v1.35.0
Table of contents
- Release highlights
- Acknowledgments
- Contributions
- Deprecation notice
- Netdata Agent release meetup
- Support options
❗ We're keeping our codebase healthy by removing features that are end of life. Read the deprecation notice to check if you are affected.
Netdata open-source Agent statistics
- 7.6M+ troubleshooters monitor with Netdata
- 1.3M+ unique nodes currently live
- 3.3k+ new nodes per day
- Over 556M Docker pulls all-time total
Release highlights
Anomaly Advisor & on-device Machine Learning
We are excited to launch one of our flagship machine learning (ML) assisted troubleshooting features in Netdata: the Anomaly Advisor.
Netdata now comes with on-device ML! Unsupervised ML models are trained for every metric, at the edge (on your devices), enabling real time anomaly detection across your infrastructure.

This feature is part of a broader philosophy we have at Netdata when it comes to how we can leverage ML-based solutions to help augment and assist traditional troubleshooting workflows, without having to centralize all your data.
The new Anomalies tab quickly lets you find periods of time with elevated anomaly rates across all of your nodes. Once you highlight a period of interest, Netdata will generate a ranked list of the most anomalous metrics across all nodes in the highlighted timeframe. The goal is to quickly let you find periods of abnormal activity in your infrastructure and bring to your attention the metrics that were most anomalous during that time.
In our latest release, we improved the usability of Anomaly Advisor and also ensured that the anomalous metrics are always relevant to the time period you are investigating.
A great deal of care has gone into ensuring that ML running on your device is as light weight in terms of resource consumption as possible. For instance, metrics that do not have sufficient data for training and metrics that are consistently constant during training periods are considered to be "normal" until their behavior changes significantly to require re-training of the ML models.
To use this feature, please enable ML on your agent and then navigate to the "Anomalies" tab in Netdata cloud. Update netdata.conf with the following information to enable ML on your agent:
[ml]
enabled = yes
Read more about Anomaly Advisor at our blog.
Metrics Correlation on Agent
Metric Correlations allow you to quickly find metrics and charts related to a particular window of interest that you want to explore further. Metric correlations compare two adjacent windows to find how they relate to each other, and then score all metrics based on this rating, providing a list of metrics that may have influence or have been influenced by the highlighted one.
Metric Correlation was already available in Netdata Cloud, but now we are releasing a version implemented at the Netdata Agent, which drastically reduces the time required for to run. This means the metric correlation can now run almost instantly (more than 10x faster than before)!
To enable the new metric correlation at the Netdata Agent, set the following in your netdata.conf file:
[global]
enable metric correlations = yes
Kubernetes monitoring
On very busy Kubernetes clusters where hundreds of containers spawn and are destroyed all the time, Netdata was consuming a lot of resources and was slow to detect changes and under certain conditions it missed certain containers.
Now, Netdata:
- Detects "pause" containers and skips them greatly improving the performance during discovery
- Detects containers that are initializing and postpones discovery for them until they are properly initialized
- Utilizes less resources more efficiently during container discovery
Netdata is also capable of detecting the network interfaces that have been allocated to containers, by spawning a process that switches network namespace and identifies virtual interfaces that belong to each container. This process is improved drastically, now requiring 1/3 of the CPU resources it needed before.
Additionally, Netdata cgroups.plugin now collects CPU shares for Kubernetes containers, allowing the visualization of the Kubernetes CPU Requests (Kubernetes writes in cgroup CPU Shares the CPU Requests that have been configured for the containers).
A new option has been added in netdata.conf [plugin:cgroup] section, to allow filtering containers by (resolved) name. It matches the name of the cgroup (as you see it on the dashboard).
We have also released a blog post and a video about CPU Throttling in Kubernetes. You will be amazed by our findings. Read the blog and watch the video about Kubernetes CPU throttling.
Visualization improvements
Netdata Cloud dashboards are now a lot faster in aggregating data from multiple agents, as the protocol between agents and the Cloud is approaching its final shape.
New look for Netdata charts
Netdata Cloud has a new look and feel for charts, which resembles the look and feel for coding IDEs:

New home for war rooms
The new home tab for war rooms allows you to quickly inspect the most important metrics for every war room, like number of nodes, metrics, retention, replication, alerts, users, custom dashboards, etc.

Time units
Time units now in charts auto-scale from microseconds to days, automatically based on the value of time to be shown.
Cloud queries timeout
The agent now sets a timeout on every query it sends to the agents, and the agents now respect this timeout. Previously, the cloud was timing out because of a slow query, but the agents remained busy executing that query, which had a waterfall effect on the agent load.
Custom dashboards
Custom dashboards on Netdata Cloud can now be renamed.
Alerts management
All configured alerts on the Cloud
We have added a new Alert Configs sub tab which lists all the alerts configured on all the nodes belonging to the war room. You have now a possibility of listing the alerts configured in the - war room, nodes and alert instances respectively.
