workflow for moving data to cloud #48
Comments
|
Here is an alternative, more "cloudy" way this might work:
In this case, we would end up with many zarr stores, just like we have many netcdf files. We would need an |
|
Can you get a sense for what the bottleneck is? I/O? Compression? |
|
My first response would be "neither," since neither the system CPU (5%) nor outbound IP traffic (~20,000 kilobit/s) is anywhere close to saturated. Reading the data from disk could also be a bottleneck, especially if each of these 24 threads is accessing a different, random chunk of the data. From the timing of the tasks above, reading and writing seem to be similar. But maybe I am not measuring correctly. |
|
If you're using the dask.distributed scheduler (which given the images above, you probably are) I recommend looking at the "Profile" tab. |
|
You could also consider changing the threads/processes mixture using the |
|
I don't have a "Profile" tab. I guess my distributed version is out of date. I do have a "System" tab. Thanks for the suggestions about profiling. I will try to do some more systematic profiling. For now I just wanted to get the transfer started, and I am reluctant to interrupt it. |
|
Yeah, you might consider upgrading at some point. Doc page on the profiler: http://distributed.readthedocs.io/en/latest/diagnosing-performance.html#statistical-profiling
|
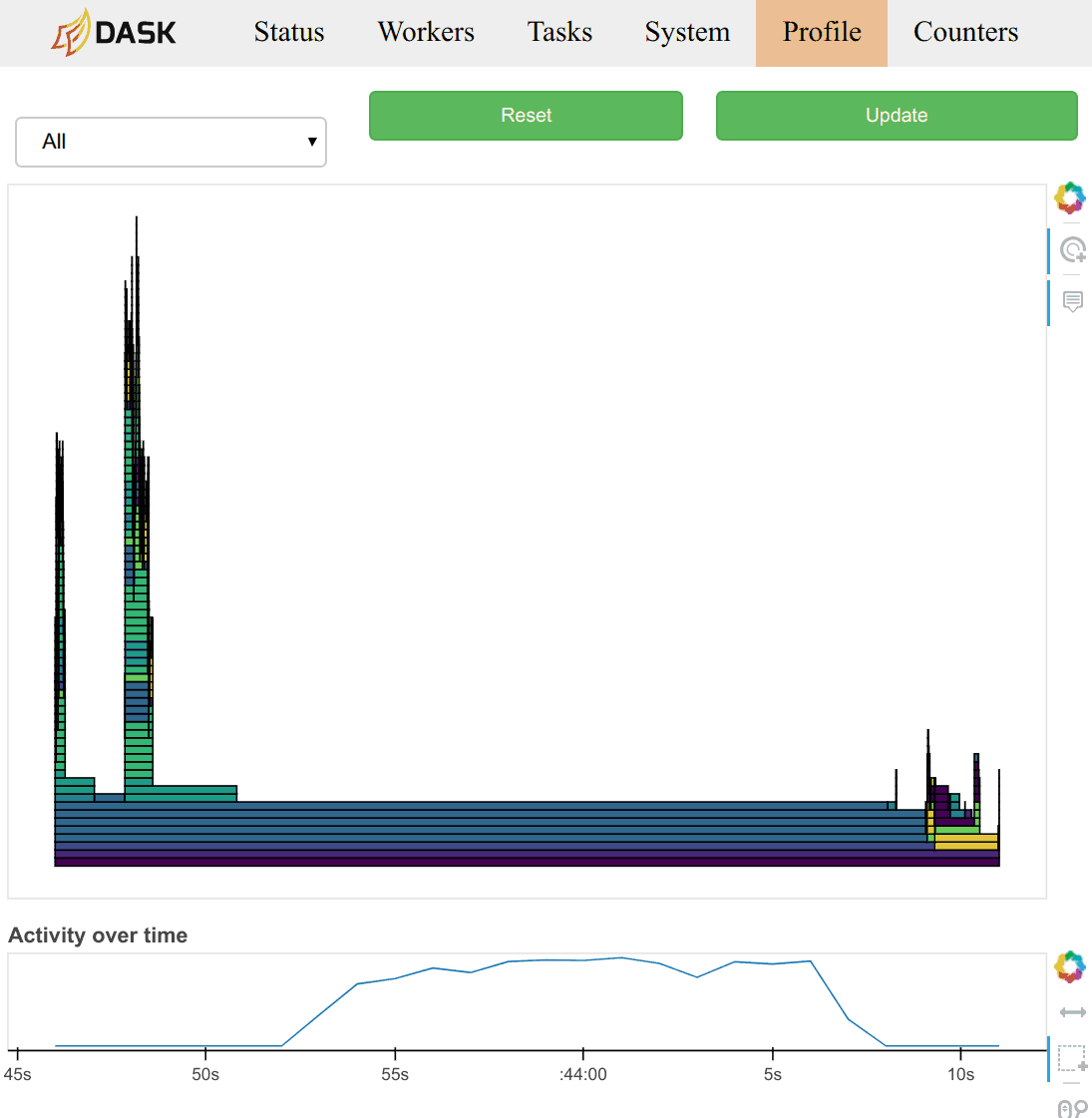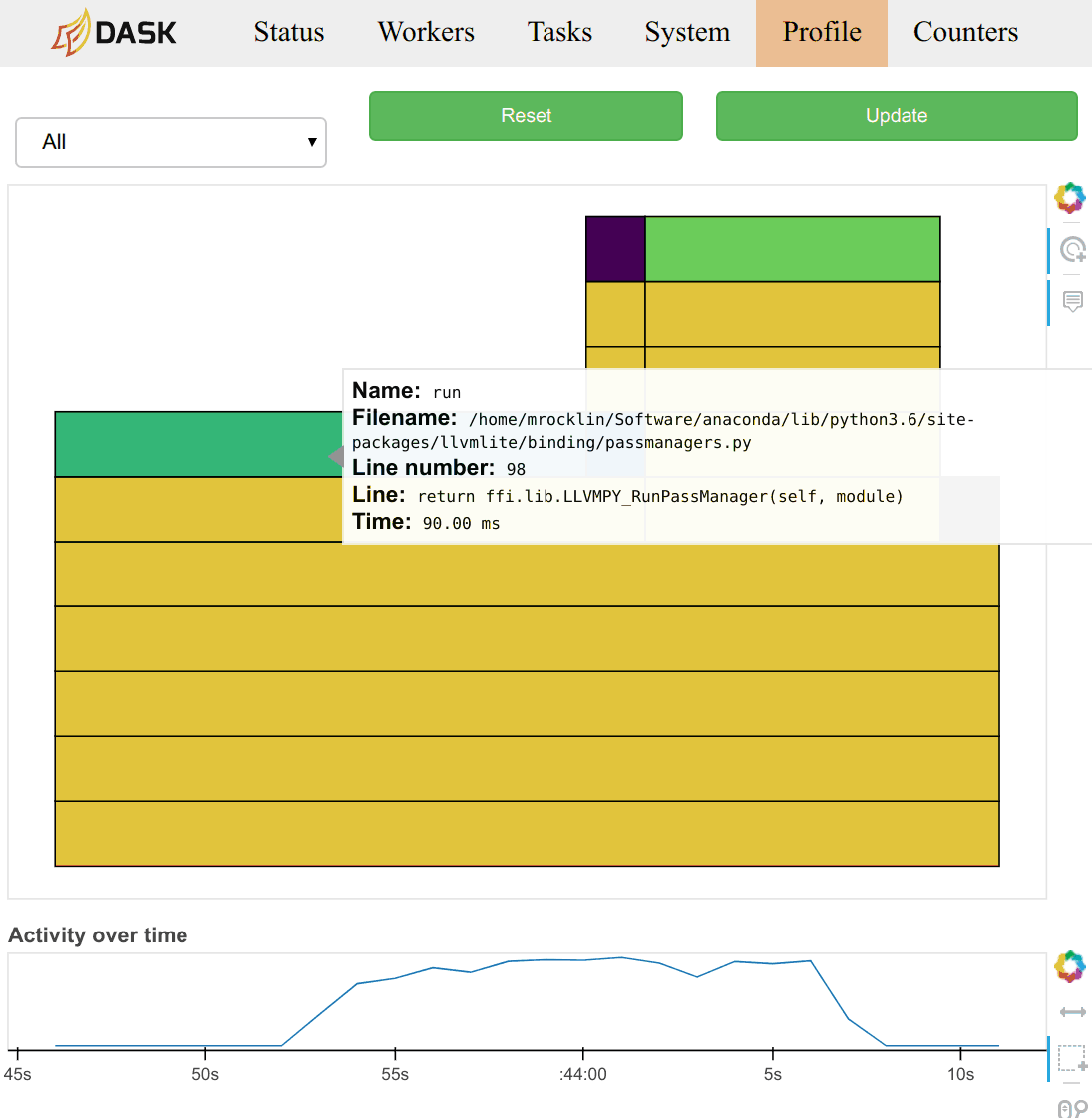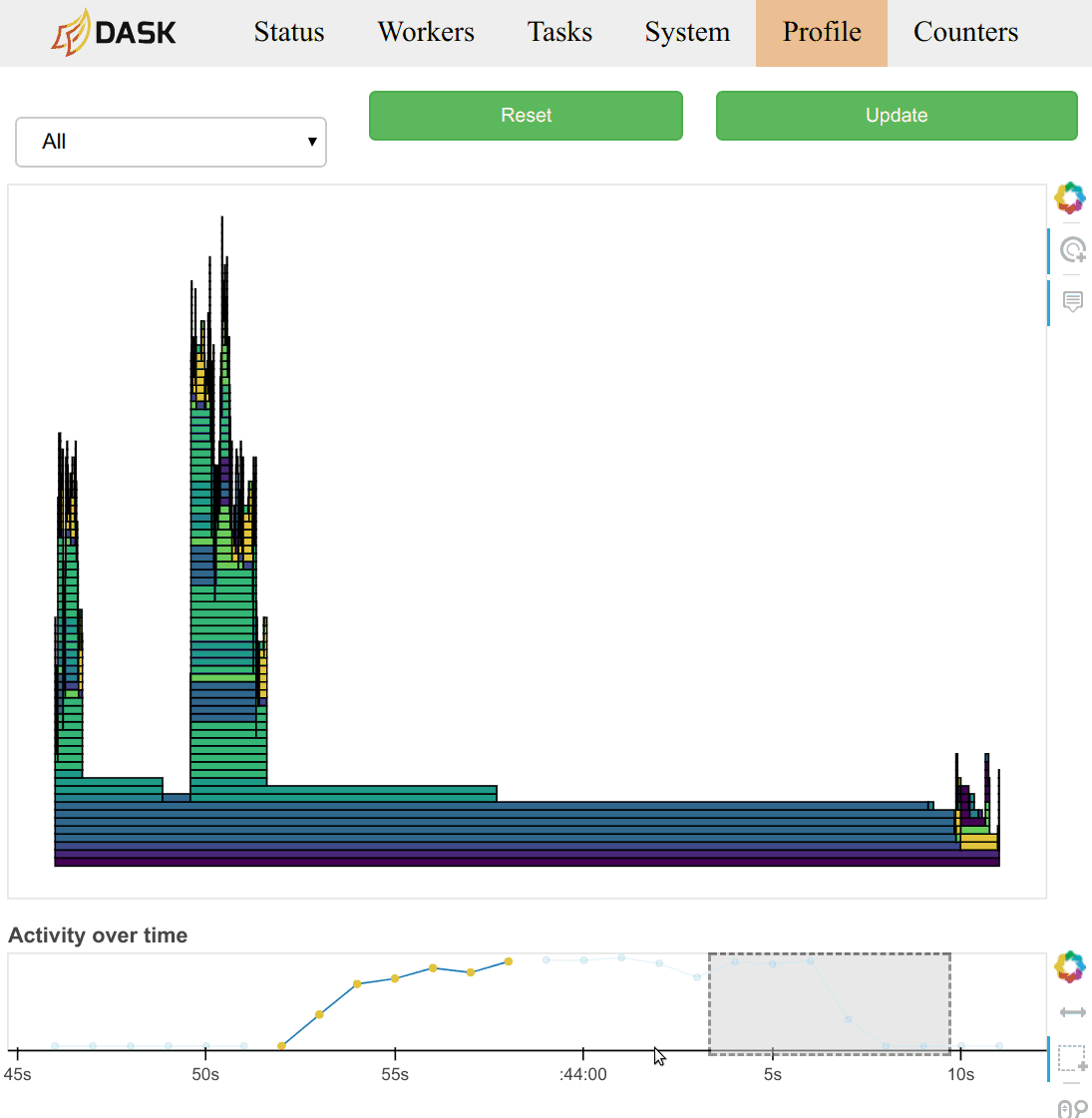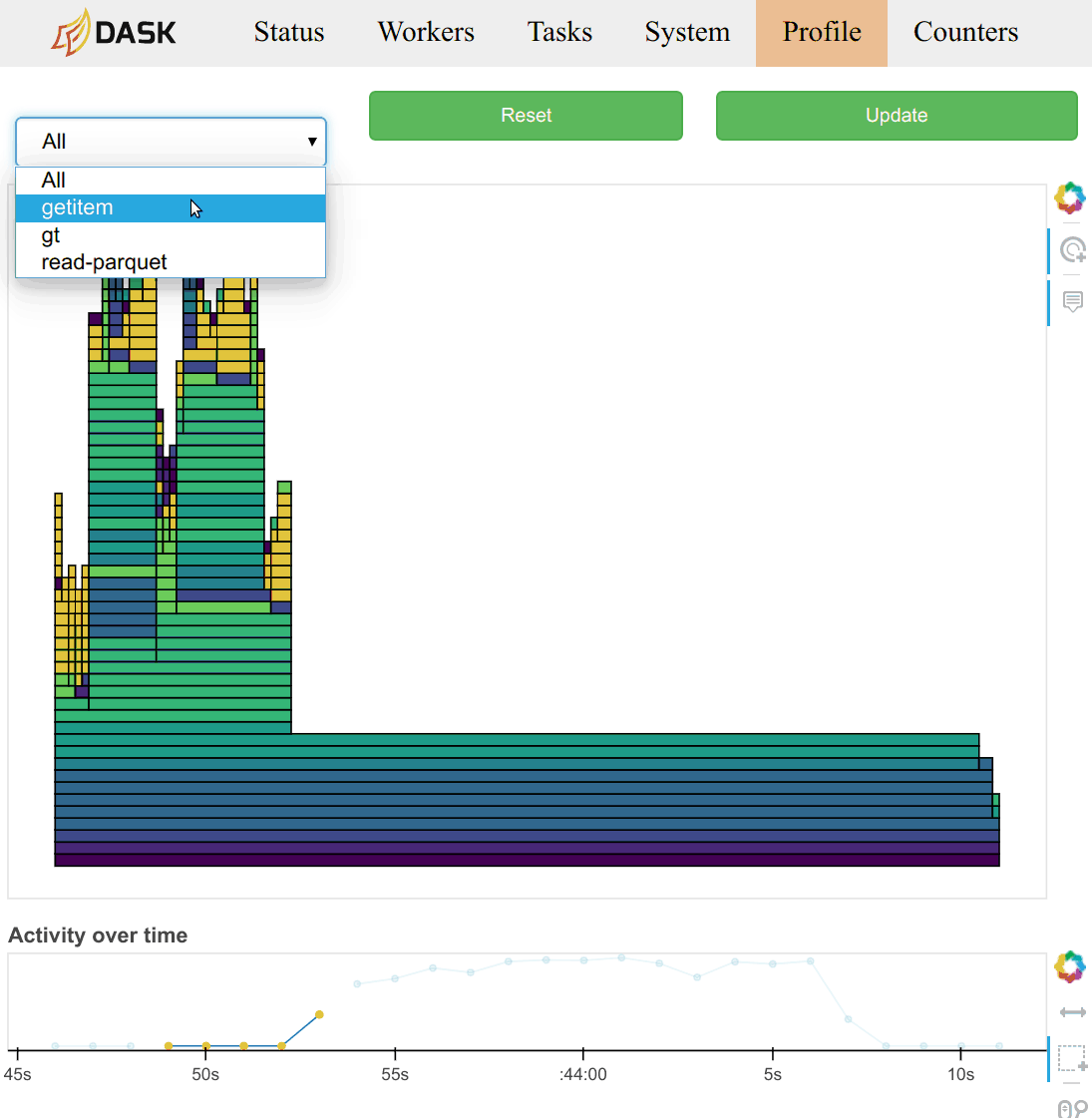
|
Yes, that definitely would have been good to have! |
|
Looks like I am on track to do about 100 GB in one day. At this rate, it will take 100 days to upload the dataset. @jhamman - did you have similar performance with the Newmann Met ensemble? |
|
Heh, I recommend profiling and looking at using more processes. |
|
This server does not have more processes available. (I am not on a cluster
here, just our own data server.) I will interrupt the transfer and set up
more careful profiling.
…-Ryan
On Tue, Dec 12, 2017 at 9:35 AM, Matthew Rocklin ***@***.***> wrote:
Heh, I recommend profiling and looking at using more processes.
