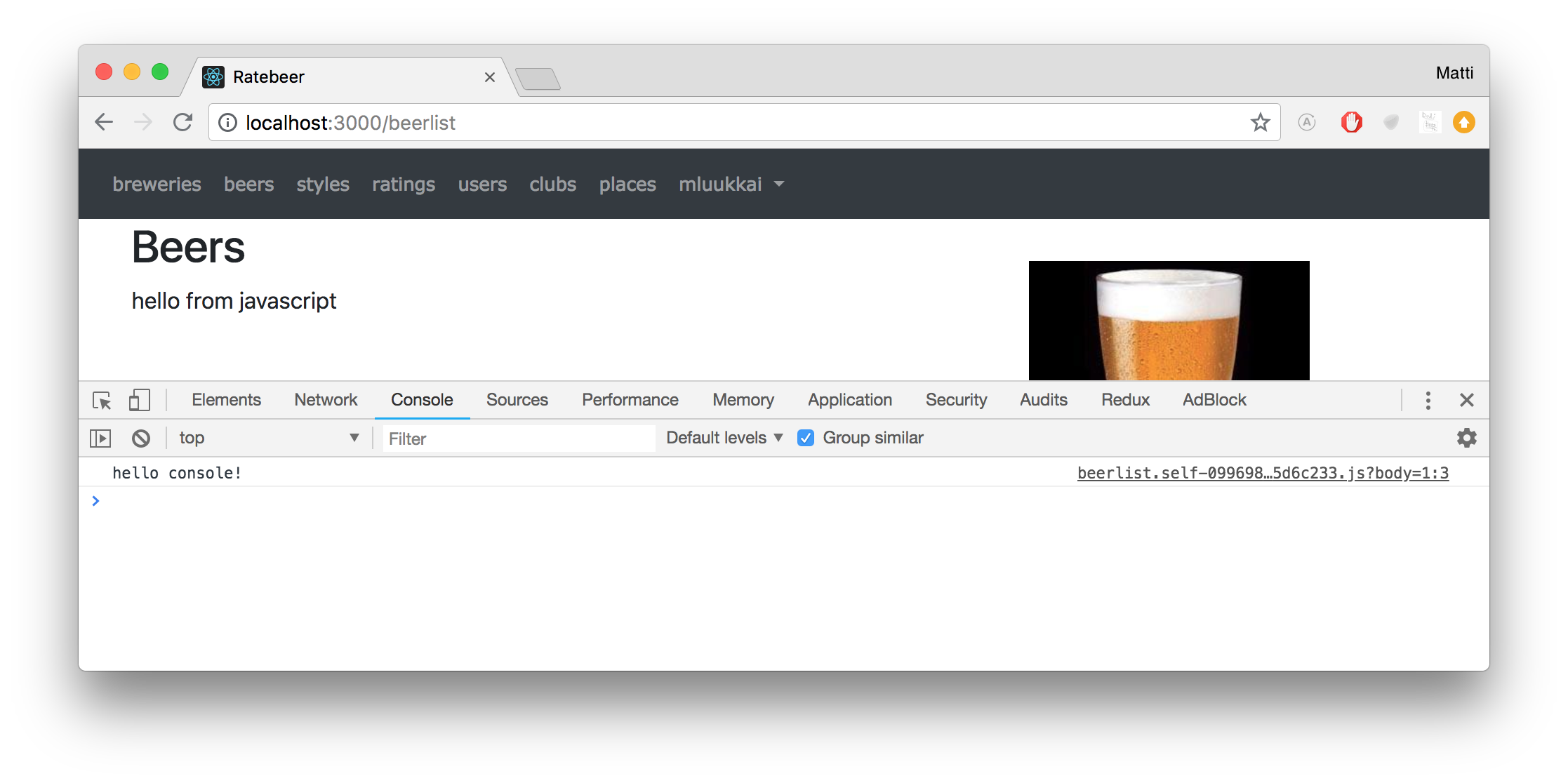
Konsoli on syytä pitää koko ajan auki JavaScriptillä ohjelmoitaessa!
Javascript näyttää aluksi melko kryptiseltä, mm. paljon käytettyjen anonyymifunktioiden takia. application.js tiedostossa oleva koodi määrittelee, että sivun latautuessa tiedostossa utils.js oleva hello-funktio suoritetaan.
Jos kokeilemme selaimella osoitetta http://localhost:3000/beers.json huomaamme, että saamme vastaukseksi oluiden tiedot tekstuaalisessa json-muodossa (ks. http://en.wikipedia.org/wiki/JSON, http:www.json.org):
[{"id":10,"name": "Extra Light Triple Brewed","style":{"id":1,"name": "European pale lager","description": "Similar to Munich Helles, many European countries reacted to the popularity of early pale lagers by brewing their own. Hop flavor is significant and of noble varieties, bitterness is moderate, and both are backed by a solid malt body and sweet notes from an all-malt base.","created_at": "2022-09-05T10:17:39.358Z","updated_at": "2022-09-05T10:35:04.921Z"},"brewery_id":1,"created_at": "2018-09-01T16:47:54.117Z","updated_at": "2022-09-05T10:17:39.414Z","url": "http://localhost:3000/beers/10.json"},{"id":6,"name": "Hefeweizen","style":{"id":4,"name": "German hefeweizen","description": "A south German style of wheat beer (weissbier) typically made with a ratio of 50 percent barley to 50 percent wheat. Sometimes the percentage of wheat is even higher. \"Hefe\" means \"with yeast,\" hence the beer's unfiltered and cloudy appearance. The particular ale yeast used produces unique esters and phenols of banana and cloves with an often dry and tart edge, some spiciness, and notes of bubblegum or apples. Hefeweizens are typified by little hop bitterness, and a moderate level of alcohol. Often served with a lemon wedge (popularized by Americans), to cut the wheat or yeasty edge, some may find this to be either a flavorful snap or an insult that can damage the beer's taste and head retention.","created_at": "2022-09-05T10:17:39.361Z","updated_at": "2022-09-05T10:36:17.788Z"},"brewery_id":3,"created_at": "2018-09-01T16:41:53.522Z","updated_at": "2022-09-05T10:17:39.406Z","url": "http://localhost:3000/beers/6.json"},{"id":7,"name": "Helles","style":{"id":1,"name": "European pale lager","description": "Similar to Munich Helles, many European countries reacted to the popularity of early pale lagers by brewing their own. Hop flavor is significant and of noble varieties, bitterness is moderate, and both are backed by a solid malt body and sweet notes from an all-malt base.","created_at": "2022-09-05T10:17:39.358Z","updated_at": "2022-09-05T10:35:04.921Z"},"brewery_id":3,"created_at": "2018-09-01T16:41:53.525Z","updated_at": "2022-09-05T10:17:39.408Z","url": "http://localhost:3000/beers/7.json"},{"id":16,"name": "Helles","style":{"id":1,"name": "European pale lager","description": "Similar to Munich Helles, many European countries reacted to the popularity of early pale lagers by brewing their own. Hop flavor is significant and of noble varieties, bitterness is moderate, and both are backed by a solid malt body and sweet notes from an all-malt base.","created_at": "2022-09-05T10:17:39.358Z","updated_at": "2022-09-05T10:35:04.921Z"},"brewery_id":3,"created_at": "2018-09-08T10:56:52.592Z","updated_at": "2022-09-05T10:17:39.420Z","url": "http://localhost:3000/beers/16.json"},{"id":4,"name": "Huvila Pale Ale","style":{"id":2,"name": "American Pale Ale","description": "Originally British in origin, this style is now popular worldwide and the use of local or imported ingredients produces variances in character from region to region. American versions tend to be cleaner and hoppier (with the piney, citrusy Cascade variety appearing frequently) than British versions, which are usually more malty, buttery, aromatic, and balanced. Pale Ales range in color from deep gold to medium amber. Fruity esters and diacetyl can vary from none to moderate, and hop aroma can range from lightly floral to bold and pungent. In general, expect a good balance of caramel malt and expressive hops with a medium body and a mildly bitter finish. ","created_at": "2022-09-05T10:17:39.359Z","updated_at": "2018-09-22T12:07:42.742Z"},"brewery_id":2,"created_at": "2018-09-01T16:41:53.516Z","updated_at": "2022-09-05T10:17:39.396Z","url": "http://localhost:3000/beers/4.json"},{"id":9,"name": "IVB","style":{"id":1,"name": "European pale lager","description": "Similar to Munich Helles, many European countries reacted to the popularity of early pale lagers by brewing their own. Hop flavor is significant and of noble varieties, bitterness is moderate, and both are backed by a solid malt body and sweet notes from an all-malt base.","created_at": "2022-09-05T10:17:39.358Z","updated_at": "2022-09-05T10:35:04.921Z"},"brewery_id":1,"created_at": "2018-09-01T16:46:01.643Z","updated_at": "2022-09-05T10:17:39.412Z","url": "http://localhost:3000/beers/9.json"},{"id":1,"name": "Iso 3","style":{"id":1,"name": "European pale lager","description": "Similar to Munich Helles, many European countries reacted to the popularity of early pale lagers by brewing their own. Hop flavor is significant and of noble varieties, bitterness is moderate, and both are backed by a solid malt body and sweet notes from an all-malt base.","created_at": "2022-09-05T10:17:39.358Z","updated_at": "2022-09-05T10:35:04.921Z"},"brewery_id":1,"created_at": "2018-09-01T16:41:53.508Z","updated_at": "2022-09-05T10:17:39.384Z","url": "http://localhost:3000/beers/1.json"},{"id":2,"name": "Karhu","style":{"id":1,"name": "European pale lager","description": "Similar to Munich Helles, many European countries reacted to the popularity of early pale lagers by brewing their own. Hop flavor is significant and of noble varieties, bitterness is moderate, and both are backed by a solid malt body and sweet notes from an all-malt base.","created_at": "2022-09-05T10:17:39.358Z","updated_at": "2022-09-05T10:35:04.921Z"},"brewery_id":1,"created_at": "2018-09-01T16:41:53.511Z","updated_at": "2022-09-05T10:17:39.389Z","url": "http://localhost:3000/beers/2.json"},{"id":8,"name": "Lite","style":{"id":1,"name": "European pale lager","description": "Similar to Munich Helles, many European countries reacted to the popularity of early pale lagers by brewing their own. Hop flavor is significant and of noble varieties, bitterness is moderate, and both are backed by a solid malt body and sweet notes from an all-malt base.","created_at": "2022-09-05T10:17:39.358Z","updated_at": "2022-09-05T10:35:04.921Z"},"brewery_id":1,"created_at": "2018-09-01T16:45:09.037Z","updated_at": "2022-09-05T10:17:39.410Z","url": "http://localhost:3000/beers/8.json"},{"id":14,"name": "Nanny State","style":{"id":6,"name": "Low alcohol beer","description": "Low Alcohol Beer is also commonly known as Non Alcohol (NA) beer, despite containing small amounts of alcohol. Low Alcohol Beers are generally subjected to one of two things: a controlled brewing process that results in a low alcohol content, or the alcohol is removed using a reverse-osmosis method which passes alcohol through a permeable membrane. They tend to be very light on aroma, body, and flavor.","created_at": "2022-09-05T10:17:39.362Z","updated_at": "2018-09-22T12:11:57.808Z"},"brewery_id":5,"created_at": "2018-09-06T14:30:50.585Z","updated_at": "2022-09-05T10:17:39.418Z","url": "http://localhost:3000/beers/14.json"},{"id":23,"name": "Panimomestarin IPA","style":{"id":5,"name": "American IPA","description": "Today's American IPA is a different soul from the IPA style first reincarnated in the 1980s. More flavorful and aromatic than the withering English IPA, its color can range from very pale golden to reddish amber. Hops are the star here, and those used in the style tend to be American with an emphasis on herbal, piney, and/or fruity (especially citrusy) varieties. Southern Hemisphere and experimental hops do appear with some frequency though, as brewers seek to distinguish their flagship IPA from a sea of competitors. Bitterness levels vary, but typically run moderate to high. Medium bodied with a clean, bready, and balancing malt backbone, the American IPA has become a dominant force in the marketplace, influencing brewers and beer cultures worldwide.","created_at": "2022-09-05T10:17:39.361Z","updated_at": "2018-09-22T12:09:23.686Z"},"brewery_id":1,"created_at": "2018-09-22T10:33:04.353Z","updated_at": "2018-09-22T10:33:04.353Z","url": "http://localhost:3000/beers/23.json"},{"id":13,"name": "Punk IPA","style":{"id":5,"name": "American IPA","description": "Today's American IPA is a different soul from the IPA style first reincarnated in the 1980s. More flavorful and aromatic than the withering English IPA, its color can range from very pale golden to reddish amber. Hops are the star here, and those used in the style tend to be American with an emphasis on herbal, piney, and/or fruity (especially citrusy) varieties. Southern Hemisphere and experimental hops do appear with some frequency though, as brewers seek to distinguish their flagship IPA from a sea of competitors. Bitterness levels vary, but typically run moderate to high. Medium bodied with a clean, bready, and balancing malt backbone, the American IPA has become a dominant force in the marketplace, influencing brewers and beer cultures worldwide.","created_at": "2022-09-05T10:17:39.361Z","updated_at": "2018-09-22T12:09:23.686Z"},"brewery_id":5,"created_at": "2018-09-06T14:30:33.589Z","updated_at": "2022-09-05T10:17:39.416Z","url": "http://localhost:3000/beers/13.json"},{"id":22,"name": "Sink the Bismarck","style":{"id":3,"name": "Baltic