Stale alerts
There have been a number of corner cases under which alerts could remain raised on Netdata cloud. We identified all such cases, and now Netdata Cloud is always in sync with Netdata agents about their alerts.
Nodes management
Cloud provider metadata
Netdata now identifies the Cloud provider node type it runs on. It works for GCP and AWS, and exposes this information at the Nodes tab, the single node dashboard, and the node inspector.

Virtualization detection fixes
We improved the virtualization detection in cases where systemd is not available. Now Netdata can properly detect virtualization even in these cases.
Global nodes filter on all tabs of a space
The new Netdata Cloud now supports a global filter on nodes of war rooms. The new filter is applied on every tab for each room, allowing users to quickly switch between tabs while retaining the nodes filtered.
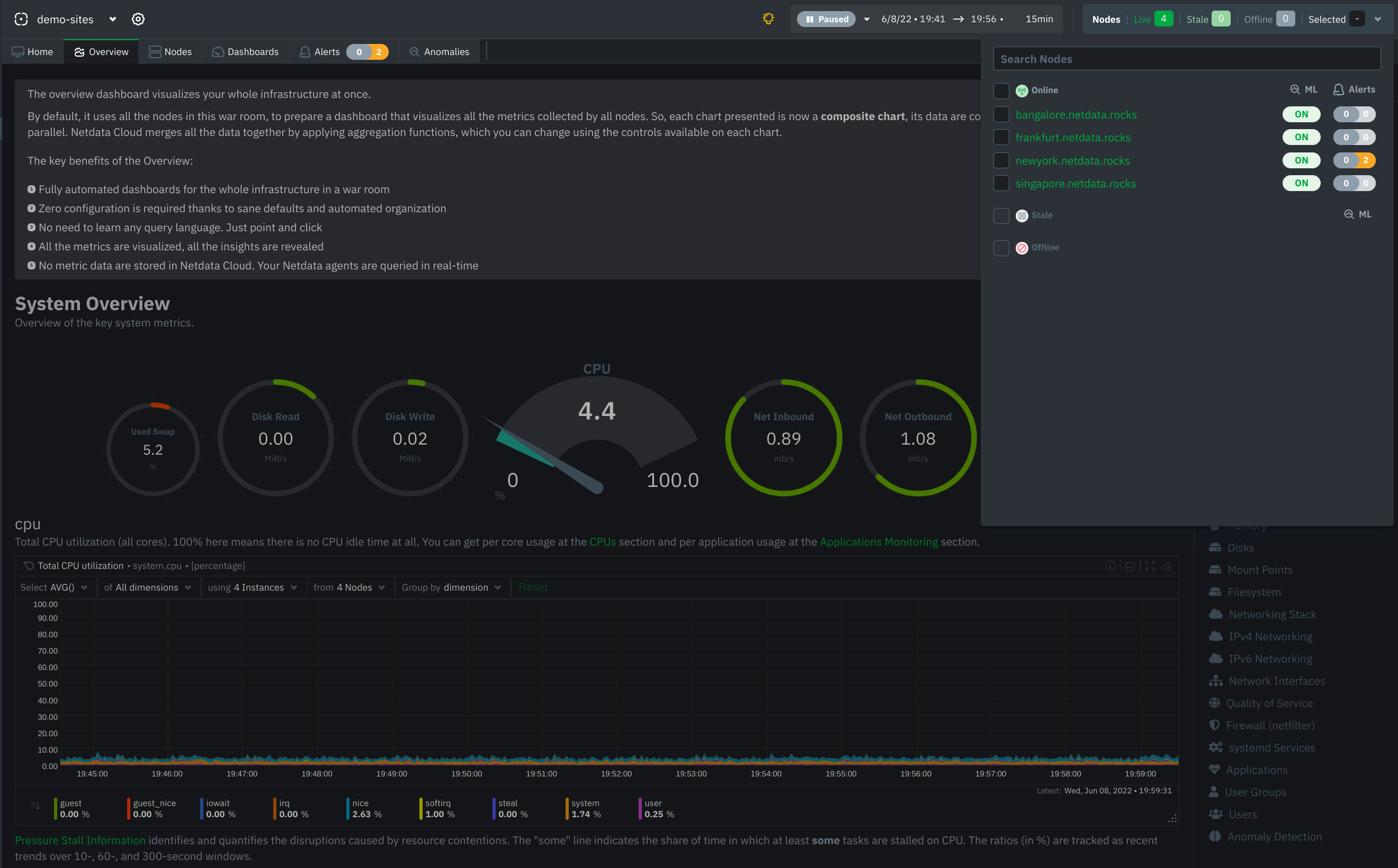
Obsoletion of nodes
Netdata admin users now have the ability to remove obsolete nodes from a space. Many users have been eagerly waiting for this feature, and we thank you for your patience. We hope you will be happy to use the feature and have cleaner spaces and war rooms. A few notes to be considered:
- Only admin users have the ability to obsolete nodes
- Only offline nodes can be marked obsolete (Live nodes and stale nodes cannot be obsoleted)
- Node obsoletion works across the entire space, so the obsoleted node will be removed from all rooms belonging to the space
- If the obsoleted nodes eventually become live or online once more, they will be automatically re-added to the space
StatsD improvements
Every Netdata Agent is a StatsD server, listening on localhost port 8125, both TCP and UDP. You can use the Netdata StatsD server to quickly visualize metrics from scripts, Cron Job, and local applications.