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#48 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ABJFJtl4Fz7ULLq2hfnZGodmlZx7KAtjks5s_o9HgaJpZM4Q98RA>
.
|
|
I meant that you might consider using more processes and fewer threads per process client = Client(n_workers=4, threads_per_worker=4) |
Yes. I'm not sure I ever got past the setup / serialization step. |
|
@rabernat and @mrocklin - I'm using fsspec/gcsfs#49 and the xarray/master branch to move data to GCP now. Initialization was much faster. I'll report back if/when this completes. |
|
I'm glad that the initialization bottleneck seems to be solved! I still think we have a lot of work ahead figuring out how to tune chunks / compression / n_procs / n_threads to efficiently move data into the cloud using this method. |
|
FYI, I have been playing around with |
|
@rabernat in your situation I might try dumping a tiny xarray dataset to zarr and profile the operation, seeing which parts of the process take up the most time. I generally use the %load_ext snakeviz
%snakeviz ds.to_zarr(...) |
|
@jhamman checking in, were you able to upload anything to GCS or is Geyser still down? |
|
Reporting back after doing a bit of profiling on a ~21Mb dataset. For the tests I'm reporting now, I persisted the dataset into memory prior to writing to the zarr store. I also compared writing to a local store on a SSD. I have attached the results from running the As a teaser, here is a snapshot from snakeviz.
The outermost gray ring is Finally, here is the notebook I used to generate these tests. |

|
_thread.lock.acquire is a sign that this is using the multithreaded scheduler, which is difficult to profile. Can you try a second time with |
|
Ah, I see that you're using a client. We might want to avoid this when profiling. Although the |
|
@mrocklin - See attached profiles using |
|
@martindurant may want to see this. There is a lot of time spent in operations like Also interesting is that most of the time is spent in @jhamman I might suggest rechunking your data differently to have fewer larger chunks, and then see how that affects bandwidth. I suspect that we are mostly bound here by administrative checkins with GCS and not by compressing or sending bytes. |
|
I tried another chunk configuration (5 chunks per dataarray) and the throughput went from 380s to 405s (slower). I'm also curious about the |
|
Yeah you're right, it looks like we load in all of the data to the local process. AbstractWritableDataStore.set_variables calls Where This appears to be about 120s of your 400s |
|
Another issue seems to be excessive metadata/attrs collection. For example we seem to be creating around 100 Zarr arrays. In each case we seem to spend around 60ms getting metadata, resulting in around 60s of lost time. Two questions:
|
|
We seem to spend a long time dealing with attrs. Each of these can take some time. More broadly, every time we touch the GCS mapping from far away there is a non-trivial cost. It appears that XArray-on-Zarr touches the mapping frequently. I wonder if there is some way to fill out all of our metadata locally and then push that up to GCS in a single go. |
|
@martindurant do you have any thoughts on long-running connections and gcsfs? Is this feasible to avoid the thousand small SSL handshakes we're doing here? |
|
Ouch. The The change on the xarray side was here: https://github.com/pydata/xarray/pull/1609/files#diff-e7faa2e88465688f603e8f1f6d4db821R226 |
|
This is pretty fascinating. Some of the backend optimizations required to improve this could potentially be combined with pydata/xarray#1087. Fetching attributes lazily sounds like a low hanging fruit. |
|
I have implemented a somewhat unsatisfactory fix for the xarray issue. I'm testing it now and will try to get it completed today. |
I would expect the number to be closer to 38 arrays (7variables x 5 chunks + 3 coordinates). Below are some updated profiles using the changes in pydata/xarray#1799. |
|
Now it looks like the biggest issue is in attribute handling and preparing the variables prior to sending data? |
|
I'm still confused/concerned about the amount of time we spend with the SSL handshakes. |
|
SSL handshakes are expensive, especially if you are far away from the other destination. There are several network roundtrips to do the full handshake. Currently gcsfs does this handshake every time we touch any piece of data. I hope that we can reduce this with long-running connections or Sessions. @martindurant would know more though, I suspect that he has thought about this before. |
|
@jhamman you should also try merging in fsspec/gcsfs#22 . I suspect that your times will go down significantly |
|
Just looking at the code in Zarr for reading attributes, currently every
time an attribute is accessed the '.zattrs' key is retrieved from the
store. I think it would be sensible to add an option to Zarr to cache the
attributes, turned on by default.
…On Fri, Dec 22, 2017 at 1:16 AM, Matthew Rocklin ***@***.***> wrote:
@jhamman <https://github.com/jhamman> you should also try merging in
fsspec/gcsfs#22 <fsspec/gcsfs#22> . I suspect that
your times will go down significantly
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#48 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAq8QpnD_PCPAC1s73DbUOq1MnfT9yUhks5tCwLogaJpZM4Q98RA>
.