Porter","description": "Porters of the late 1700's were quite strong compared to today�'s standards, easily surpassing 7 percent alcohol by volume. Some English brewers made a stronger, more robust version, to be shipped across the North Sea that they dubbed a Baltic Porter. In general, the style'�s dark brown color covered up cloudiness and the smoky, roasted brown malts and bitter tastes masked brewing imperfections. Historically, the addition of stale ale also lent a pleasant acidic flavor to the style, which made it quite popular. These issues were quite important given that most breweries at the time were getting away from pub brewing and opening up production facilities that could ship beer across the world.","created_at": "2022-09-05T10:17:39.360Z","updated_at": "2018-09-22T12:08:13.953Z"},"brewery_id":5,"created_at": "2018-09-22T10:09:59.120Z","updated_at": "2018-09-22T10:09:59.120Z","url": "http://localhost:3000/beers/22.json"},{"id":21,"name": "Trans European Lager","style":{"id":1,"name": "European pale lager","description": "Similar to Munich Helles, many European countries reacted to the popularity of early pale lagers by brewing their own. Hop flavor is significant and of noble varieties, bitterness is moderate, and both are backed by a solid malt body and sweet notes from an all-malt base.","created_at": "2022-09-05T10:17:39.358Z","updated_at": "2022-09-05T10:35:04.921Z"},"brewery_id":1,"created_at": "2022-09-05T10:42:19.312Z","updated_at": "2022-09-05T10:42:19.312Z","url": "http://localhost:3000/beers/21.json"},{"id":3,"name": "Tuplahumala","style":{"id":1,"name": "European pale lager","description": "Similar to Munich Helles, many European countries reacted to the popularity of early pale lagers by brewing their own. Hop flavor is significant and of noble varieties, bitterness is moderate, and both are backed by a solid malt body and sweet notes from an all-malt base.","created_at": "2022-09-05T10:17:39.358Z","updated_at": "2022-09-05T10:35:04.921Z"},"brewery_id":1,"created_at": "2018-09-01T16:41:53.513Z","updated_at": "2022-09-05T10:17:39.392Z","url": "http://localhost:3000/beers/3.json"},{"id":5,"name": "X Porter","style":{"id":3,"name": "Baltic Porter","description": "Porters of the late 1700's were quite strong compared to today�'s standards, easily surpassing 7 percent alcohol by volume. Some English brewers made a stronger, more robust version, to be shipped across the North Sea that they dubbed a Baltic Porter. In general, the style'�s dark brown color covered up cloudiness and the smoky, roasted brown malts and bitter tastes masked brewing imperfections. Historically, the addition of stale ale also lent a pleasant acidic flavor to the style, which made it quite popular. These issues were quite important given that most breweries at the time were getting away from pub brewing and opening up production facilities that could ship beer across the world.","created_at": "2022-09-05T10:17:39.360Z","updated_at": "2018-09-22T12:08:13.953Z"},"brewery_id":2,"created_at": "2018-09-01T16:41:53.519Z","updated_at": "2022-09-05T10:17:39.400Z","url": "http://localhost:3000/beers/5.json"}]Json-muotoisen sivun saa hieman luettavampaan muotoon esim. kopioimalla sivun sisällön jsonlint palveluun:
Parempi ratkaisu on asentaa selaimeen jsonia ymmärtävä plugin, eräs suositeltava on chromen jsonview, plugin muotoilee jsonin selaimeen todella siististi:
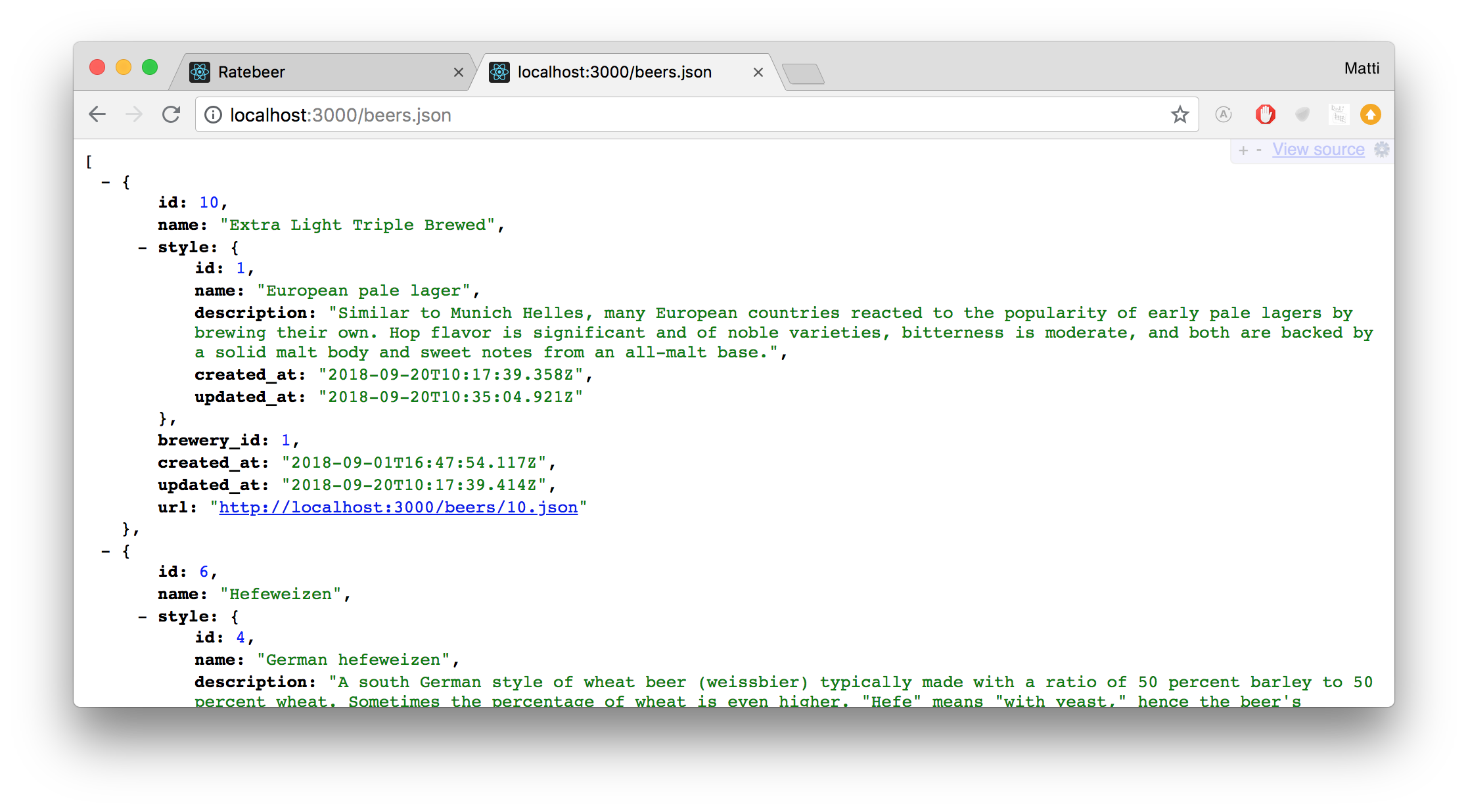
Tarkemmin tarkasteltuna jokainen yksittäinen json-muotoinen olut muistuttaa hyvin paljon Rubyn hashiä:
{
"id":10,"name": "Extra Light Triple Brewed",
"style":{
"id":1,"name": "European pale lager",
"description": "Similar to Munich Helles, many European countries reacted to the popularity of early pale lagers by brewing their own. Hop flavor is significant and of noble varieties, bitterness is moderate, and both are backed by a solid malt body and sweet notes from an all-malt base.",
"created_at": "2022-09-05T10:17:39.358Z",
"updated_at": "2022-09-05T10:35:04.921Z"
},
"brewery_id":1,
"created_at": "2018-09-01T16:47:54.117Z",
"updated_at": "2022-09-05T10:17:39.414Z","url": "http://localhost:3000/beers/10.json"}Minkä takia Rails osaa tarvittaessa palauttaa resurssit HTML:n sijaan jsonina?
Yritetään saada kaikkien reittausten lista jsonina, eli kokeillaan osoitetta http://localhost:3000/ratings.json
Seurauksena on virheilmoitus:
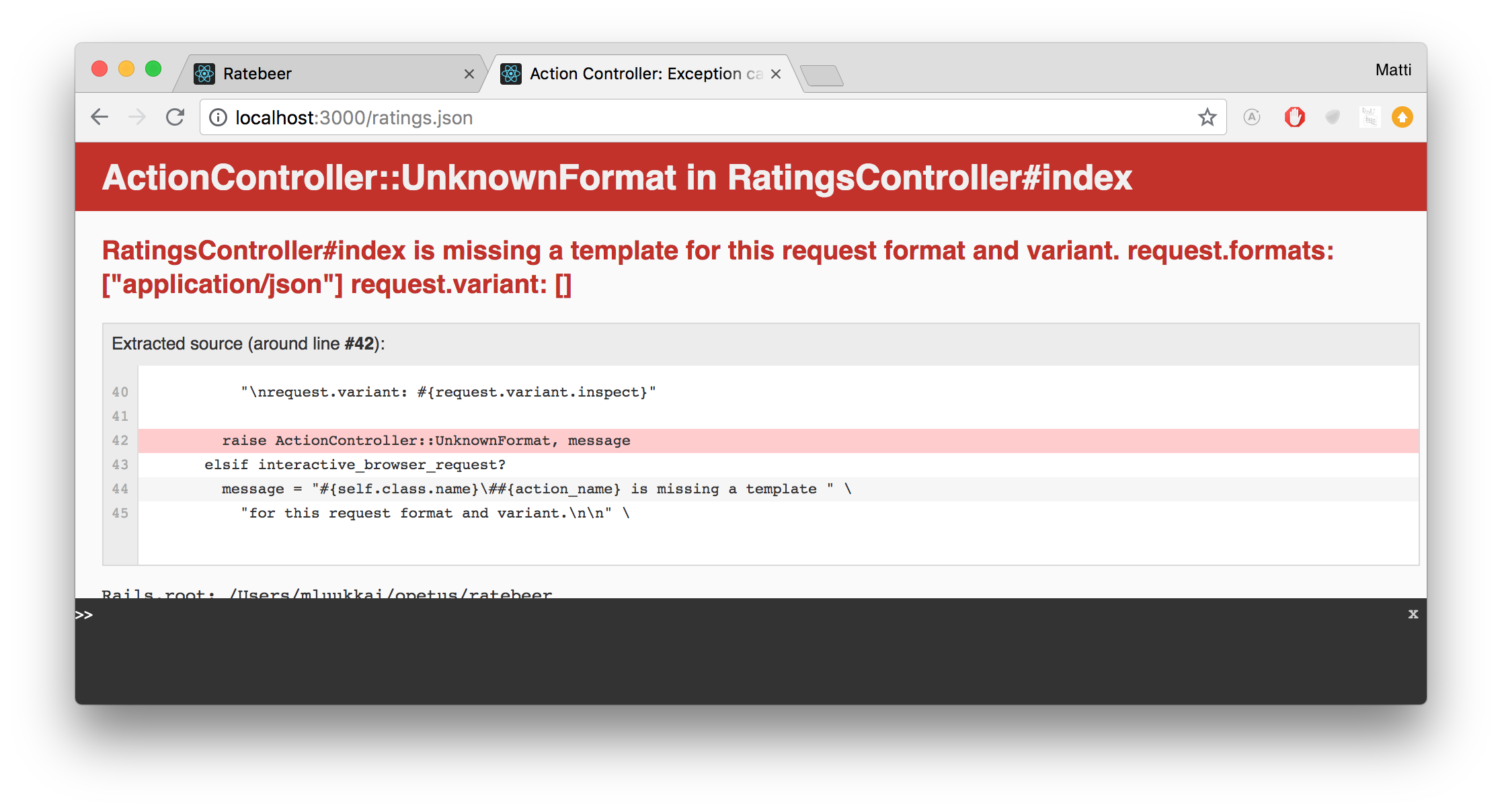
Eli ihan automaattisesti jsonit eivät synny, loimme kaiken reittaukseen liittyvän koodin käsin, ja kuten virheilmoituksesta voimme päätellä, formaatille 'json' ei ole olemassa sopivaa templatea.
Huomaamme, että scaffoldilla luotujen resurssien, esim. oluen views-hakemistosta löytyy joukko json.jbuilder-päätteisiä templateja, ja kuten arvata saattaa, käyttää Rails näitä jos resurssi halutaan json-muotoisena.
Ottamalla mallia templatesta app/views/beers/index.json.jbuilder teemme reittauksille seuraavan json.jbuilder-templaten (tiedosto on siis app/views/ratings/index.json.jbuilder):
json.array! @ratings, partial: "ratings/rating", as: :ratingTämän lisäksi tarvitsemme reittauksille myös partial-tiedoston. Otamme myös tähän mallia oluiden templatesta app/views/beers/_beer.json.jbuilder (ja luomme tiedoston app/views/ratings/_rating.json.jbuilder):
json.extract! rating, :id, :score
json.url rating_url(rating, format: :json)ja nyt saamme reittaukset jsonina osoitteesta http://localhost:3000/ratings.json
[{"id":31,"score":34},{"id":30,"score":42},{"id":27,"score":40},{"id":25,"score":12},{"id":24,"score":10}]HUOM: jbuilder-templatessa käytettävän muuttujan @ratings tulee olla määritelty kontrollerin metodissa index, viime viikon refaktorointien myötä se ei ole enää määritelty.
Voisimme helposti määritellä json.jbuilder-templatessa, että reittausten json-esitykseen sisällytetään myös reittausta koskevan oluen tiedot:
json.extract! rating, :id, :score, :beer
json.url rating_url(rating, format: :json)Lisää jbuilderista seuraavassa https://github.com/rails/jbuilder
Json-jbuilder-templatejen ohella toinen tapa palauttaa json-muotoista dataa olisi käytää respond_to-komentoa, jota muutamat scaffoldienkin generoivat metodit käyttävät. Tällöin json-jbuilder-templatea ei tarvittaisi ja kontrolleri näyttäisi seuraavalta
def index
@ratings = Rating.all
respond_to do |format|
format.html { } # renderöidään oletusarvoinen template
format.json { render json: @ratings }
end
endJbuilder-templatejen käyttö on kuitenkin ehdottomasti parempi vaihtoehto, tällöin json-muotoisen "näytön" eli resurssin representaation muodostaminen eriytetään täysin kontrollerista. Ei ole kontrollerin vastuulla muotoilla vastauksen ulkoasua oli kyseessä sitten json- tai HTML-muotoinen vastaus.
Palataan oluiden sivun pariin. Kun muodostamme sivun JavaScriptillä, ideana onkin hakea palvelimelta nimenomaan oluet json-muodossa ja renderöidä ne sitten sopivasti JavaScriptin avulla.
Muokataan JavaScript-koodiamme seuraavasti:
const handleResponse = (data) => {
document.getElementById("beers").innerText = `oluita löytyi ${data.length}`;
};
const beers = () => {
fetch("beers.json")
.then((response) => response.json())
.then(handleResponse);
};
export { beers };hello-funktio nimetään uudelleen beers nimiseksi (HUOM: muista vaihtaa funktion nimi myös exportissa, sekä application.js tiedoston importissa!).
beers-funktio hakee selaimella käytössä olevan fetch-funktion avulla json-muotoiset oluet osoitteesta osoitteesta beers.json. Fetchin palauttamaan dataan päästään käsiksi kutsumalla metodia then kaksi kertaa. Ensimmäinen kutsu saa aikaan sen, että selaimelle palautetusta datasta parsitaan erilleen oluet json-muodossa. Toinen then-kutsu pyytää funktiota handleResponse käsittelemään datan. Funktio handleResponse lisää sivulle oluiden lukumäärä. JavaScriptissä pystytään yhdistämään tekstiä ja muuttujia Rubyn tapaan, tosin JavaScriptissä käytetään dollarisymbolia sekä normaalien heittomerkkien sijaan `-merkkiä.
Hieman oudonnäköisen then-syntaksin taustalla on se, että funktio fetch palauttaa ns. promisen ja varsinainen palautettu data täytyy ottaa promisen sisältä then-funktion avulla.
Funktion pitäisi siis saatuaan oluet palvelimelta muodostaa ne listaava HTML-koodi ja lisätä se sivulle.
Muutetaan JavaScript-koodiamme siten, että se listaa aluksi ainoastaan oluiden nimet:
const handleResponse = (beers) => {
const beerList = beers.map((beer) => `<li>${beer.name}</li>`);
document.getElementById("beers").innerHTML = `<ul> ${beerList.join("")} </ul>`;
};Koodi määrittelee paikallisen taulukkomuuttujan beerList ja käy läpi parametrina saamansa oluiden listan beers. Käyttämällä map-funktiota voimme muodostaa uuden taulukon suoraan funktion palautusarvosta. Jokaista olutta kohti beerList:iin palautetaan HTML-elementti, joka on muotoa
<li>Extra Light Triple Brewed</li>Lopuksi listan alkuun ja loppuun lisätään ul-tagit ja listan alkiot liitetään yhteen join-metodilla. Näin saatu HTML-koodi liitetään id:n beers omaavaan elementtiin.
Nyt siis saimme yksinkertaisen listan oluiden nimistä sivulle.
Entä jos haluaisimme järjestää oluet? Jotta tämä onnistuu, refaktoroimme koodin ensin seuraavanlaiseksi:
const BEERS = {};
const handleResponse = (beers) => {
BEERS.list = beers;
BEERS.show();
};
BEERS.show = () => {
const beerList = BEERS.list.map((beer) => `<li>${beer.name}</li>`);
document.getElementById("beers").innerHTML = `<ul> ${beerList.join("")} </ul>`;
};Määrittelimme nyt olion BEERS, jonka attribuuttiin BEERS.list palvelimelta saapuva oluiden lista sijoitetaan. Metodi BEERS.show muodostaa BEERS.list:in oluista HTML-listan ja sijoittaa sen näytölle.