In this release, the Netdata StatsD server has been improved to use Judy arrays for indexing the collected metrics, drastically improving its performance.
At the same time we extended the StatsD protocol to support dictionaries . Dictionaries are similar to sets, but instead of reporting only the number of unique entries in the set, dictionaries create a counter for each of the values and report the number of occurrences for each unique event. So, to quickly get a break down of events, you can push them to StatsD like myapp.metric:EVENT|d. StatsD will create a chart for myapp.metric and for each unique EVENT it will create a dimension with the number of times this events was encountered.
We also added the ability to change the units of the chart and the family of the chart, using StatsD tags, like this: myapp.metric:EVENT|d|#units=events/s.
Finally, StatsD now automatically creates a dashboard section for every StatsD application name. Following StatsD best practices, these application names are considered to be the first keyword of collected metrics. For example, by pushing the metric myapp.metric:1|c, StatsD will create the dashboard section "StatsD myapp".
Read more at the Netdata StatsD documentation. A real-life example of using Netdata StatsD from a shell script pushing in realtime metric to a local Netdata Agent, is available at this stress-with-curl.sh gist.
3x faster agent queries
Netdata dashboards refresh all visible charts in parallel, utilizing all the resources the web browsers provide to quickly present the required charts. Since Netdata only stores metric data at the agents, all these queries are executed in parallel at the agents.
This parallelism of queries is even more intense when metrics replication/streaming is configured. In these cases, parent Netdata agents centralize metric data from many agents, and, since Netdata Cloud prefers the more distant parents for queries, they receive quite a few queries in parallel for all their children.
We also reworked many parts of the query engine of Netdata agents to achieve top performance in parallel queries. Now, Netdata agents are able to perform queries at a rate of more than 30 million points per second, per core on modern hardware. On a parent Netdata agent with a 24-core CPU we observed a sustained rate of 1.3 billion points per second! This is 3 times faster compared to the previous release.
To achieve this performance improvements we worked in these areas:
Query memory management
When querying metric data, a lot of memory allocations need to happen. Although Netdata agents automatically adapt their memory requirements for data collection avoiding memory operations while iterating to collect data, unfortunately at the query engine site, this is not feasible.
To make the agent more efficient for queries, the number of system calls allocating memory had to be drastically decreased. So, we developed a One Way Allocator (OWA), a system that works like a scratchpad for memory allocations. When the query starts, we now predict the amount of memory needed to execute the query. The query engine still does all the individual allocations, but all these are now made against the scratchpad, not against the system. OWA is smart enough to increase the size of the scratchpad if needed during querying. And it frees all memory at once without the need for individual memory releases.
For huge data queries, the benefit is astonishing. For certain heavy data queries, 45000 memory allocations before are down to 20 with this release! This doubled the performance of the query engine.
Number unpacking
To optimize its memory footprint for metric data, Netdata agents store collected metric data into a fixed step database (after interpolation) with a custom floating point number format we developed (we call it storage_number), requiring just 4 bytes per data collection point, including the timestamp. When on disk, mainly due to compression, Netdata's dbengine needs just 0.34 bytes per point (including all metadata), which is probably the best among all monitoring solutions available today, allowing Netdata to massively store and manage metric data at a very high rate.
This means however, that in order to actually use a point in a query, we have to unpack it. This unpacking happens point-by-point even for data cached in memory. 1 billion points in a data query, 1 billion numbers unpacked.
In this release we analyzed the CPU cache efficiency of the number unpacking and we refactored it to make the best use of available CPU caches to finally increase its performance by 30%.
Streaming
This release includes a better algorithm to pick the available parent to stream metrics to. The previous version was always reconnecting to the first available parent. Now it rotates them, one by one and then restarts.
An issue was fixed regarding parents with stale alerts from disconnected children. Now, the parent validates all alerts on every child re-connection.
Netdata parents now have a timeout to cleanup dead/abandoned children connections automatically.
We also worked to eliminate most of the bottlenecks when multiple children connect to the same parent. But this is still under testing, so it will make it in the next release.
More optimizations
Workers optimizations
Netdata uses many workers to execute several of its features. There are web workers, aclk workers, dbengine
workers, health monitoring workers, libuv workers, and many more.
We manage to identify a lot of deadlocks happening that slowed down the whole operation. We also
increased the amount of workers to deliver more capacity on busy parents.
There is a new section for monitoring Netdata workers at the "Netdata Monitoring" section of the dashboard. Using this
work we are still working to make them even more efficient.
Deadlocks
The last release was hindered by rare deadlocks on very busy parents. These deadlocks are now gone, improving the agents ability to centralize data from many children.
Dictionaries are now using Judy arrays
Judy arrays are probably the fastest and most CPU cache-friendly indexes available. Netdata already uses them for
dbengine and its page cache. Now all Netdata dictionaries are using them too, giving a performance boost to all
dictionary operations, including StatsD.
/proc collectors are now a lot faster >
Initialization of /proc collectors was suboptimal, because they had to go over a slow process or adapting their read
buffers. We added a forward-looking algorithm to optimize this initialization, which now happens in 1/10th of the
time.
/proc/netdev collector is now isolated
Some users have experiences gaps in /proc plugin charts. We identified that these gaps were triggered by the netdev module, which were cause the whole plugin to slow down and miss data collection iterations.
Now the netdev module of /proc plugin runs on its own thread to avoid this influencing the rest of the /proc
modules.
Internal Web Server optimizations
The internal web server of Netdata now spreads the work among its worker threads more evenly, utilizing as much of the
parallelism that is available to it.
Options in netdata.conf re-organized
We re-organized the [global] section of the netdata.conf, so that it is more meaningful for new users. The new
configurations are backward compatible. So, after you restart netdata with your old netdata.conf, grab the new one
from http://localhost:19999/netdata.conf to have the new format.
New MQTT Client - Tech Preview
We now have our own MQTT implementation within our ACLK protocol that will eventually replace the current MQTT-C client
for several reasons, including the following:
- With the new MQTT implementation we now support MQTTv5 as our older implementation only supported MQTTv3
- Reduce memory usage - no need for large fixed size buffers to be allocated all the time
- Reduce memory copying - no need to copy message contents multiple times
- Remove max message size limit
- Remove issues where big messages are starving other messages
Currently, it’s provided as a tech preview, and it’s disabled by default. Feel free to have some fun with the new
implementation. This is how to enable it in netdata.conf:
[cloud]
mqtt5 = yes
Acknowledgments
- @JaphethLim for adding priority to Gotify notifications.
- @MarianSavchuk for adding Alma and Rocky distros as CentOS compatibility distro in
netdata-updater. - @aberaud for working on configurable storage engine.
- @atriwidada for improving package dependency.
- @coffeegrind123 for adding Gotify notification method.
- @eltociear for fixing "GitHub" spelling in docs.
- @fqx for adding
tailscaledto apps_groups.conf. - @k0ste for updating
net,aws, andhagroups in apps_groups.conf. - @kklionz for fixing a compilation warning.
- @olivluca for fixing appending logs to the old log file after logrotate on Debian.
- @petecooper for improving the usage message in netdata-installer.
- @simon300000 for adding
caddyto apps_groups.conf.
Contributions
Collectors
New
- Add "UPS Load Usage" in Watts chart (charts.d/apcupsd) (#12965, @ilyam8)
- Add Pressure Stall Information stall time charts (proc.plugin, cgroups.plugin) (#12869, @ilyam8)
- Add "CPU Time Relative Share" chart when running inside a K8s cluster (cgroups.plugin) (#12741, @ilyam8)
- Add a collector that parses the log files of the OpenVPN server (go.d/openvpn_status_log) (#675, @surajnpn)
Improvements
⚙️ Enhancing our collectors to collect all the data you need.
Show 14 more contributions
- Add Tailscale apps_groups.conf (apps.plugin) (#13033, @fqx)
- Skip collecting network interface speed and duplex if carrier is down (proc.plugin) (#13019, @vlvkobal)
- Run the /net/dev module in a separate thread (proc.plugin) (#12996, @vlvkobal)
- Add dictionary support to statsd (#12980, @ktsaou)
- Add an option to filter the alarms (python.d/alarms) (#12972, @andrewm4894)
- Update net, aws, and ha groups in apps_groups.conf (apps.plugin) (#12921, @k0ste)
- Add k8s_cluster_name label to cgroup charts in K8s on GKE (cgroups.plugin) (#12858, @ilyam8)
- Exclude Proxmox bridge interfaces (proc.plugin) (#12789, @ilyam8)
- Add filtering by cgroups name and improve renaming in K8s (cgroups.plugin) (#12778, @ilyam8)
- Execute the renaming script only for containers in K8s (cgroups.plugin) (#12747, @ilyam8)
- Add k8s_qos_class label to cgroup charts in K8s (cgroups.plugin) (#12737, @ilyam8)
- Reduce the CPU time required for cgroup-network-helper.sh (cgroups.plugin) (#12711, @ilyam8)
- Add Proxmox VE processes to apps_groups.conf (apps.plugin) (#12704, @ilyam8)
- Add Caddy to apps_groups.conf (apps.plugin) (#12678, @simon300000)
Bug fixes
🐞 Improving our collectors one bug fix at a time.