Näin muotoiltuna palvelimelta haettu oluiden lista jää "muistiin" selaimeen muuttujaan BEERS.list ja lista voidaan tarpeen tullen uudelleenjärjestää ja näyttää käyttäjälle uudessa järjestyksessä ilman että www-sivun tarvitsee ollenkaan kommunikoida palvelimen kanssa.
Lisätään sivulle teksti, jota painamalla oluet saadaan sivulle käänteiseen järjestykseen:
<p id="reverse">reverse!</p>
<div id="beers"></div>Lisätään sitten JavaScriptillä linkille klikkauksenkäsittelijä, joka linkkiä klikatessa laittaa oluet käänteiseen järjestykseen ja näyttää ne sivun beers-elementissä:
BEERS.reverse = () => {
BEERS.list.reverse();
};
const beers = () => {
document.getElementById("reverse").addEventListener("click", (e) => {
e.preventDefault();
BEERS.reverse();
BEERS.show();
});
fetch("beers.json")
.then((response) => response.json())
.then(handleResponse);
};
export { beers };Tekstin klikkauksen käsittelijä siis määritellään sivun beers funktiossa, eli kun dokumentti on latautunut, rekisteröidään klikkausten käsittelijäfunktio id:n "reverse" omaavalle elementille.
Kun linkkiä klikataan, tapahtumankäsittelijä kutsuu aluksi metodia e.preventDefault, joka estää klikkauksen "normaalin" toiminnallisuuden eli (nyt olemattoman) linkin seuraamisen. Tämän jälkeen kutsutaan metodeita reverse ja show piirtämään oluet ruudulle käänteisessä järjestysessä.
Nyt ymmärrämme riittävästi perusteita ja olemme valmiina toteuttamaan todellisen toiminnallisuuden.
Muutetaan näkymää seuraavasti:
<h2>Beers</h2>
<table id="beertable" class="table table-hover">
<thead>
<tr>
<th> <span id="name">Name</span> </th>
<th> <span id="style">Style</span> </th>
<th> <span id="brewery">Brewery</span> </th>
</tr>
<thead>
<tbody>
<div id="beerlist"></div>
</tbody>
</table>Eli kolmesta sarakenimestä on tehty elementti, joihin tullaan rekisteröimään klikkauksenkuuntelijat. Taulukolle on annettu id beertable.
Muutetaan sitten JavaScriptissä määriteltyä metodia show siten, että se laittaa oluiden nimet taulukkoon:
const createTableRow = (beer) => {
const tr = document.createElement("tr");
const beername = tr.appendChild(document.createElement("td"));
beername.innerHTML = beer.name;
return tr;
};
BEERS.show = () => {
const table = document.getElementById("beertable");
BEERS.list.forEach((beer) => {
const tr = createTableRow(beer);
table.appendChild(tr);
});
};Eli ensin koodi tallettaa viitteen taulukkoon muuttujana table. Tämän jälkeen luodaan createTableRow-apufunktion avulla tr-elementtejä joiden sisälle tulee taulukon solut td. Rivi palautetaan takaisin forEach-looppiin jossa ne asetetaan taulukon "lapsiksi" käyttämällä appendChild-metodia.
Laajennetaan sitten metodia näyttämään kaikki tiedot oluista. Huomaamme kuitenkin, että oluiden json-muotoisessa listassa http://localhost:3000/beers.json ei ole panimosta muuta tietoa kuin olioiden id:t, haluaisimme kuitenkin näyttää panimon nimen. Oluttyylin tiedot löytyvät kokonaisuudessaan jsonista jo nyt.
Ongelma on onneksi helppo ratkaista muokkaamalla oluiden listan tuottavaa json-jbuildertemplatea. Template näyttää nyt seuraavalta:
json.array! @beers, partial: 'beers/beer', as: :beerTemplate määrittelee, että jokaisesta oluesta muodostetaan json-esitys tiedoston _beer.json.jbuilder avulla, tiedoston sisältö on seuraava
json.extract! beer, :id, :name, :style, :brewery_id, :created_at, :updated_at
json.url beer_url(beer, format: :json)Tiedosto määrittelee, että yksittäisen oluen jsoniin sisällytetään kentät id, name ja brewery_id sekä style joka taas viittaa olueeseen liittyvään Style-olioon. Tyyliolio tuleekin renderöityä oluen json-esityksen sisälle kokonaisuudessaan. Saamme myös panimon json-esityksen oluen jsonin mukaan jos korvaamme templatessa brewery_id:n brewery:llä. Muutamme siis yksittäisen oluen jsonin renderöinnistä vastaavan templaten seuraavaan muotoon:
json.extract! beer, :id, :name, :style, :brewerypoistimme viimeisen rivin joka lisäsi jokaisen oluen json-esityksen mukaan urlin oluen omaan json-esitykseen, poistimme myös aikaleimakentät.
Nyt saamme taulukon generoitua lisäämällä seuraavat rivit createTableRow-funktioon:
const createTableRow = (beer) => {
const tr = document.createElement("tr");
tr.classList.add("tablerow");
const beername = tr.appendChild(document.createElement("td"));
beername.innerHTML = beer.name;
const style = tr.appendChild(document.createElement("td"));
style.innerHTML = beer.style.name;
const brewery = tr.appendChild(document.createElement("td"));
brewery.innerHTML = beer.brewery.name;
return tr;
};Oluiden listan json-esityksen mukana tulee nyt paljon tarpeetontakin tietoa sillä mukaan renderöityvät jokaisen oluen panimon ja tyylin json-esitykset kokonaisuudessaan. Voisimme optimoida yksittäisen oluen json-esityksen generoivaa templatea siten, että oluen panimosta ja tyylistä tulee json-esitykseen mukaan ainoastaan nimi:
json.extract! beer, :id, :name
json.style do
json.name beer.style.name
end
json.brewery do
json.name beer.brewery.name
endNyt palvelimen lähettämä oluiden jsonmuotoinen lista on huomattavasti inhimillisemmän kokoinen:
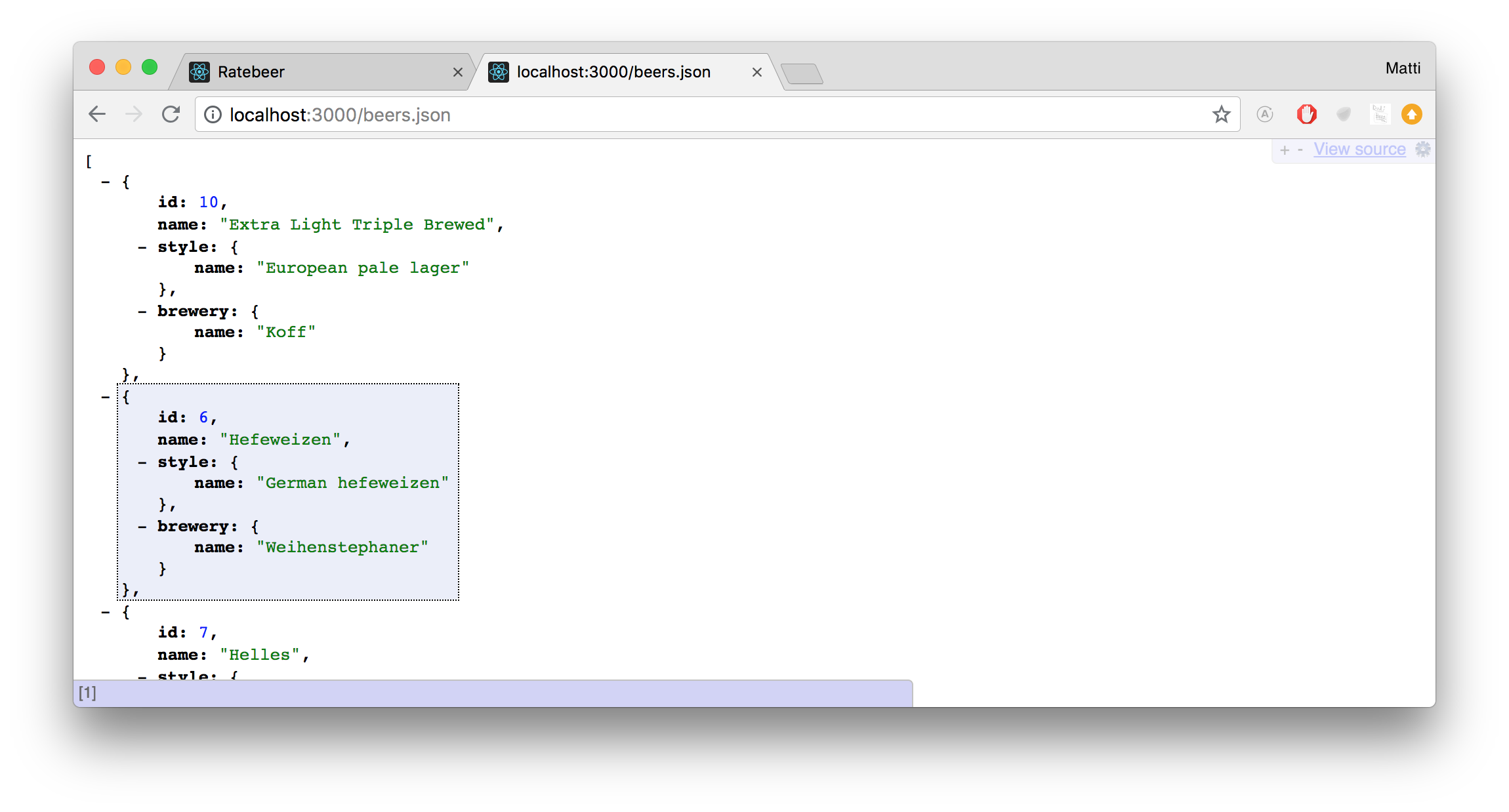
Rekisteröimme vielä järjestämisen suorittavat tapahtumankuuntelijat linkeille (seuraavassa lopullinen JavaScript-koodi):
const BEERS = {};
const handleResponse = (beers) => {
BEERS.list = beers;
BEERS.show();
};
const createTableRow = (beer) => {
const tr = document.createElement("tr");
tr.classList.add("tablerow");
const beername = tr.appendChild(document.createElement("td"));
beername.innerHTML = beer.name;
const style = tr.appendChild(document.createElement("td"));
style.innerHTML = beer.style.name;
const brewery = tr.appendChild(document.createElement("td"));
brewery.innerHTML = beer.brewery.name;
return tr;
};
BEERS.show = () => {
document.querySelectorAll(".tablerow").forEach((el) => el.remove());
const table = document.getElementById("beertable");
BEERS.list.forEach((beer) => {
const tr = createTableRow(beer);
table.appendChild(tr);
});
};
BEERS.sortByName = () => {
BEERS.list.sort((a, b) => {
return a.name.toUpperCase().localeCompare(b.name.toUpperCase());
});
};
BEERS.sortByStyle = () => {
BEERS.list.sort((a, b) => {
return a.style.name.toUpperCase().localeCompare(b.style.name.toUpperCase());
});
};
BEERS.sortByBrewery = () => {
BEERS.list.sort((a, b) => {
return a.brewery.name
.toUpperCase()
.localeCompare(b.brewery.name.toUpperCase());
});
};
const beers = () => {
document.getElementById("name").addEventListener("click", (e) => {
e.preventDefault;
BEERS.sortByName();
BEERS.show();
});
document.getElementById("style").addEventListener("click", (e) => {
e.preventDefault;
BEERS.sortByStyle();
BEERS.show();
});
document.getElementById("brewery").addEventListener("click", (e) => {
e.preventDefault;
BEERS.sortByBrewery();
BEERS.show();
});
fetch("beers.json")
.then((response) => response.json())
.then(handleResponse);
};
export { beers };Tapahtumakuuntelijoita kutsuessa lisätään uudessa järjestyksessä olevat BEERS.list alkiot taulukkoon olemassaolevien jatkoksi. Korjataan tämä lisäämällä BEERS.show-funktion alkuun rivi, jossa haetaan olemassaolevat tablerow-luokalla varustetut rivit ja poistetaan ne.
JavaScript-koodimme tulee liitetyksi sovelluksen jokaiselle sivulle. Tästä on se ikävä seuraus, että ollaanpa millä sivulla tahansa, suorittaa JavaScript beers-funktion. Myös tapahtumakunntelijat yritetään rekisteröidä jokaiselle sivulle vaikka niiden rekisteröinti on mielekästä ainoastaan jos ollaan oluiden listalla.
Viritellään JavaScript-koodia vielä siten, että beers-funktion koodi suoritetaan ainoastaan jos ollaan sivulla, josta taulukko beertable löytyy:
const beers = () => {
if (document.querySelectorAll("#beertable").length < 1) return;
//...
var request = new XMLHttpRequest();
request.onload = handleResponse;
request.open("get", "beers.json", true);
request.send();
};Jos sivulta ei löydy beertable-id:llä olevaa elementtiä ei funktion suoritusta jatketa. Sovellusta tehdessä kannattaakin pitää mielessä, että id:n on tarkoitus olla yksilöivä tieto eli niitä ei yhdessä sovelluksessa saa olla kahta samanlaista!
Tällä hetkellä trendinä siirtää yhä suurempi osa web-sivujen toiminnallisuudesta selaimeen. Etuna mm. se että web-sovelluksien toiminta saadaan muistuttamaan yhä enenevissä määrin desktop-sovelluksia.
Äsken JavasSriptillä toteuttamamme oluet listaava sivu oli koodin rakenteen puolesta ihan kohtuullista, mutta Railsin sujuvuuteen ja vaivattomuuteen verrattuna koodi oli raskaahkoa ja paikoin ikävien, rutiininomaisten yksityiskohtien täyttämää. Jos sovelluksen selainpuolella toteutettavan koodin määrä alkaa kasvaa, on lopputuloksena helposti sekava koodi, jonka toiminnasta kukaan ei enää ota selvää ja jonka laajentaminen muuttuu erittäin haastavaksi.
JavaScript-frontendsovelluskehykset tuovat asiaan helpotusta. Pitkään jo suosiota nauttinut ja edelleen suosituin ratkaisu frontendien tekemiseen on Facebookin kehittämä React. React on laaja aihe ja pääset syventymään siihen laitoksen kurssilla Full Stack -websovelluskehitys joka järjestetään nyt menossa olevana avoimen yliopiston kurssina.
Toteuta edellisten esimerkkien tyyliin JavaScriptillä kaikki panimot listaava sivu http://localhost:3000/brewerylist
Sivulla näytetään jokaisesta panimosta nimi, perustusvuosi, panimon valmistamien oluiden lukumäärä ja tieto siitä onko panimo lopettanut. Sivun siis ei tarvitse eritellä lopettaneita panimoita omaan taulukkoonsa.
Panimoiden järjestäminen toteutetaan vasta seuraavassa tehtäässä.
Muista pitää JavaScript-konsoli koko ajan auki tehtävää tehdessäsi! Voit debugata Javasriptia tulostelemalla konsoliin komennolla
console.log()HUOM: edellisellä viikolla tekemämme muutoksen takia panimoiden json-lista http://localhost:3000/breweries.json ei toimi, sillä breweries#index-kontrolleri ei enää aseta kaikkien panimoiden listaa muuttujaan
@breweries. Korjaa tilanne.HUOM2: tehtävä kannattaa tehdä yksi pieni askel kerrallaan, samaan tapaan kuin oluiden lista tehtiin yllä olevassa esimerkissä. JavaScriptin debuggaus saattaa olla haasteellista ja varmin tapa aiheuttaa iso turhautuma onkin yrittää tehdä tehtävä nopeasti copypasteamalla beerlistin koodi.
Laajenna panimoiden listaa siten, että panimot voi järjestää joko aakkos- tai perustamisvuoden mukaiseen järjestykseen tai panimon valmistamien oluiden lukumäärän perusteella.