Show 11 more contributions
- Fix adding wrong labels to cgroup charts (cgroups.plugin) (#13062, @ilyam8)
- Fix cpu_guest chart context (apps.plugin) (#12983, @ilyam8)
- Fix counting unique values in Sets (statsd.plugin) (#12963, @ktsaou)
- Fix collecting data from uninitialized containers in K8s (cgroups.plugin) (#12912, @ilyam8)
- Fix CPU-specific data in the "C-state residency time" chart dimensions (proc.plugin) (#12898, @vlvkobal)
- Fix memory usage calculation by considering ZFS ARC as cache on FreeBSD (freebsd.plugin)(#12879, @vlvkobal)
- Fix disabling K8s pod/container cgroups when fail to rename them (cgroups.plugin) (#12865, @ilyam8)
- Fix memory usage calculation by considering ZFS ARC as cache on Linux (proc.plugin) (#12847, @ilyam8)
- Fix adding network interfaces when the cgroup proc is in the host network namespace (cgroups.plugin) (#12788, @ilyam8)
- Fix not setting chart units (go.d/snmp) (#682, @ilyam8)
- Fix not collecting Integer type values (go.d/snmp) (#680, @surajnpn)
eBPF
- Add CO-RE algorithms to all threads related to memory (#12684, @thiagoftsm)
- Fix wrong chart type for ip charts (#12698, @thiagoftsm)
- Fix disabled apps (ebpf.plugin) (#13044, @thiagoftsm)
- Fix "libbpf: failed to load" warnings (#12831, @thiagoftsm)
- Re-enable socket module by default (#12702, @ilyam8)
Health
- Fix not respecting host labels when creating alerts for children instances (#13053, @MrZammler)
- Expose anomaly-bit option to health (#12835, @vkalintiris)
- Add priority to Gotify notifications to trigger sound & vibration on the Gotify phone app (#12753, @JaphethLim)
- Add Gotify notification method (#12639, @coffeegrind123)
Streaming
- Improve failover logic when the Agent is configured to stream to multiple destinations (#12866, @MrZammler)
- Increase the default "buffer size bytes" to 10MB (#12913, @ilyam8)
Exporting
- Add the URL query parameter that filters charts from the /allmetrics API query (#12820, @vlvkobal)
- Make the "send charts matching" option behave the same as the "filter" URL query parameter for prometheus format (#12832, @ilyam8)
Documentation
📄 Keeping our documentation healthy together with our awesome community.
Show 11 more contributions
- Add note about Anomaly Advisor (#13042, @andrewm4894)
- Add a note on possibly alternate location of the cloud.d directory (#12987, @cakrit)
- Improve instructions on how to reconnect a node to Cloud (#12891, @cakrit)
- Fix unresolved file references (#12872, @ilyam8)
- Update ML defaults in docs (#12782, @andrewm4894)
- Add parent-child configuration examples to ML docs (#12734, @andrewm4894)
- Add a note about serial numbers in chart names in the plugins.d API documentation (#12733, @vlvkobal)
- Fix a typo in macOS documentation (#12724, @MrZammler)
- Add a description of interactive/non-interactive modes to the "Uninstall Netdata" doc (#12687, @odynik)
- Fix "GitHub" spelling (#12682, @eltociear)
- Add new dashboard/web server reference file (#11161, @joelhans)
Packaging / Installation
📦 "Handle with care" - Just like handling physical packages, we put in a lot of care and effort to publish beautiful
software packages.
Show 29 more contributions
- Add Alma Linux 9 and RHEL 9 support to CI and packaging (#13058, @Ferroin)
- Fix handling of temp directory in kickstart when uninstalling (#13056, @Ferroin)
- Only try to update repo metadata in updater script if needed (#13009, @Ferroin)
- Use printf instead of echo for printing collected warnings in kickstart (#13002, @Ferroin)
- Don't kill Netdata PIDs if successfully stopped Netdata in installer/uninstaller (#12982, @ilyam8)
- Properly handle the case when 'tput colors' does not return a number in kickstart (#12979, @ilyam8)
- Update libbpf version to v0.8.0 (#12945, @thiagoftsm)
- Update default fping version to 5.1 (#12930, @ilyam8)
- Update go.d.plugin version to v0.32.3 (#12862, @ilyam8)
- Autodetect channel for specific version in kickstart (#12856, @maneamarius)
- Fix "Bad file descriptor" error in netdata-uninstaller (#12828, @maneamarius)
- Add support for installing static builds on systems without usable internet connections (#12809, @Ferroin)
- Add --repositories-only option to kickstart (#12806, @maneamarius)
- Rename --install option for kickstart.sh (#12798, @maneamarius)
- Fix to avoid recompiling protobuf all the time (#12790, @ktsaou)
- Fix non-interpreted new lines when printing deferred errors in netdata-installer (#12786, @ilyam8)
- Fix a typo in the warning() function in netdata-installer (#12781, @ilyam8)
- Fix checking of environment file in netdata-updater (#12768, @Ferroin)
- Add a missing function and Alma and Rocky distros as CentOS compatibility distro to netdata-updater (#12757, @MarianSavchuk)
- Improve the usage message in netdata-installer (#12755, @petecooper)
- Make atomics a hard-dependency (#12730, @vkalintiris)
- Add --install-version flag for installing specific Netdata version to kickstart (#12729, @maneamarius)
- Correctly propagate errors and warnings up to the kickstart script from scripts it calls (#12686, @Ferroin)
- Fix not-respecting of NETDATA_LISTENER_PORT in docker healthcheck (#12676, @ilyam8)
- Add options to kickstart for explicitly passing options to installer code (#12658, @Ferroin)
- Improve handling of release channel selection in kickstart (#12635, @Ferroin)
- Treat auto-updates as a tristate internally in the kickstart script (#12634, @Ferroin)
- Include proper package dependency (#12518, @atriwidada)
- Fix appending logs to the old log file after logrotate on Debian (#9377, @olivluca)
Other Notable Changes
Improvements
⚙️ Greasing the gears to smoothen your experience with Netdata.
Show 43 more contributions
- Add hostname to mirrored hosts int the /api/v1/info endpoint (#13030, @ktsaou)
- Optimize query engine queries (#12988, @ktsaou)
- Optimize query engine and cleanup (#12978, @ktsaou)
- Improve the web server work distribution across worker threads (#12975, @ktsaou)
- Check link local address before querying cloud instance metadata (#12973, @ilyam8)
- Speed up query engine by refactoring rrdeng_load_metric_next() (#12966, @ktsaou)
- Optimize the dimensions option store to the metadata database (#12952, @stelfrag)
- Add detailed dbengine stats (#12948, @ktsaou)
- Stream Metric Correlation version to parent and advertise Metric Correlation status to the Cloud (#12940, @MrZammler)
- Move directories, logs, and environment variables configuration options to separate sections (#12935, @ilyam8)
- Adjust the dimension liveness status check (#12933, @stelfrag)
- Make sqlite PRAGMAs user configurable (#12917, @ktsaou)
- Add worker jobs for cgroup-rename, cgroup-network and cgroup-first-time (#12910, @ktsaou)
- Return stable or nightly based on version if the file check fails (#12894, @stelfrag)
- Take into account the in queue wait time when executing a data query (#12885, @stelfrag)
- Add fixes and improvements to workers library (#12863, @ktsaou)
- Pause alert pushes to the cloud (#12852, @MrZammler)
- Allow to use the new MQTT 5 implementation (#12838, @underhood)
- Set a page wait timeout and retry count (#12836, @stelfrag)
- Allow external plugins to create chart labels (#12834, @ilyam8)
- Reduce the number of messages written in the error log due to out of bound timestamps (#12829, @stelfrag)
- Cleanup the node instance table on startup (#12825, @stelfrag)
- Accept a data query timeout parameter from the cloud (#12823, @stelfrag)
- Write the entire request with parameters in the access.log file (#12815, @stelfrag)
- Add a parameter for how many worker threads the libuv library needs to pre-initialize (#12814, @stelfrag)
- Optimize linking of foreach alarms to dimensions (#12813, @vkalintiris)
- Add a hyphen to the list of available characters for chart names (#12812, @ilyam8)
- Speed up queries by providing optimization in the main loop (#12811, @ktsaou)
- Add workers utilization charts for Netdata components (#12807, @ktsaou)
- Fill missing removed events after a crash (#12803 , @MrZammler)
- Speed up buffer increases (minimize reallocs) (#12792, @ktsaou)
- Speed up reading big proc files (#12791, @ktsaou)
- Make dbengine page cache undumpable and dedupuble (#12765, @ilyam8)
- Speed up execution of external programs (#12759, @ktsaou)
- Remove per chart configuration (#12728, @vkalintiris)
- Check for chart obsoletion on children re-connections (#12707, @MrZammler)
- Add a 2 minute timeout to stream receiver socket (#12673, @MrZammler)
- Improve Agent cloud chart synchronization (#12655, @stelfrag)
- Add the ability to perform a data query using an offline node id (#12650, @stelfrag)
- Implement ks_2samp test for Metric Correlations (#12582, @MrZammler)
- Reduce alert events sent to the cloud (#12544, @MrZammler)
- Store alert log entries even if alert it is repeating (#12226, @MrZammler)
- Improve storage number unpacking by using a lookup table (#11048, @vkalintiris)
Bug fixes
🐞 Increasing Netdata's reliability one bug fix at a time.