Tehdään rspec/capybaralla muutama testi JavaScriptillä toteutetulle oluiden listalle. Seuraavassa on lähtökohtamme, tiedosto spec/features/beerlist_page_spec.rb:
require 'rails_helper'
describe "Beerlist page" do
before :all do
Capybara.register_driver :selenium do |app|
Capybara::Selenium::Driver.new(app, :browser => :chrome)
end
end
before :each do
@brewery1 = FactoryBot.create(:brewery, name: "Koff")
@brewery2 = FactoryBot.create(:brewery, name: "Schlenkerla")
@brewery3 = FactoryBot.create(:brewery, name: "Ayinger")
@style1 = Style.create name: "Lager"
@style2 = Style.create name: "Rauchbier"
@style3 = Style.create name: "Weizen"
@beer1 = FactoryBot.create(:beer, name: "Nikolai", brewery: @brewery1, style:@style1)
@beer2 = FactoryBot.create(:beer, name: "Fastenbier", brewery:@brewery2, style:@style2)
@beer3 = FactoryBot.create(:beer, name: "Lechte Weisse", brewery:@brewery3, style:@style3)
end
it "shows one known beer" do
visit beerlist_path
expect(page).to have_content "Nikolai"
end
endSuoritetaan testi komennolla rspec spec/features/beerlist_page_spec.rb. Tuloksena on kuitenkin virheilmoitus:
1) Beerlist page shows one known beer
Failure/Error: expect(page).to have_content "Nikolai"
expected to find text "Nikolai" in "breweries beers styles ratings users clubs places signin signup\nyou should be signed in\nSign in\nusername password"
# ./spec/features/beerlist_page_spec.rb:18:in `block (2 levels) in <top (required)>'
Finished in 21.17 seconds (files took 5.33 seconds to load)
1 example, 1 failureNäyttää siis siltä että sivulla ei ole ollenkaan oluiden listaa. Varmistetaan tämä laittamalla testiin juuri ennen komentoa expect komento save_and_open_page jonka avulla saamme siis avattua selaimeen sivun jolle capybara on navigoinut
(ks. https://github.com/mluukkai/WebPalvelinohjelmointi2022/blob/main/web/viikko4.md#capybarav4#capybara).
Ja aivan kuten arvelimme, sivulla näytettävä oluttaulukko on tyhjä:
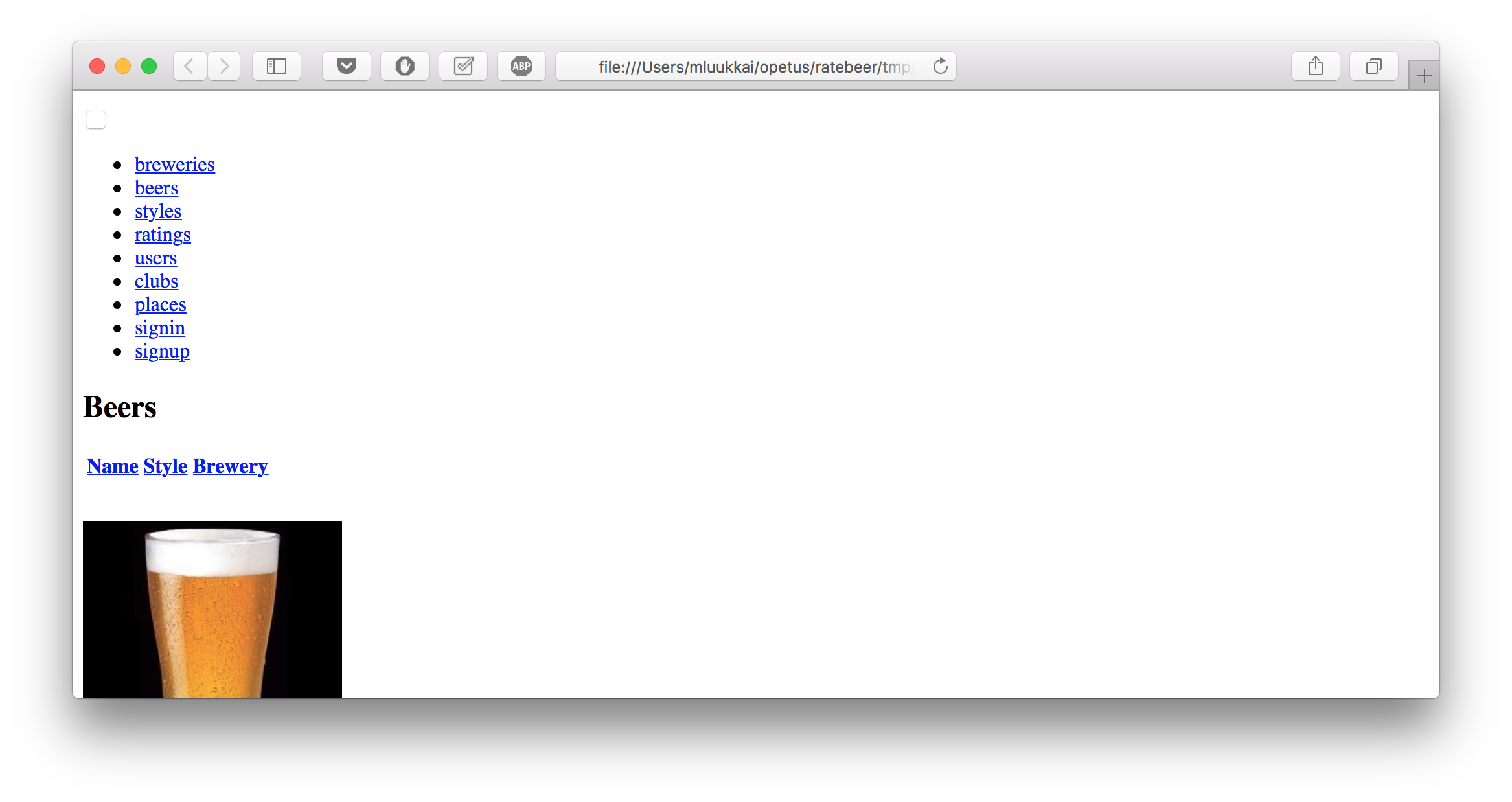
Syy ongelmalle löytyy capybaran dokumentaatiosta https://github.com/jnicklas/capybara#drivers
By default, Capybara uses the :rack_test driver, which is fast but limited: it does not support JavaScript, nor is it able to access HTTP resources outside of your Rack application, such as remote APIs and OAuth services. To get around these limitations, you can set up a different default driver for your features.
Ja korjauskin on helppo. JavaScriptiä tarvitseviin testeihin riittää lisätä parametri, jonka ansiosta testi suoritetaan JavaScriptiä osaavan Selenium-testiajurin avulla:
it "shows the known beers", js:true doKun suoritamme testit, törmäämme virheilmoitukseen
1) Beerlist page shows one known beer
Failure/Error: visit beerlist_path
WebMock::NetConnectNotAllowedError:
Real HTTP connections are disabled. Unregistered request: GET http://127.0.0.1:52187/__identify__ with headers {'Accept'=>'*/*', 'Accept-Encoding'=>'gzip;q=1.0,deflate;q=0.6,identity;q=0.3', 'User-Agent'=>'Ruby'}
You can stub this request with the following snippet:
stub_request(:get, "http://127.0.0.1:52187/__identify__").
with(
headers: {
'Accept'=>'*/*',
'Accept-Encoding'=>'gzip;q=1.0,deflate;q=0.6,identity;q=0.3',
'User-Agent'=>'Ruby'
}).
to_return(status: 200, body: "", headers: {})
============================================================Virheen syy on siinä, että otimme viikolla 5 käyttöömme WebMock-gemin joka oletusarvoisesti kieltää testikoodin suorittamat HTTP-yhteydet. JavaScriptilla toteutettu olutlistahan yrittää hakea oluiden listan json-muodossa palvelimelta. Pääsemme virheestä eroon sallimalla yhteydet, esim. muuttamalla testit alustavaan before :all -lohkoa seuraavasti:
before :all do
Capybara.register_driver :selenium do |app|
Capybara::Selenium::Driver.new(app, :browser => :chrome)
end
WebMock.allow_net_connect!
endTesti toimii vihdoin.
Kun sivuille luodaan sisältöä JavaScriptillä, ei sisältö ilmesty sivulle vielä samalla hetkellä kuin sivun html-pohja ladataan vaan vasta javascript takaisinkutsufunktion suorituksen jälkeen. Eli jos katsomme sivun sisältöä välittömästi sivulle navigoinnin jälkeen, ei JavaScript ole vielä ehtinyt muodostaa sivun lopullista sisältöä. Esim. seuraavassa save_and_open_page saattaa avata sivun, jossa ei vielä näy yhtään olutta:
it "shows a known beer", js:true do
visit beerlist_path
save_and_open_page
expect(page).to have_content "Nikolai"
endKuten sivulla https://github.com/jnicklas/capybara#asynchronous-javascript-ajax-and-friends sanotaan, osaa Capybara odottaa asynkroonisia JavaScript-kutsuja sen verran, että testien sivulta etsimät elementit ovat latautuneet.
Tiedämme, että JavaScriptin pitäisi lisätä sivun taulukkoon rivejä. Saammekin sivun näkymään oikein, jos lisäämme alkuun komennon find('table').find('tr:nth-child(2)') joka etsii sivulta taulukon ja sen sisältä toisen rivin (taulukon ensimmäinen rivihän on jo sivupohjassa mukana oleva taulukon otsikkorivi):
it "shows a known beer", :js => true do
visit beerlist_path
find('table').find('tr:nth-child(2)')
save_and_open_page
expect(page).to have_content "Nikolai"
endNyt capybara odottaa taulukon valmistumista ja siirtyy sivun avaavaan komentoon vasta taulukon latauduttua (itseasiassa vain 2 riviä taulukkoa on varmuudella valmiina).
Testien suorittaminen todellisessa selaimella on melko hidasta. Saat nopeutettua testejä käyttämällä Chromen Headless- moodia, eli "käyttöliittymätöntä versiota". Headless-selaimen käyttöönotto onnistuu muuttamalla before :all -lohko muotoon
before :all do
Capybara.register_driver :chrome do |app|
Capybara::Selenium::Driver.new app, browser: :chrome,
options: Selenium::WebDriver::Chrome::Options.new(args: %w[headless disable-gpu])
end
Capybara.javascript_driver = :chrome
WebMock.disable_net_connect!(allow_localhost: true)
endKonfiguraation muutoksen jälkeen suoritus normaalilla selaimella onnistuu tyhjentämällä Options.new() sisältö.
Tee testi joka varmistaa, että oluet ovat beerlist-sivulla oletusarvoisesti nimen mukaan aakkosjärjestyksessä
Testaaminen kannattaa tehdä nyt siten, että etsitään taulukon rivit
find-selektorin avulla ja varmistetaan, että jokaisella rivillä on oikea sisältö. Koska taulukon jokaisella rivillä on olemassatablerow-luokka, löytyy ensimmäinen varsinainen rivi seuraavasti:find('#beertable').first('.tablerow')Rivin sisältöä voi testata normaaliin tapaan expect ja have_content -metodeilla. Capybaran komento find palauttaa Node-tyyppisen olion, katso linkin takaa vihjeitä miten Nodea käsitellään.
Tee testit seuraaville toiminnallisuuksille
- klikattaessa saraketta 'style' järjestyvät oluet tyylin nimen mukaiseen aakkosjärjestykseen
- klikattaessa saraketta 'brewery' järjestyvät oluet panimon nimen mukaiseen aakkosjärjestykseen
Rails-sovelluksiin liittyviä JavaScript- ja tyylitiedostoja (ja kuvia) hallitaan ns. Asset pipelinen avulla, ks. https://guides.rubyonrails.org/asset_pipeline.html
Periaatteena on se, että sovelluskehittäjä sijoittaa sovellukseen liittyvät JavaScript-tiedostot hakemistoon app/assets/javascripts ja tyylitiedostot hakemistoon app/assets/stylesheets. Molempia voidaan sijoittaa useaan eri tiedostoon, ja tarvittaessa alihakemistoihin.
Sovellusta kehitettäessä (eli kun sovellus on ns. development-moodissa) Rails liittää kaikki (ns. manifest-tiedostossa) määritellyt JavaScript- ja tyylitiedostot mukaan sovellukseen. Huomaammekin tarkastellessamme sovellusta selaimen view source -ominaisuuden avulla, että mukaan on liitetty suuri joukko JavaScriptiä ja tyylitiedostoja.
Sovelluksen mukaan liitettävät JavaScript-tiedostot määritellään tiedostossa app/assets/javascripts/application.js, jonka sisältö on nyt seuraava
//= require jquery3
//= require popper
//= require bootstrap-sprockets
import "@hotwired/turbo-rails";
import "controllers";
import { beertable } from "custom/utils";
beertable();Vaikka tiedostossa olevat requiret näyttävät olevan kommenteissa, on kuitenkin kyse "oikeista", asset pipelinestä huolehtivan sprockets-kääntäjän komennoista, joiden avulla määritellään sovellukseen mukaan otettavat JavaScript-tiedostot. Tiedosto määrittelee, että mukaan otetaan jquery3, popper, bootstrap-sprockets. Kaikki näistä on asennettu sovellukseen gemien avulla.
Tuotantokäytössä sovelluksella ei suorituskykysyistä yleensä kannata olla useampia JavaScript- tai tyylitiedostoja. Kun sovellusta aletaan suorittaa tuotantoympäristössä (eli production-moodissa), sprockets yhdistääkin kaikki sovelluksen JavaScript- ja tyylitiedostot yksittäisiksi, optimoiduiksi tiedostoiksi. Huomaamme tämän jos katsomme herokussa olevan sovelluksen html-lähdekoodia, esim: https://ratebeer22.fly.dev/ sisältää se nyt ainoastaan yhden js- ja yhden css-tiedoston joista varsinkin js-tiedoston luettavuus on ihmisen kannalta heikko.
Lisää asset pipelinestä ja mm. JavaScriptin liittämisestä railssovelluksiin mm. seuraavissa:
- http://railscasts.com/episodes/279-understanding-the-asset-pipeline
- http://railsapps.github.io/rails-javascript-include-external.html
Tehtävä on hieman työläs, joten tee ensin helpommat pois alta. Muut viikon tehtävät eivät riipu tästä tehtävästä.
Toistaiseksi kuka tahansa voi sovelluksessamme liittyä olutkerhon jäseneksi. Muutetaan nyt sovellusta siten, että jäsenyys ei tule voimaan ennenkuin joku jo jäsenenä oleva vahvistaa jäsenyyden.
Muutamia huomioita
- jäsenyyden vahvistamattomuus kannattaa huomioida siten, että Membership-modeliin lisätään boolean-arvoinen kenttä confirmed
- Kun kerho luodaan, tee sen luoneesta käyttäjästä automaattisesti kerhon jäsen
- Näytä kerhon sivulla jäsenille lista vahvistamattomana olevista jäsenyyksistä (eli jäsenhakemuksista)
- Jäsenyyden statuksen muutos voidaan hoitaa esim. oman custom-reitin avulla.
Tehtävä saattaa olla hieman haastava. Active Record Associations -guiden luku 4.3.3 Scopes for has_many tarjoaa erään hyvän työvälineen tehtävään. Tehtävän voi toki tehdä monella muullakin tavalla. Myös luku 4.3.2.3 :class_name voi olla hyödyksi.