Show 33 more contributions
- Fix locking access to chart labels (#13064, @stelfrag)
- Fix coverity 378625 (#13055, @MrZammler)
- Fix dictionary crash walkthrough empty (#13051, @ktsaou)
- Fix the retry count and netdata_exit check when running a sqlite3_step command (#13040, @stelfrag)
- Fix sending first time seen dimensions with zero timestamp to the Cloud (#13035, @stelfrag)
- Fix gap filling on dbengine gaps (#13027, @ktsaou)
- Fix coverity issue 378598 (#13022, @MrZammler)
- Fix coverity issue 378617,378615 (#13021, @stelfrag)
- Fix a dimension 100% anomaly rate despite no change in the metric value (#13005, @vkalintiris)
- Fix compilation warnings (#12993, @vlvkobal)
- Fix crash because of corrupted label message from streaming (#12992, @MrZammler)
- Fix nanosleep on platforms other than Linux (#12991, @vlvkobal)
- Fix disabling a streaming destination because of denied access (#12971, @MrZammler)
- Fix "unused variable" compilation warning (#12969, @kklionz)
- Fix virtualization detection on FreeBSD (#12964, @ilyam8)
- Fix buffer overflow when logging "command_to_be_logged" in analytics (#12947, @MrZammler)
- Fix "global statistics" section in netdata.conf (#12916, @ilyam8)
- Fix virtualization detection when systemd-detect-virt is not available (#12911, @ilyam8)
- Fix the log entry for incoming cloud start streaming commands (#12908, @stelfrag)
- Fix release channel in the node info message (#12905, @stelfrag)
- Fix alarms count in /api/v1/alarm_count (#12896, @MrZammler)
- Fix compilation warnings in FreeBSD (#12887, @vlvkobal)
- Fix multihost queries alignment (#12870, @stelfrag)
- Fix negative worker jobs busy time (#12867, @ktsaou)
- Fix reported by coverity issues related to memory and structure dereference (#12846, @stelfrag)
- Fix memory leaks and mismatches of the use of the z functions for allocations (#12841, @ktsaou)
- Fix using obsolete charts/dims in prediction thread (#12833, @vkalintiris)
- Fix not skipping ACLK dimension update when dimension is freed (#12777, @stelfrag)
- Fix coverity warning about not checking return value in receiver setsockopt (#12772, @MrZammler)
- Fix disk size calculation on macOS (#12764, @ilyam8)
- Fix "implicit declaration of function" compilation warning (#12756, @ilyam8)
- Fix Valgrind errors (#12619, @vlvkobal)
- Fix redirecting alert emails for a child to the parent (#12609, @MrZammler)
Code organization
🏋️ Changes to keep our code base in good shape.
Show 48 more contributions
- Update default value for "host anomaly rate threshold" (#13075, @shyamvalsan)
- Initialize chart label key parameter correctly (#13061, @stelfrag)
- Add the ability to merge dictionary items (#13054, @ktsaou)
- Dictionary improvements (#13052, @ktsaou)
- Coverity fixes about statsd; removal of strsame (#13049, @ktsaou)
- Replace
historywith relevantdbengineparams (#13041, @andrewm4894) - Schedule retention message calculation to a worker thread (#13039, @stelfrag)
- Check return value and log an error on failure (#13037, @stelfrag)
- Add additional metadata to the data response (#13036, @stelfrag)
- Dictionary with JudyHS and double linked list (#13032, @ktsaou)
- Initialize a pointer and add a check for it (#13023, @vlvkobal)
- Autodetect coverity install path to increase robustness (#12995, @maneamarius)
- Don't expose the chart definition to streaming if there is no metadata change (#12990, @stelfrag)
- Make heartbeat a static chart (#12986, @MrZammler)
- Return rc->last_update from alarms_values api (#12968, @MrZammler)
- Suppress warning when freeing a NULL pointer in onewayalloc_freez (#12955, @stelfrag)
- Trigger queue removed alerts on health log exchange with cloud (#12954, @MrZammler)
- Defer the dimension payload check to the ACLK sync thread (#12951, @stelfrag)
- Reduce timeout to 1 second for getting cloud instance info (#12941, @MrZammler)
- Add links to SQLite init options in the src code (#12920, @ilyam8)
- Remove "enable new cgroups detected at run time" config option (#12906, @ilyam8)
- Log an error when re-registering an already registered job (#12903, @ilyam8)
- Use correct identifier when registering the main thread "chart" worker job (#12902, @ilyam8)
- Change duplicate health template message logging level to 'info' (#12873, @ilyam8)
- Initialize the metadata database when performing dbengine stress test (#12861, @stelfrag)
- Add a SQLite database checkpoint command (#12859, @stelfrag)
- Broadcast completion before unlocking condition variable's mutex (#12822, @vkalintiris)
- Switch to mallocz() in onewayallocator (#12810, @ktsaou)
- Configurable storage engine for Netdata Agents: step 2 (#12808, @aberaud)
- Move kickstart argument parsing code to a function. (#12805, @Ferroin)
- Remove python.d/* announced in v1.34.0 deprecation notice (#12796, @ilyam8)