Tehtävän jälkeen sovelluksesi voi näyttää esim. seuraavalta. Olutseuran sivulla näytetään lista jäsenyyttä hakeneista, jos kirjautuneena on olutseurassa jo jäsenenä oleva käyttäjä:
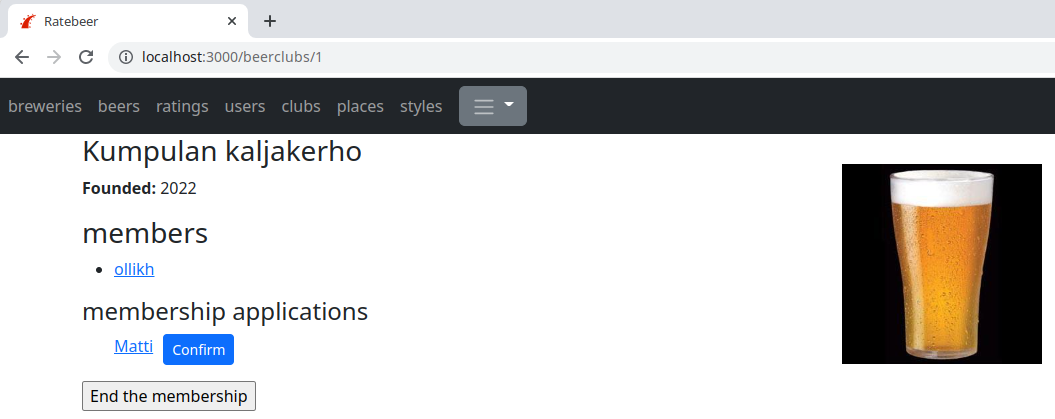
Käyttäjän omalla sivulta näytetään toistaiseksi käsittelemättömät hakemukset:
Kun käyttäjä kirjautuu järjestelmäämme, suoritetaan sessiokontrollerissa operaatio, jossa käyttäjäolio haetaan tietokannasta käyttäjän nimen perusteella:
class SessionsController < ApplicationController
def create
user = User.find_by username: params[:username]
# ...
end
endOperaation suorittamista varten tietokanta joutuu käymään läpi koko users-taulun. Haut olion id:n suhteen ovat nopeampia, sillä jokainen taulu on indeksöity id:iden suhteen. Indeksi toimii hajautustaulun tavoin, eli tarjoaa "O(1)"-ajassa toimivan pääsyn haettuun tietokannan riviin.
Tietokantojen tauluihin voidaan lisätä tarvittaessa muitakin indeksejä. Nopeutetaan users-taulusta tapahtuvaa käyttäjätunnuksen perusteella tehtävää hakua lisäämällä taululle indeksi.
Luodaan indeksiä varten migraatio
rails g migration AddUserIndexBasedOnUsername
Migraatio on seuraavanlainen:
class AddUserIndexBasedOnUsername < ActiveRecord::Migration[5.2]
def change
add_index :users, :username
end
endSuoritetaan migraatio komennolla rails db:migrate ja indeksi on valmis!
Indeksin huono puoli on se, että kun järjestelmään lisätään uusi käyttäjä tai olemassaoleva käyttäjä poistetaan, on indeksiä muokattava ja tähän luonnollisestsi kuluu aikaa. Indeksin lisäys on siis tradeoff sen suhteen, mitä operaatiota halutaan optimoida. Useimmissa tapauksissa tietokannasta lukuoperaatioita on niin paljon verrattuna kirjoitusoperaatioiden määrään, että indeksin hyödyt ylittävät ylivoimasti sen ylläpidosta koituvan lisätyön.
Kaikki oluet näyttävä kontrolleri on yksinkertainen. Oluet haetaan tietokannasta, järjestetään HTTP-kutsussa olleen parametrin määrittelemällä tavalla ja asetetaan templatea varten muuttujaan:
def index
@beers = Beer.all
order = params[:order] || 'name'
@beers = case order
when 'name' then @beers.sort_by(&:name)
when 'brewery' then @beers.sort_by{ |b| b.brewery.name }
when 'style' then @beers.sort_by{ |b| b.style.name }
end
endTemplate listaa oluet taulukkona:
<% @beers.each do |beer| %>
<tr>
<td><%= link_to beer.name, beer %></td>
<td><%= link_to beer.style, beer.style %></td>
<td><%= link_to beer.brewery.name, beer.brewery %></td>
</tr>
<% end %>
</table>Yksinkertaista ja tyylikästä... mutta ei kovin tehokasta.
Voisimme katsoa lokitiedostosta log/development.log mitä kaikkea oluiden sivulle mentäessä tapahtuu. Pääsemme samaan tietoon hieman mukavammassa muodossa käsiksi miniprofiler gemin (ks. https://github.com/MiniProfiler/rack-mini-profiler ja http://samsaffron.com/archive/2012/07/12/miniprofiler-ruby-edition)
Miniprofilerin käyttöönotto on helppoa, riittää että Gemfileen lisätään rivi
gem 'rack-mini-profiler'
Suorita bundle install ja käynnistä Rails server uudelleen. Kun menet tämän jälkeen osoitteeseen http://localhost:3000/beers huomaat, että sivun yläkulmaan ilmestyy aikalukema joka kuvaa HTTP-pyynnön suoritukseen käytettyä aikaa. Numeroa klikkaamalla avautuu tarkempi erittely ajankäytöstä:
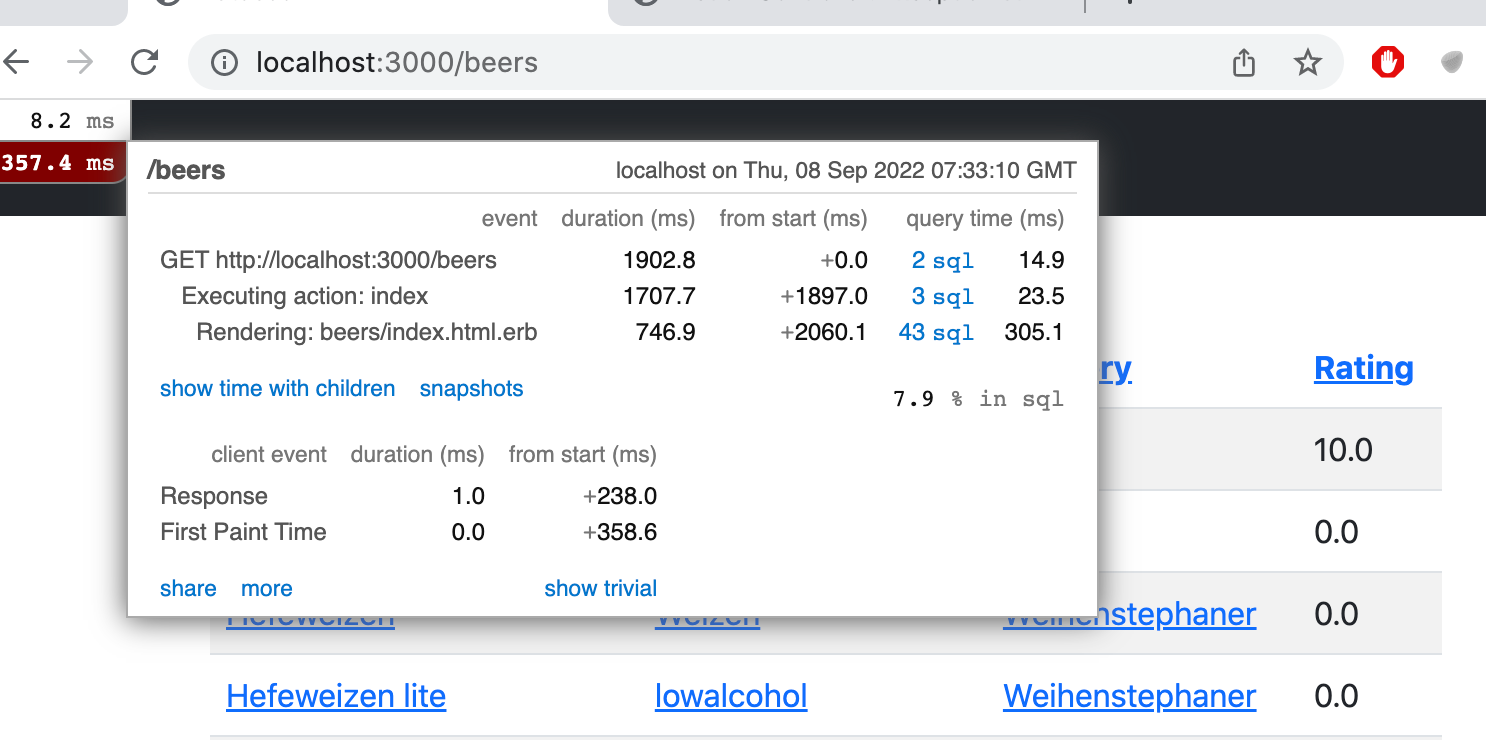
Raportti kertoo että Executing action: index eli kontrollerimetodin suoritus aiheuttaa muutaman SQL-kyselyn. Sen sijaan Rendering: beers/index eli näkymätemplaten suoritus aiheuttaa huomattavasti enemmän SQL-kyselyjä!
Kyselyjä klikkaamalla päästään tarkastelemaan syytä:
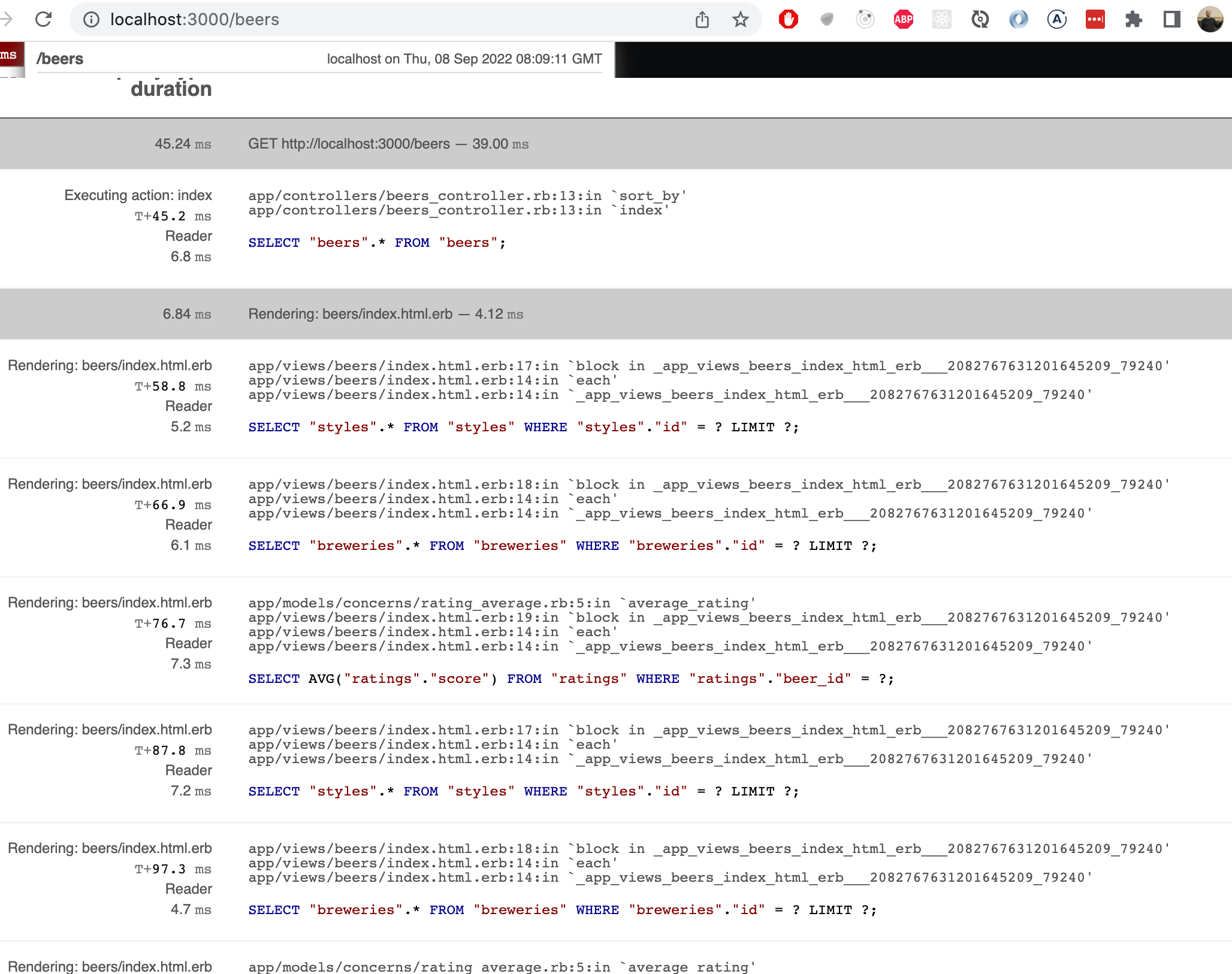
Tarkemman kuvan perusteella kontrolleri suorittaa aiemmasta raportista huolimatta kuitenkin vain yhden kyselyn
SELECT "beers".* FROM "beers";Näemme että näkymätemplaten renderöinti suorittaa useaan kertaan seuraavat kyselyt:
SELECT "styles".* FROM "styles" WHERE "styles"."id" = ? LIMIT ?;
SELECT "breweries".* FROM "breweries" WHERE "breweries"."id" = ? LIMIT ?;
SELECT AVG("ratings"."score") FROM "ratings" WHERE "ratings"."beer_id" = ?; Käytännössä jokaista erillistä olutta kohti tehdään oma kysely sekä styles- että breweries tauluun.
Syynä tälle on se, että Active Recordissa on oletusarvoisesti käytössä ns. lazy loading, eli kun haemme olion tietokannasta, olioon liittyvät kentät haetaan tietokannasta vasta jos niihin viitataan. Joskus tämä käyttäytyminen on toivottavaa, olioonhan voi liittyä suuri määrä olioita, joita ei välttämättä tarvita olion itsensä käsittelyn yhteydessä. Kaikkien oluiden sivulle mentäessä lazy loading ei kuitenkaan ole hyvä idea, sillä tiedämme varmuudella että jokaisen oluen yhteydessä näytetään myös oluen panimon sekä tyylin nimet ja nämä tiedot löytyvät ainoastaan panimoiden ja tyylien tietokantatauluista.
Voimme ohjata ActiveRecordin metodien parametrien avulla kyselyistä generoituvaa SQL:ää. Esim. seuraavasti voimme ohjeistaa, että oluiden lisäksi niihin liittyvät panimot tulee hakea tietokannasta:
def index
@beers = Beer.includes(:brewery).all
# ...
endMiniprofilerin avulla näemme. että kontrollerin suoritus aiheuttaa nyt kaksi kyselyä:
SELECT "beers".* FROM "beers";
SELECT "breweries".* FROM "breweries" WHERE "breweries"."id" IN (?, ?, ?, ?);Näyttötemplaten suoritus aiheuttaa kyselyjä, jotka ovat esimerkiksi muotoa:
SELECT "styles".* FROM "styles" WHERE "styles"."id" = ? LIMIT ?;
SELECT AVG("ratings"."score") FROM "ratings" WHERE "ratings"."beer_id" = ?; Näytön renderöinnin yhteydessä enää on haettava oluisiin liittyvät tyylit tietokannasta, kukin omalla SQL-kyselyllä.