- Don't use MADV_DONTDUMP on non-linux builds (#12795, @vkalintiris)
- One way allocator to double the speed of parallel context queries (#12787, @ktsaou)
- Trace rwlocks of netdata (#12785, @ktsaou)
- Configurable storage engine for Netdata Agents: step 1 (#12776, @aberaud)
- Some config updates for ML (#12771, @andrewm4894)
- Remove node.d.plugin and relevant files (#12769, @surajnpn)
- Use aclk_parse_otp_error on /env error (#12767, @underhood)
- Remove "search for cgroups under PATH" conf option to fix memory leak (#12752, @ilyam8)
- Remove "enable cgroup X" config option on cgroup deletion (#12746, @ilyam8)
- Remove undocumented feature reading cgroups-names.sh when renaming cgroups (#12745, @ilyam8)
- Reduce logging in rrdset (#12739, @ilyam8)
- Avoid clearing already unset flags. (#12727, @vkalintiris)
- Remove commented code (#12726, @vkalintiris)
- Remove unused
--auto-updateoption when using static/build install method (#12725, @ilyam8) - Allocate buffer memory for uv_write and release in the callback function (#12688, @stelfrag)
- Implements new capability fields in aclk_schemas (#12602, @underhood)
- Cleanup Challenge Response Code (#11730, @underhood)
Deprecation notice
The following items will be removed in our next minor release (v1.36.0):
Patch releases (if any) will not be affected.
| Component | Type | Will be replaced by |
|---|---|---|
| python.d/chrony | collector | go.d/chrony |
| python.d/ovpn_status_log | collector | go.d/openvpn_status_log |
All the deprecated components will be moved to the netdata/community repository.
Deprecated in this release
In accordance with our previous deprecation notice, the following items have been removed in this release:
| Component | Type | Replaced by |
|---|---|---|
| node.d | plugin | - |
| node.d/snmp | collector | go.d/snmp |
| python.d/apache | collector | go.d/apache |
| python.d/couchdb | collector | go.d/couchdb |
| python.d/dns_query_time | collector | go.d/dnsquery |
| python.d/dnsdist | collector | go.d/dnsdist |
| python.d/elasticsearch | collector | go.d/elasticsearch |
| python.d/energid | collector | go.d/energid |
| python.d/freeradius | collector | go.d/freeradius |
| python.d/httpcheck | collector | go.d/httpcheck |
| python.d/isc_dhcpd | collector | go.d/isc_dhcpd |
| python.d/mysql | collector | go.d/mysql |
| python.d/nginx | collector | go.d/nginx |
| python.d/phpfpm | collector | go.d/phpfpm |
| python.d/portcheck | collector | go.d/portcheck |
| python.d/powerdns | collector | go.d/powerdns |
| python.d/redis | collector | go.d/redis |
| python.d/web_log | collector | go.d/weblog |
Platform Support Changes
This release adds official support for the following platforms:
- RHEL 9.x, Alma Linux 9.x, and other compatible RHEL 9.x derived platforms
- Alpine Linux 3.16
This release removes official support for the following platforms:
- Fedora 34 (support ended due to upstream EOL).
- Alpine Linux 3.12 (support ended due to upstream EOL).
This release includes the following additional platform support changes.
- We’ve switched from Alpine 3.15 to Alpine 3.16 as the base for our Docker images and static builds. This should not
require any action on the part of users, and simply represents a version bump to the tooling included in our Docker
images and static builds. - We’ve switched from Rocky Linux to Alma Linux as our build and test platform for RHEL compatible systems. This will
enable us to provide better long-term support for such platforms, as well as opening the possibility of better support
for non-x86 systems.
Netdata Agent Release Meetup
Join the Netdata team on the 9th of June at 5pm UTC for the Netdata Agent Release Meetup, which will be held on
the Netdata Discord.
Together we’ll cover:
- Release Highlights
- Acknowledgements
- Q&A with the community
RSVP now - we look forward to
meeting you.
Support options
As we grow, we stay committed to providing the best support ever seen from an open-source solution. Should you encounter
an issue with any of the changes made in this release or any feature in the Netdata Agent, feel free to contact us
through one of the following channels:
- Netdata Learn: Find documentation, guides, and reference material for monitoring and
troubleshooting your systems with Netdata. - GitHub Issues: Make use of the Netdata repository to report bugs or open
a new feature request. - GitHub Discussions: Join the conversation around the Netdata
development process and be a part of it. - Community Forums: Visit the Community Forums and contribute to the collaborative
knowledge base. - Discord: Jump into the Netdata Discord and hangout with like-minded sysadmins,
DevOps, SREs and other troubleshooters. More than 1100 engineers are already using it!