Optimoidaan kontrolleria vielä siten, että myös kaikki tarvittavat tyylit ja reittaukset luetaan kerralla kannasta:
def index
@beers = Beer.includes(:brewery, :style, :ratings).all
# ...
endHuomaamme kuitenkin että vaikka kyselyjen määrä on vähentynyt, toistuu edelleen reittausten keskiarvon selvittävä kysely jokaisen oluen kohdalla:
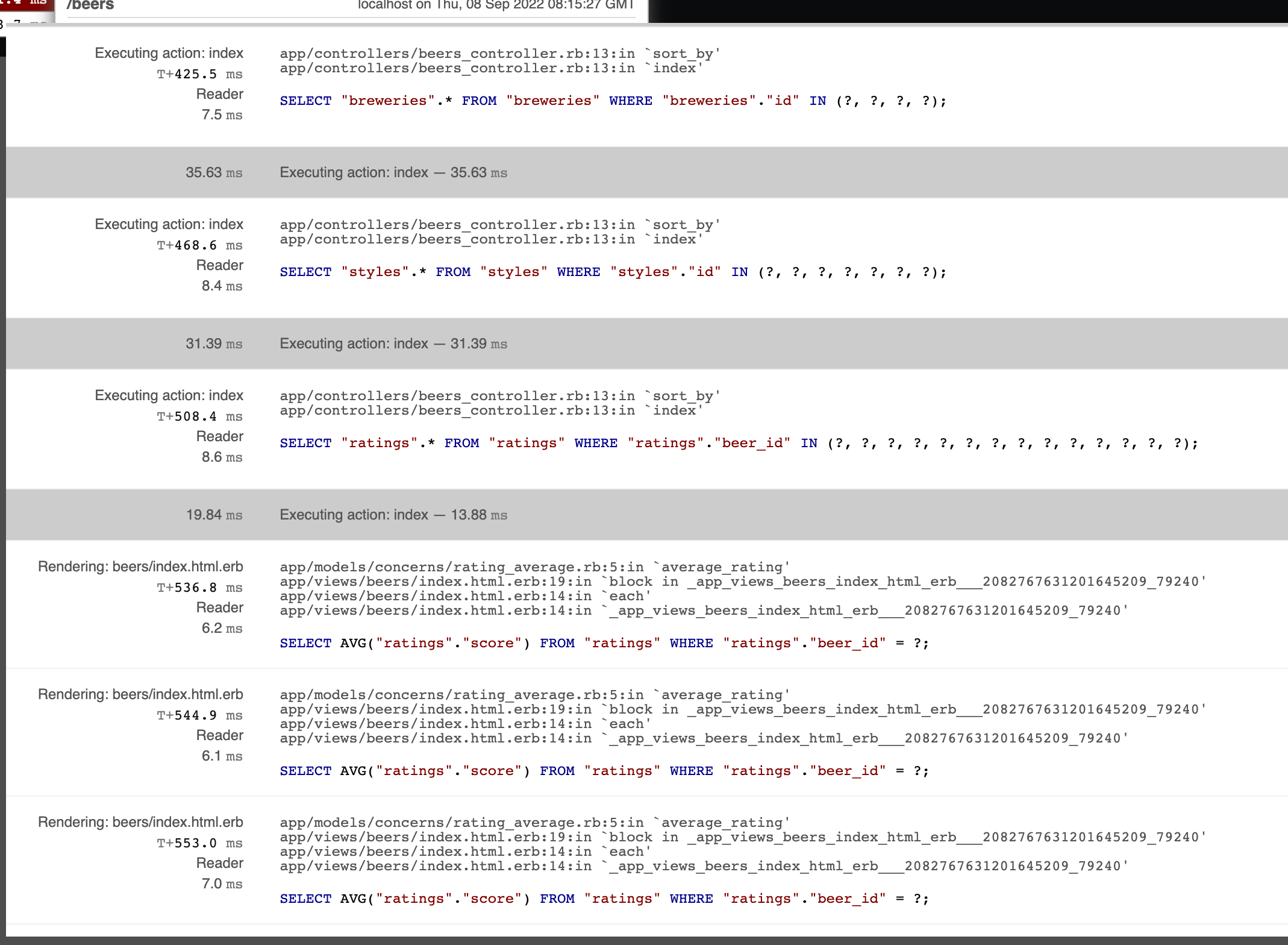
Syynä tälle on se, että olemme määritelleet että reittausten keskiarvo lasketaan SQL:n avulla:
module RatingAverage
extend ActiveSupport::Concern
def average_rating
# tämä generoi SQL:ää
ratings.average(:score).to_f
end
endNyt ei siis auta vaikka olemme kyselyn avulla jo hakeneet reittaukset muistiin. Voisimme hyödyntää includes-komennon avulla haettuja olueeseen liittyviä reittauksia laskennassa muokkaamalla laskenta tapahtumaan SQL:n sijaan keskusmuistissa:
module RatingAverage
extend ActiveSupport::Concern
def average_rating
# tehdään laskelmat muistiin haettujen olueen liittyvien ratings-olioiden avulla
rating_count = ratings.size
return 0 if rating_count == 0
ratings.map{ |r| r.score }.sum / rating_count
end
endKontrollerin suoritus aiheuttaa nyt entistä vähemmän kyselyjä ja näytön renderöinti ainoastaan yhden kyselyn.
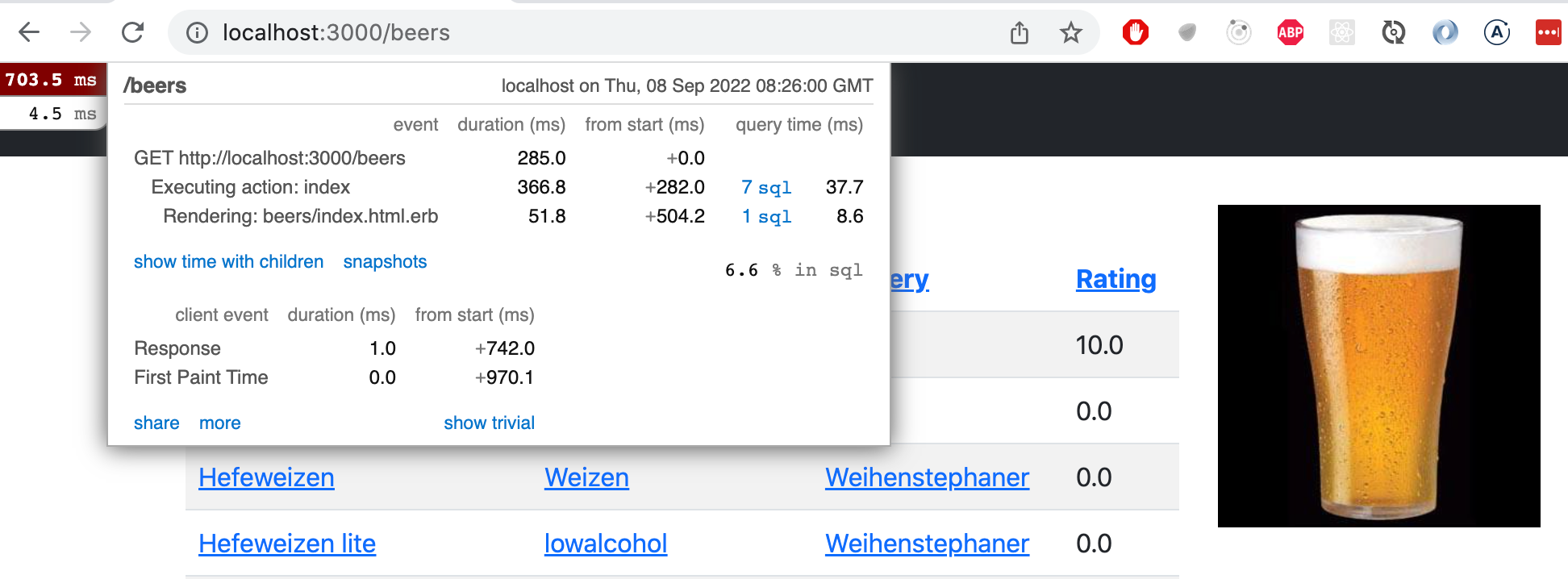
Miniprofiler paljastaa että kysely on
SELECT "users".* FROM "users" WHERE "users"."id" = ? LIMIT 1ja syynä sille on
app/controllers/application_controller.rb:7:in `current_user'eli näytön muuttujan current_user avulla tekemä viittaus kirjautuneena olevaan käyttäjään. Tämä ei kuitenkaan ole hirveän vakavaa.
Saimme helposti optimoitua SQL-kutsujen määrää ja sitä myöden sivun lautausaikaa! SQL-kutsujen määrän väheneminen on sikäli hyvä, että se on vakio ja ei riipu järjestelmässä olevien oluiden määrästä.
Kokemaamme kutsutaan n+1-ongelmaksi (ks. http://guides.rubyonrails.org/active_record_querying.html#eager-loading-associations), eli hakiessamme kannasta yhdellä kyselyllä listallisen olioita, jokainen listan olioista aiheuttaakin salakavalasti uuden tietokantahaun ja näin yhden haun sijaan tapahtuukin noin n+1 hakua.
Muutetaan seuraavaa tehtävää varten käyttäjien näkymä views/users.html.erb näkymä/partiali yksinkertaisempaan muotoon:
<h1>Users</h1>
<div id="users">
<% @users.each do |user| %>
<p>
<%= link_to(user.username, user) %>
<p>Has made <%= "#{user.ratings.size}"%> ratings, average rating <%= "#{user.average_rating}" %></p>
<% if user.closed? %>
<span class="badge text-bg-danger">account closed</span>
<% end %>
</p>
<% end %>
</div>Huomaa, että if-ehdon if user.closed toimivuus riippuu siitä miten olet nimennyt asioita viikolla 5 tehdyn tehtävän koodissa. Voit tarvittaessa poistaa koko ehdon.
Käyttäjien sivulla http://localhost:3000/users on n+1-ongelma. Korjaa ongelma edellisen esimerkin tapaan eager loadaamalla tarvittavat oliot käyttäjien hakemisen yhteydessä. Varmista optimointisi onnistuminen miniprofilerilla.
Huom: jos listaan liitettäisiin myös suosikkioluen kertova rivi
<% if user.favorite_beer %>
<p>Favourite beer: <%= "#{user.favorite_beer.name}"%></p>
<% end %>
Muuttuisi tilanne hieman hankalammaksi SQL:n optimoinnin suhteen. Metodimme viimeisin versio oli seuraava:
def favorite_beer
return nil if ratings.empty?
ratings.order(score: :desc).limit(1).first.beer
endNyt edes eager loadaaminen ei auta, sillä metodikutsu aiheuttaa joka tapauksessa SQL-kyselyn. Jos sen sijaan toteuttaisimme metodin keskusmuistissa olueeseen liittyviä reittauksia (kuten teimme aluksi viikolla 4):
def favorite_beer
return nil if ratings.empty?
ratings.sort_by{ |r| r.score }.last.beer
endmetodikutsu ei aiheuttaisi tietokantaoperaatiota jos reittaukset olisi eager loadattu siinä vaiheessa kun metodia kutsutaan.
Saattaakin olla, että metodista olisi tietyissä tilanteissa suorituskykyä optimoitaessa hyvä olla kaksi versiota, toinen joka suorittaa operaation tietokantatasolla ja toinen keskusmuistissa operaation tekevä.
Luodaan tietokantaamme hiukan lisää dataa.
Korvaa tiedoston db/seeds.db sisältö seuraavalla:
# jos koneesi on nopea, voit myös kasvattaa ao lukuja
users = 50
breweries = 50
beers_in_brewery = 50
ratings_per_user = 30
(1..users).each do |i|
User.create! username: "user_#{i}", password: "Passwd1", password_confirmation: "Passwd1"
end
(1..breweries).each do |i|
Brewery.create! name: "Brewery_#{i}", year: 1900, active: true
end
bulk = Style.create! name: "Bulk", description: "cheap, not much taste"
Brewery.all.each do |b|
n = rand(beers_in_brewery)
(1..n).each do |i|
beer = Beer.create! name: "Beer #{b.id} -- #{i}", style: bulk, brewery: b
b.beers << beer
end
end
User.all.each do |u|
n = rand(ratings_per_user)
beers = Beer.all.shuffle
(1..n).each do |i|
r = Rating.new score:(1+rand(50))
beers[i].ratings << r
u.ratings << r
end
endKäytämme tiedostossa normaalien olioiden luovien metodien create sijaan huutomerkillistä versiota create!. Metodien erona on niiden käyttäytyminen tilanteessa, jossa olion luominen ei onnistu. Huutomerkitön metodi palauttaa tällöin arvon nil, huutomerkillinen taas aiheuttaa poikkeuksen. Seedauksessa poikkeuksen aiheuttaminen on parempi vaihtoehto, muuten luomisen epäonnistuminen jää herkästi huomaamatta.
Kopioi sitten vanha tietokanta db/development.sqlite talteen, jotta voit palata vanhaan tilanteeseen suorituskyvyn virittelyn jälkeen. Vot ottaa vanhan tietokannan käyttöön muuttamalla sen nimeksi jälleen development.sqlite
Huom: tämä ei ole välttämättä paras mahdollinen tapa tehdä suorituskykytestausta oikeille Rails-sovelluksille, ks. lisää tietoa seuraavasta http://guides.rubyonrails.org/v3.2.13/performance_testing.html (guidesta ei ole Rails 7:lle päivitettyä versiota.)
Suorita seedaus komennolla
rails db:seed
Skriptin suorittamisessa kuluu tovi.
Huom: jos skriptin suoritus päättyy virheeseen, kannattaa vian korjaamisen jälkeen palauttaa vanha tietokanta ennen skriptin uutta suorittamista. Eräs potentiaalinen ongelma skriptin suorituksessa on validoinnin rikkovat duplikaattinimet. Jos muutat komennon create! muotoon create ei skriptin suoritus keskeydy.
Nyt tietokannassamme on runsaasti dataa ja sivujen lataaminen alkaa olla hitaampaa.
Kokeile nyt miten sivujen suorituskykyyn vaikuttaa jos kommentoit pois äsken tekemäsi SQL-kyselyjen optimoinnit oluiden sivulta, eli muuta olutkontrolleri takaisin muotoon:
def index
# @beers = Beer.includes(:brewery, :style).all
@beers = Beer.all
order = params[:order] || 'name'
@beers = case order
when 'name' then @beers.sort_by{ |b| b.name }
when 'brewery' then @beers.sort_by{ |b| b.brewery.name }
when 'style' then @beers.sort_by{ |b| b.style.name }
end
endHuomioi myös suoritettujen SQL-kyselyjen määrä optimoinnilla ja ilman. Tuloksenhan näet jälleen kätevästi miniprofilerin avulla.
Kokeilun jälkeen voit palauttaa koodin optimoituun muotoon.
Datamäärän ollessa suuri, ei pelkkä kyselyjen optimointi riitä, vaan on etsittävä muita keinoja.
Vaihtoehdoksi nousee tällöin cachaus eli välimuistien käyttö.
Web-sovelluksessa cachaystä voidaan suorittaa sekä selaimen, että palvelimen puolella (sekä selaimen ja palvelimen välissä olevissa proxyissä). Tarkastellaan nyt palvelimen puolella tapahtuvaa cachaystä. Toteutimme jo toissa viikolla "käsin" beermapping-apista haettujen tietojen cachaystä Rails.cachen avulla. Tutkitaan nyt railsin tarjoamaa hieman automaattisempaa cachaysmekanismia.
Cachays ei ole oletusarvoisesti päällä kun sovellusta suoritetaan development-moodissa. Kytkit ehkä cachen päälle viikolla 5.
Jos cache on päällä, on projektissa olemassa tiedosto tmp/caching-dev.txt. Jos tiedostoa ei ole, saat cachen päälle suorittamalla komentoriviltä komennon rails dev:cache. Komennon pitäisi tulostaa
Development mode is now being cached.
Jos komento tulostaa
Development mode is no longer being cached.
suorita se uudelleen.
Käynnistä nyt sovellus uudelleen.
Päätetään cachata oluiden listan näyttäminen.
Cachays tapahtuu sisällyttämällä näkymätemplaten cachattavan osa, eli sivufragmentti seuraavanlaiseen lohkoon:
<% cache 'avain', skip_digest: true do %>
cachättävä näkymätemplaten osa
<% end %>Kuten arvata saattaa, avain on avain, jolla cachattava näkymäfragmentti talletetaan. Avaimena voi olla merkkijono tai olio. skip_digest: true liittyy näyttötemplatejen versiointiin jonka haluamme nyt jättää huomioimatta. Tämä kuitenkin tarkoittaa, että välimuisti on syytä tyhjentää (komennolla Rails.cache.clear) jos näkymätemplaten koodia muutetaan.
Fragmentticachayksen lisääminen oluiden listalle views/beers/index.html on helppoa, cachataan sivulta sen dynaaminen osa eli oluiden taulukko:
<h1>Beers</h1>
<% cache 'beerlist', skip_digest: true do %>
<div id="beers">
<table class="table table-striped table-hover">
<thead>
<tr>
<th><%= link_to "Name", beers_path(order: "name")%></th>
<th><%= link_to "Style", beers_path(order: "style")%></th>
<th><%= link_to "Brewery", beers_path(order: "brewery")%></th>
<th><%= link_to "Rating", beers_path(order: "rating")%></th>
</tr>
</thead>
<tbody>
<% @beers.each do |beer| %>
<tr>
<td><%= link_to beer.name, beer %></td>
<td><%= link_to beer.style.name, beer.style %></td>
<td><%= link_to beer.brewery.name, beer.brewery %></td>
<td><%= round(beer.average_rating) %></td>
</tr>
<% end %>
</tbody>
</table>
</div>
<% end %>
<%= link_to("New beer", new_beer_path, class: "btn btn-primary") if current_user %>Kun nyt menemme sivulle, ei sivufragmenttia ole vielä talletettu välimuistin ja sivun lataaminen kestää yhtä kauan kuin ennen cachayksen lisäämistä:
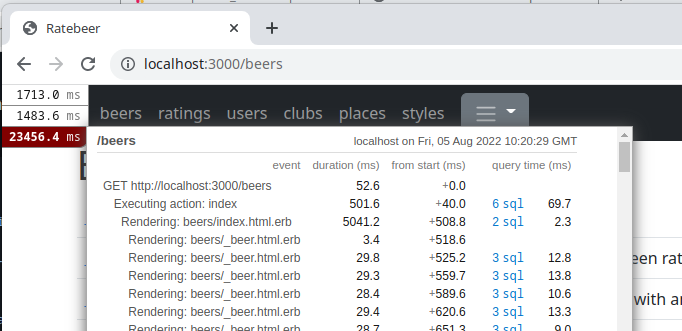
Sivun latausaika on 234564ms, mistä itse sivun renderöimiseen kulunut aika Rendering: beers/index on siis 5041.2 millisekuntia.
Sivulla käytyämme sivun osa tallettuu välimuistiin ja seuraava sivun avaaminen on huomattavasti nopeampi:
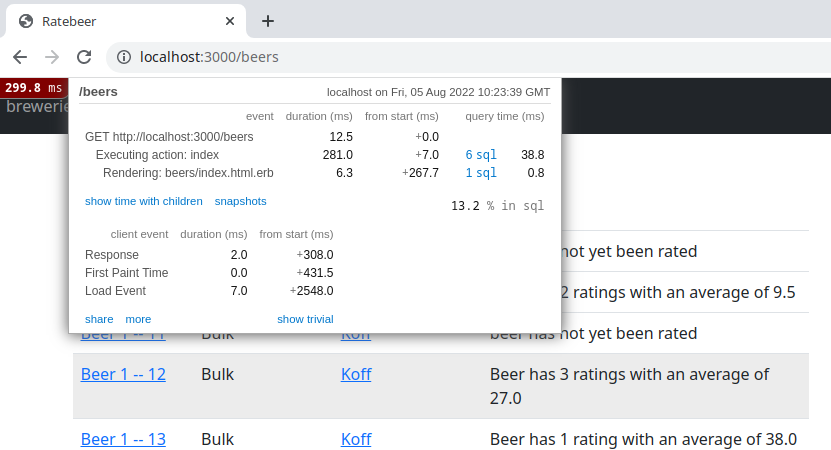
Koko sivun latausaika on 299 millisekuntia, josta ainoastaan 6.3 millisekuntia kuluu näkymätemplaten lataamiseen.
Huom: uuden oluen luomislinkkiä ei kannata laittaa cachatyn fragmentin sisälle, sillä linkki tulee näyttää ainoastaan kirjautuneille käyttäjille. Sivun cachatty osa näytetään nyt kaikille samanlaisena.
Jos luomme nyt uuden oluen huomaamme, että uuden oluen tietoja ei tule sivulle. Syynä tälle on tietenkin se, että sivufragmentti löytyy edelleen välimuistista. Vanhentunut näkymäfragmentti tulisi siis ekspiroida. Tässä tapauksessa helpoin strategia on kontrollerista käsin tapahtuva manuaalinen ekspirointi.
Ekspirointi tapahtuu komennolla expire_fragment(avain) jota tulee siis kutsua kontrollerista niissä kohdissa joissa oluiden listan sisältö mahdollisesti muuttuu. Tälläisiä kohtia ovat olutkontrollerin metodit create, update ja destroy. Muutos on helppo:
def create
expire_fragment('beerlist')
end
def update
expire_fragment('beerlist')
# ...
end
def destroy
expire_fragment('beerlist')
# ...
endMuutosten jälkeen sivu toimii odotetulla tavalla!
Kaikkien oluiden sivua olisi mahdollista nopeuttaa vielä jonkin verran. Nyt nimittäin kontrolleri suorittaa tietokantaoperaation
@beers = Beer.includes(:brewery, :style, :ratings).allmyös silloin kun sivufragmentti löytyy välimuistista. Voisimmekin testata fragmentin olemassaoloa metodilla fragment_exist? ja suorittaa tietokantaoperaation ainoastaan jos fragmentti ei ole olemassa:
def index
# jos fragmentti olemassa, lopetetaan metodi tähän (eli renderöidään heti näkymä)
return if request.format.html? && fragment_exist?('beerlist')
@beers = Beer.includes(:brewery, :style, :ratings).all
order = params[:order] || 'name'
@beers = case order
when 'name' then @beers.sort_by(&:name)
when 'brewery' then @beers.sort_by{ |b| b.brewery.name }
when 'style' then @beers.sort_by{ |b| b.style.name }
end
endEhdossa oleva request.format.html? varmistaa sen, että suoritamme kontrollerimetodin kaiken koodin siinä tapauksessa jos muodostamme json-muotoisen vastauksen.
Sivu nopeutuu entisestään:
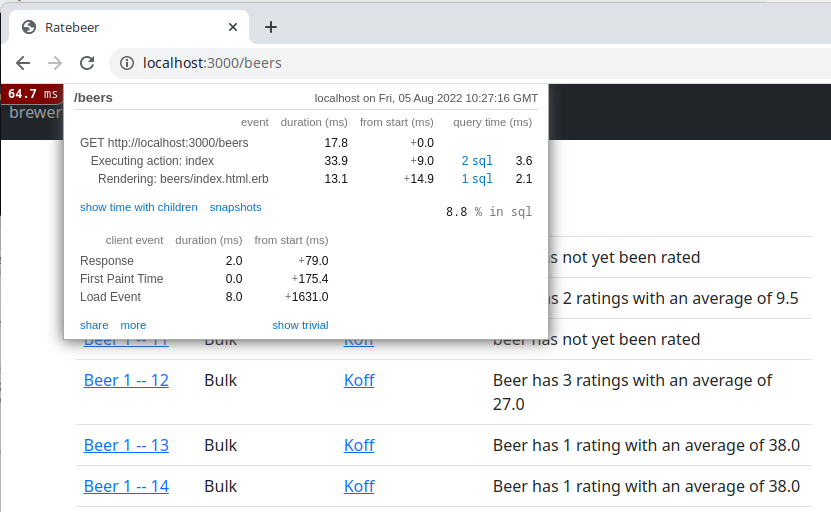
Huomaamme kuitenkin että sivulla on pieni ongelma. Oluet sai järjestettyä sarakkeita klikkaamalla vaihtoehtoisiin järjestyksiin. Cachays on kuitenkin rikkonut toiminnon!
Yksi tapa korjata toiminnallisuus on liittää fragmentin avaimeen järjestys:
<% cache "beerlist-#{@order}", skip_digest: true do %>
taulukon html
<% end %>Järjestys talletetaan siis muuttujaan @order kontrollerissa. Seuraavassa kontrollerin vaatimat muutokset:
def index
@order = params[:order] || 'name'
return if request.format.html? && fragment_exist?("beerlist-#{@order}")
@beers = Beer.includes(:brewery, :style, :raings).all
@beers = case @order
when 'name' then @beers.sort_by(&:name)
when 'brewery' then @beers.sort_by{ |b| b.brewery.name }
when 'style' then @beers.sort_by{ |b| b.style.name }
end
endEkspiroinnin yhteydessä on ekspiroitava kaikki kolme järjestystä:
["beerlist-name", "beerlist-brewery", "beerlist-style"].each{ |f| expire_fragment(f) }Huom: voit kutsua fragmentticachen operaatioita konsolista:
> ActionController::Base.new.fragment_exist?('beerlist-name')
Exist fragment? views/beerlist-name (0.4ms)
=> true
> ActionController::Base.new.expire_fragment('beerlist-name')
Expire fragment views/beerlist-name (0.6ms)
=> true
> ActionController::Base.new.fragment_exist?('beerlist-name')
Exist fragment? views/beerlist-name (0.1ms)
=> nilMuuta seuraavaa tehtävää varten panimoiden sivu http://localhost:3000/breweries näyttämään panimotiedot taulukossa
<h1>Listing breweries</h1>
<p> Number of active breweries: <%= @active_breweries.count %> </p>
<div id="active_breweries">
<table class="table table-striped table-hover">
<thead>
<tr>
<th>Name</th>
<th>Founded</th>
<th>Beers</th>
<th>Rating</th>
</tr>
</thead>
<tbody>
<% @active_breweries.each do |brewery| %>
<tr>
<td><%= link_to brewery.name, brewery %></td>
<td><%= brewery.year %></td>
<td><%= brewery.beers.count %></td>
<td><%= round(brewery.average_rating) %></td>
</tr>
<% end %>
</tbody>
</table>
</div>Toteuta panimot listaavalle sivulle fragmentticachays. Varmista, että sivun sisältöön vaikuttava muutos (panimon tietojen muutos, tieto oluiden lukumäärän muutoksesta tai reittausten keskiarvon muutoksesta) ekspiroi cachen.
Toteuta cachen expirointi before_action:iksi määritellyn funktion avulla, jotta ekspiroivaa koodia ei tarvitse kopioida eri metodeihin
Jos haluaisimme cachata yksittäisen oluen sivun, kannattaa fragmentin avaimeksi laittaa itse cachattava olio:
<% cache @beer do %>
<h3>
<%= @beer.name %>
</h3>
<p>
<%= @beer.style.name %>
</p>
<p>
<%= link_to "#{@beer.brewery.name}", @beer.brewery %>
</p>
<p>
<% if @beer.ratings.empty? %>
beer has not yet been rated
<% else %>
Beer has <%= pluralize(@beer.ratings.count, "rating") %>
with an average of <%= @beer.average_rating %>
<% end %>
</p>
<% end %>
<!- cachaamaton osa ->
<% if current_user %>
<h4>give a rating:<h4>
<%= form_with(model: @rating) do |form| %>
<%= form.hidden_field :beer_id %>
score: <%= form.number_field :score %>
<%= form.submit "Create rating", class: "btn btn-primary" %>
<% end %>
<% if current_user && current_user.admin %>
<div>
<%= link_to("Edit this beer", edit_beer_path(@beer), class: "btn btn-primary") %>
<%= button_to "Destroy this beer", @beer, class: "btn btn-danger", form: { data: { turbo_confirm: "Are you sure ? "} }, method: :delete if current_user %>
</div>
<% end %>
<% end %>
<%= link_to "Back to beers", beers_path %>
Nyt fragmentin avaimeksi tulee merkkijono, jonka Rails generoi kutsumalla olion metodia cache_key_with_version. Metodi generoi avaimen joka yksilöi olion ja sisältää aikaleiman, joka edustaa hetkeä, jolloin olio on viimeksi muuttunut. Jos olion kenttiin tulee muutos, muuttuu fragmentin avaimen arvo eli vanha fragmentti ekspiroituu automaattisesti. Seuraavassa esimerkki automaattisesti generoituvasta cache-avaimesta:
> b = Beer.first
> b.cache_key_with_version
=> "beers/1-20180924183300410080"
> b.update_attribute(:name, 'ISO 4')
> b.cache_key_with_version
=> "beers/1-20180924183314873407"Ratkaisu on vielä sikäli puutteellinen, että jos olueeseen tehdään uusi reittaus, olio ei itsessään muutu ja fragmentti ei ekspiroidu. Ongelma on kuitenkin helppo korjata. Lisätään reittaukseen tieto, että reittauksen syntyessä, muuttuessa tai tuhoutuessa, on samalla 'kosketettava' reittaukseen liittyvää olutta:
class Rating < ApplicationRecord
belongs_to :beer, touch: true
# ...
endKäytännössä belongs_to-yhteyteen liitetty touch: true saa aikaan sen, että yhteyden toisessa päässä olevan olion kenttä updated_at päivittyy.
Muuta seuraavaa tehtävää varten yksittäisen panimon näkymää siten, että se listaa panimon oluiden tiedot esim. seuraavaan tapaan
Toteuta yksittäisen panimon sivulle fragmentticachays. Huomaa, että edellisen esimerkin tapaan panimon sivufragmentin on ekspiroiduttava automaattisesti jos panimon oluisiin tulee muutoksia.
Välimuistin eksplisiittinen ekspiroiminen, kuten kaikkien oluiden sivun suhteen joudumme tekemään, on hieman ikävää sillä on aina pieni riski, että koodissa ei muisteta ekspiroida fragmenttia kaikissa tarpeellisissa kohdissa.
Käyttäessämme suoraan olioa (kuten yksittäisen oluen sivulla tehtiin) fragmentin avaimena, ekspiroitui cache automaattisesti olion päivittyessä. Myös kaikkien oluiden sivulle olisi mahdollista tehdä automaattisesti ekspiroituva cache generoimalla fragmentin avain tarkoitukseen sopivan metodin avulla, katso Caching with Rails: An overview
Cachaysta harjoitetaan monilla tasoilla, myös selainpuolella. Lisää tietoa Railsin tuesta selainpuolen cachaykseen täällä
Sovelluksen käyttäjän kannalta ei ole aina välttämätöntä, että sovelluksen näyttämä tilanne on täysin ajantasalla. Esim. ei ole kriittistä, jos reittausstatistiikkaa näyttävä ratings-sivu näyttää muutaman minuutin vanhan tilanteen, pääasia on, että kaikki järjestelmään tullut data tulee ennen pitkää näkyville käyttäjille. Tälläisestä hieman löyhemmästä ajantasaisuusvaatimuksesta, jolla saatetaan pystyä tehostamaan sovelluksen suorituskykyä huomattavasti käytetään englanninkielistä nimitystä eventual consistency.
Eventual consistency -mallin mukainen ajantasaisuus on helppo määritellä Railsissa laittamalla esim. fragmentticachelle expiroitumisaika:
<% cache 'fragment_name', expires_in:10.minutes do %>
...
<% end %>Tämä yksinkertaistaa sovellusta myös siinä mielessä, että cachen ekspiroiminen on helppoa, kun ei ole pakko huomioida kaikkia yksittäisiä kohtia koodissa, jotka voisivat aiheuttaa sivun epäajantasaisuuden.
Oletetaan, että järjestelmällämme olisi todella paljon käyttäjiä ja reittauksia tapahtuisi useita kertoja minuutissa. Jos haluaisimme näyttää ratings-sivulla täysin ajantasaista tietoa, ei sivun suorituskyky olisi hyvä, sillä jokainen oluen reittaus muuttaa sivun tilaa, ja sivu tulisi ekspiroida erittäin usein. Tämä taas tekisi cachayksestä lähes hyödyttömän.
SQL:n optimointi ja cachayskään eivät vielä tee ratings-sivusta kovin nopeita, sillä kontrollerin käyttämät operaatiot esim. User.top(3) vaativat käytännössä melkein koko tietokannan datan läpikäyntiä. Jos haluaisimme optimoida sivua vielä enemmän, tulisi meidän käyttää järeämpiä keinoja. Esim User.top-komennon suoritus nopeutuisi huomattavasti, jos käyttäjän reittausten määrä talletettaisiin suoraan käyttäjä-olioon, eli sen laskeminen ei edellyttäisi käyttäjään liittyvien Rating-olioiden lukumäärän laskemista. Tämä taas edellyttäisi, että aina käyttäjän uuden reittauksen yhteydessä päivitettäisiin myös käyttäjä-olioa. Eli itse reittausoperaation suoritus hidastuisi hieman.
Toinen ja ehkä parempi tapa reittaussivun nopeuttamiselle olisi cachata Rails.cacheen kontrollerin tarvitsemat tiedot. Kontrolleri on siis seuraava
def index
@ratings = Rating.recent
@beers = Beer.top(3)
@styles = Style.top(3)
@breweries = Brewery.top(3)
@users = User.top(3)
endVoisimme toimia nyt samoin kuin viikolla 5 kun talletimme olutravintoloiden tietoja Railsin cacheen, eli kontrolleri muuttuisi suunnilleen seuraavaan muotoon:
def index
Rails.cache.write("beer top 3", Beer.top(3)) if cache_does_not_contain_data_or_it_is_too_old
@top_beers = Rails.cache.read "beer top 3"
# ...
endSovellusten suorituskyvyn optimointi ei ole välttämättä helppoa, se edellyttää monentasoisia ratkaisuja ja pitää useimmiten tehdä tilannekohtaisesti räätälöiden. Koodi muuttuu yleensä optimoinnin takia rumemmaksi.
Yhtenä negatiivisena puolena cachen ajoittain tapahtuvassa ekspiroimisessa, esim. jos noudattaisimme strategiaa ratings-sivun suhteen, aiheutuu jollekin käyttäjälle aika ajoin paljon aikaavievä operaatio siinä vaiheessa kun data on generoitava uudelleen välimuistiin.
Parempaan ratkaisuun päästäisiinkin jos käyttäjälle tarjottaisiin aina niin ajantasainen data kuin mahdollista, eli kontrolleri olisi muotoa:
def index
@top_beers = Rails.cache.read("beer top 3")
# ...
endVälimuistin päivitys voitaisiin sitten suorittaa omassa taustalla olevassa, aika ajoin heräävässä säikeessä/prosessissa:
# pseudokoodia, ei toimi oikeasti...
def background_worker
while true do
sleep 10.minutes
Rails.cache.write("beer top 3", Beer.top(3))
Rails.cache.write("brewery top 3", Brewery.top(3))
# ...
end
endYlläesitellyn kaltainen taustaprosessointitapa on siinä mielessä yksinkertainen, että sovelluksen ja taustaprosessointia suorittavan säikeen/prosessin ei tarvitse synkronoida toimintojaan. Toisinaan taas taustaprosessoinnin tarpeen laukaisee jokin sovellukselle tuleva pyyntö. Tällöin sovelluksen ja taustaprosessoijien välisen synkronoinnin voi hoitaa esim. viestijonojen avulla.
Viestijonoilla ja erillisillä prosesseilla tai säikeillä hoidetun taustaprosessoinnin toteuttamiseen Railsissa on paljon erilaisia vaihtoehtoja, yksi ratkaisu näistä on Sidekiq.
Jos sovellus tarvitsee ainoastaan jonkin yksinkertaisen, tasaisin aikavälein suoritettavan taustaoperaation, saattaa Heroku scheduler olla yksinkertaisin vaihtoehto . Tällöin taustaoperaatio määritellään Rake-taskina, jonka Heroku suorittaa joko kerran vuorokaudessa, tunnissa tai kymmenessä minuutissa. Nopean googlailun perusteella Fly.io ei vielä tarjoa ihan vastaavaa helppokäyttöistä eräajokomentoa.
Kuten edellä todettiin, yksi vaihtoehto asynkronisten operaatioiden suorittamiseen Railsilla on Sidekiq. Sidekiq kuitenkin vaatii oman prosessinsa, eli esim. Fly.io:ssa Herokussa sidekiqia ei ole helppoa suorittaa varaamatta sille omaa prosessia eli dynoa, ja sen käyttäminen maksaa muutamia dollareita kuussa.
Ilmaisten Heroku-palveluiden yhteydessä on mahdollista käyttää Sucker Punch -kirjastoa:
Sucker Punch is a single-process Ruby asynchronous processing library. This reduces costs of hosting on a service like Heroku along with the memory footprint of having to maintain additional jobs if hosting on a dedicated server. All queues can run within a single application (eg. Rails, Sinatra, etc.) process.
Eli Sucker Punch suorittaa asynkroniset työt samassa prosessissa, missä itse Rails-sovellustakin suoritetaan.
Sucker Punchin käyttö on melko helppoa.
Lisää gemfileen gem 'sucker_punch', '~> 3.0' ja suorita bundle install.
eli määritellään Rails lataamaan automaattisesti luomaamme hakemistoon määritelty koodi.
Luodaan nyt Sucker Punch -operaatio, eli hakemistoon jobs tiedosto test_job.rb jolla on seuraava sisältö:
class TestJob
include SuckerPunch::Job
def perform
puts "running job..."
end
endVoimme suorittaa operaation antamalla rails-konsolista (tai mistä tahansa kohtaa sovelluksen koodia) komennon
TestJob.perform_asyncOperaatio tulostaa konsoliin running job.... Ei kovin vakuuttavaa.
Huomionarvoista tässä on kuitenkin se, että operaatio suoritetaan asynkronisesti taustalla, eli kontrolli palaa konsoliin jo ennen kuin operaatio on suoritettu.
Muutetaan operaatiota seuraavasti:
class TestJob
include SuckerPunch::Job
def perform
sleep 1
puts "starting job..."
sleep 10
puts "job ready!"
end
endeli nyt operaation suoritus kestää 11 sekuntia. Kun suoritat operaation komennolla TestJob.perform_async huomaat, että pääset takaisin konsoliin välittömästi komennon suorituksen jälkeen (joudut todennäköisesti painamaan enteriä että saat konsolin komentokehotteen näkyviin) ja operaation suoritus tapahtuu taustalla, samalla kun voit suorittaa konsolista halutessasi jotain muuta koodia.
Voit suorittaa operaation myös synkronisesti antamalla komennon TestJob.new.perform. Tällöin joudut odottamaan komennon suorituksen loppuun asti ennen kuin konsoli aktivoituu uudelleen.
Voit myös suorittaa operaatioita ajastetusti, esim. jos annat komennon TestJob.perform_in(10.seconds) suoritetaan operaatio asynkronisesti 10 sekunnin kuluttua.
Asynkroninen operaatio voi käynnistää itse itsensä, eli jos muutat koodin muotoon
class TestJob
include SuckerPunch::Job
def perform
sleep 1
puts "starting job..."
sleep 10
puts "job ready!"
TestJob.perform_in(30.seconds)
end
endja annat komennon TestJob.perform_async operaatio suoritetaan toistuvasti 30 sekunin välein niin kauan kunnes konsoli suljetaan.
Sivuhuomautuksena, ikuisesti pyörivää operaatiota ei kannata käynnistää testiympäristössä, sillä esim. Github Actions jää odottamaan prosessin loppumista.
Nopeuta ratings-sivun toimintaa haluamallasi tekniikalla. Voit olettaa, että käyttäjät ovat tyytyväisiä eventual consistency -mallin mukaiseen tiedon ajantasaisuuteen.
Kirjoita ratings-kontrollerin
index-metodiin pieni selitys nopeutusstrategiastasi jos se ei ole koodin perusteella muuten ilmeistä.Jos päädyt käyttämään asynkronisia workereita, ei koodia ole välttämättä ihan helppoa saada toimimaan täysin oikein.
Sovelluksen suorituskyvyn skaalaaminen onnistuu vain tiettyyn pisteeseen asti, jos sovellus on monoliittinen, kokonaan yhden tietokannan varassa, yhdellä palvelimella suoritettava kokonaisuus. Sovellusta voidaan toki optimoida ja sitä voidaan skaalata horisontaalisesti eli palvelimen fyysisiä resursseja kasvattamalla.
Parempaan skaalautuvuuteen päästään kuitenkin vertikaalisella skaalautuvuudella, eli sen sijaan että palvelimen fyysisiä resursseja yritettäisiin kasvattaa, otetaankin sovelluksen käyttöön useita palvelimia, jotka suorittavat sovelluksen toimintoja rinnakkain. Vertikaalinen skaalaaminen ei välttämättä onnistu triviaalisti, sovelluksen arkkitehtuuria on mukautettava. Jos sovellusta palvelee edelleen ainoastaan yksi tietokanta, voi siitä tulla pullonkaula vertikaalisesta skaalaamisesta huolimatta, erityisesti jos kyseessä on relaatiotietokanta, joiden hajauttaminen ja näin ollen vertikaalinen skaalaaminen ei ole helppoa.
Sovelluksen skaalaaminen (ja joissain tapauksissa myös sen ylläpitäminen ja laajentaminen) on helpompaa, jos sovellus on koostettu useammista erillisistä itsenäisenä toimivista keskenään esim. HTTP-protokollan välityksellä kommunikoivista palveluista. Sovelluksemme itseasiassa hyödyntää jo toista palvelua eli BeermappingAPI:a. Vastaavasti sovelluksen toiminnallisuutta voitaisiin laajentaa integroimalla siihen uusia palveluja.
Jos haluaisimme esim. että sovelluksemme tekisi käyttäjälle suosikkioluttyyleihin ja sijaintiin (joka saadaan selvitettyä esim. käyttäjän tekemien HTTP-kutsujen IP-osotteen perusteella, ks http://www.iplocation.net/) perustuvia ruokareseptisuosituksia, kannattaisi suosittelijasta tehdä kokonaan oma palvelunsa. Sovelluksemme keskustelisi sitten palvelun kanssa HTTP-protokollaa käyttäen.
Jos haluaisimme vastaavasti, että sovelluksemme näyttäisi käyttäjälle olutsuosituksia käyttäjän oman suosikkityylin perusteella, olisi tämän toiminnallisuuden eriyttäminen omaksi, erillisellä palvelimella toimivaksi palveluksi hieman haastavampaa, sillä suositukset todennäköisesti riippuisivat muiden ihmisten tekemistä reittauksista ja tähän tietoon käsille pääsy taas edellyttäisi olutsuosittelijalta pääsyä sovelluksemme tietokantaan. Eli jos oluiden suosittelija haluttaisiin toteuttaa omana erillisenä palvelunaan, olisi sovelluksemme rakennetta kenties mietittävä kokonaan uudelleen, jotta tieto reittauksista saataisiin jaettua ratebeer-sovelluksen ja olutsuosituspalvelun kesken.
Tyyli, jossa sovellus koostetaan mikropalveluista (engl. micro service) eli melko pienistä, yhden erillisen tehtävän itsenäisesti hoitavista palveluista on nauttinut viime vuosina melko suurta suosiota.
Relaatiotietokannat ovat dominoineet tiedon tallennusta jo vuosikymmenten ajan. Viime aikoina on kuitenkin alkanut jälleen tapahtumaan tietokantarintamalla, ja kattotermin NoSQL alla kulkevat "ei relaatiotietokannat" ovat alkaneet nostaa suosiotaan.
Yhtenä motivaationa NoSQL-tietokannoilla on ollut se, että relaatiotietokantoja on vaikea skaalata massiivisten internetsovellusten vaatimaan suorituskykyyn. Toisaalta myös tiettyjen NoSQL-tietokantojen skeemattomuus tarjoaa sovellukselle joustavuutta verrattuna SQL-tietokantojen tarkastimääriteltyihin tietokantaskeemoihin.
NoSQL-tietokantoja on useita, keskenään aivan erilaisilla toimintaperiaatteilla toimivia, mm.
- avain/arvotietokannat (key-value databases)
- dokumenttitietokannat (document databases)
- saraketietokannat (columnar databases)
- verkkotietokannat (graph databases)
Jo meille tutuksi tullut Rails.cache on oikeastaan yksinkertainen avain-arvotietokanta, joka mahdollistaa mielivaltaisten olioiden tallettamisen avaimeen perustuen. Tietokannasta haku on rajoittunut hakuun avaimien perusteella ja tietokanta ei tue kannassa olevien olioiden välisiä liitoksia ollenkaan.
Uusien tietokantatyyppien noususta huolimatta relaatiotietokannat tulevat kuitenkin säilymään ja on todennäköistä että isommissa sovelluksissa on käytössä rinnakkain erilaisia tietokantoja, ja kuhunkin talletustarkoitukseen pyritään valitsemaan tilanteeseen parhaiten sopiva tietokantatyyppi, ks. http://www.martinfowler.com/bliki/PolyglotPersistence.html
Viikon 6 tehtävässä 6-7 kehoitettiin tekemään luokille Beer, Brewery ja Style luokkametodit, joiden avulla kontrollerin on helppo selvittää saa reittausten perusteella parhaat panimot, oluet ja oluttyylit.
Metodit ovat kaikissa luokissa täsmälleen samat:
class Beer < ApplicationRecord
# ...
def self.top(how_many)
sorted_by_rating_in_desc_order = all.sort_by{ |b| -(b.average_rating || 0) }
sorted_by_rating_in_desc_order[0, how_many]
end
end
Viikolla 2 siirrettiin luokkien määrittelemiä samanlaisia oliometodeita yhteiseen moduuliin.
Myös luokkametodeja voidaan siirtää yhteiseen moduuliin, tekniikka ei kuitenkaan ole täysin sama kuin oliometodeja käytettävissä
Refaktoroi koodisi siten, että luokkien Beer, Brewery ja Style metodi def self.top(how_many) määritellään moduulissa. Saat vihjeitä toteutukseen esim. googlaamalla ruby module static method
Sovellus on nyt toiminnallisuudeltaan tämän kurssin osalta valmis. Sovellusta voi kuitenkin vielä hioa parempaan kuntoon mm. päivittämällä sovelluksen tyylejä, parantamalla validaatiota tai autentikaatiota.
Paranna sovellusta haluamallasi tavalla, tehtävän voi merkitä tehdyksi kun paranteluun on käytetty vähintään 15 minuuttia.
Kurssi on tehtävien osalta ohi ja on aika antaa kurssipalaute osoitteessa coursefeedback.helsinki.fi
Voit antaa palautteeen kun olet ensin ilmoittautunut avoimen yliopiston kurssitoteutukseen (ilmoittautumisen jälkeen menee noin 2 tuntia ennen kuin ilmoittautumistieto valuu kurssipalautesovellukseen)
Commitoi kaikki tekemäsi muutokset ja pushaa koodi GitHubiin. Deployaa myös uusin versio Fly.io:n tai Herokuun. Muista myös testata Rubocopilla, että koodisi noudattaa edelleen määriteltyjä tyylisääntöjä.
Tehtävät kirjataan palautetuksi osoitteeseen https://studies.cs.helsinki.fi/stats/courses/rails2022/
Ilmoittaudu avoimen yliopiston kurssitoteutukseen ja pyydä suoritusmerkintää palautussovelluksessa.
Jos Rails kiinnostaa, kannattaa tutustumista jatkaa esim. seuraaviin suuntiin
- http://guides.rubyonrails.org/ Paljon hyvää asiaa...
- http://railscasts.com/ erinomaisia yhteen teemaan keskittyviä videoita. Uusia videoita ei valitettavasti ole tullut yli vuoteen, toivottavasti sivu aktivoituu vielä. Useimmat maksulliset pro-episodit näköjään löytyvät youtubesta...
- https://www.ruby-toolbox.com/ apua gemien etsimiseen
- Eloquent Ruby erinomainen kirja Rubystä.
- Turbo: moderni tapa kehittää railsia tekemällä rails sovelluksista single page sovelluksia.