--
Alistair Miles
Head of Epidemiological Informatics
Centre for Genomics and Global Health <http://cggh.org>
Big Data Institute Building
Old Road Campus
Roosevelt Drive
Oxford
OX3 7LF
United Kingdom
Phone: +44 (0)1865 743596
Email: alimanfoo@googlemail.com
Web: http://a <http://purl.org/net/aliman>limanfoo.github.io/
Twitter: https://twitter.com/alimanfoo
|
|
@mrocklin and @alimanfoo - I just tried my little test case again with fsspec/gcsfs#22, fsspec/gcsfs#49, and https://github.com/alimanfoo/zarr/pull/220. I've had to move to a new machine so the tests are not going to be a perfect match but it seems like we've cut down the number of SSL_read calls from 345228 to 6910. This seems to be yielding about a 5x speedup. That said, it still takes about 60 seconds to push 20 Mb so there is probably still room for improvement. Snakeviz ready profile is attached. |
|
Glad things are going in the right direction. I'll take a look at the
profile data in the new year, see if anything else can be done on the zarr
side.
|
|
Btw don't know if this is relevant, but if you're setting multiple
attributes on a single array of group, you can save some communication by
calling o.attrs.update(...) rather than making multiple calls to
o.attrs['foo'] = 'bar' etc. Probably some ways to shave off even more
communication beyond this too.
|
|
Thanks @alimanfoo. I just opened a xarray PR (pydata/xarray#1800) that uses |
|
Great, glad that was useful.
|
|
Does fsspec/gcsfs#55 impact the performance? Previously, there was no Session invoked, I think now some connections should be reusable. |
|
@martindurant - yes, that moved the mark from ~35 seconds to ~25 seconds thanks to a sharp decrease in the number of ssl read calls (1885 vs 6910): This is using zarr-master, pydata/xarray#1800, and the gcsfs combination of fsspec/gcsfs#22, fsspec/gcsfs#49, and fsspec/gcsfs#55. An updated profile is attached: program_to_zarr_gcsfs.prof.zip |
|
Closed by a combination of pydata/xarray#1800, fsspec/gcsfs#22, fsspec/gcsfs#49, fsspec/gcsfs#55, and zarr-developers/zarr-python#220. |
|
This could probably still use some documentation to help other groups (like @rabernat 's) push relevant data to the cloud |
|
I am eager to try this out. I guess I just have to update my xarray, gcsfs, and zarr to latest master? Or are there other steps that need to be documented? |
|
gcsfs was just released, so a normal conda update should do for that one. |
|
Thank you for keeping up with work on |
|
Zarr 2.2 not released yet (hoping to get to that soon) so latest master.
…On Wed, Jan 24, 2018 at 3:49 PM, Matthew Rocklin ***@***.***> wrote:
Thank you for keeping up with work on gcsfs @martindurant
<https://github.com/martindurant> . It was very useful to have your time
on this.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#48 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAq8Qibc5pGEsTh0NFmiE4gysjPCYB9gks5tN1EUgaJpZM4Q98RA>
.
--
Alistair Miles
Head of Epidemiological Informatics
Centre for Genomics and Global Health <http://cggh.org>
Big Data Institute Building
Old Road Campus
Roosevelt Drive
Oxford
OX3 7LF
United Kingdom
Phone: +44 (0)1865 743596
Email: alimanfoo@googlemail.com
Web: http://a <http://purl.org/net/aliman>limanfoo.github.io/
Twitter: https://twitter.com/alimanfoo
|
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
|
closing. @rabernat wrote: http://pangeo-data.org/data.html#guide-to-preparing-cloud-optimized-data This basically summarizes the best known workflow for moving zarr-like datasets to the cloud. |
I am currently transferring a pretty large dataset (~11 TB) from a local server to gcs.
Here is an abridged version basic workflow:
Each chunk in the dataset has 2700 x 3600 elements (about 75 MB), and there are 292000 total chunks in the dataset.
I am doing this through dask.distributed using a single, multi-threaded worker (24 threads). I am watching the progress through the dashboard.
Once I call
to_zarr, it takes a long time before anything happens (about 1 hour). I can't figure out what dask is doing during this time. At some point the client errors with the following exception:tornado.application - ERROR - Future <tornado.concurrent.Future object at 0x7fe371f58a58> exception was never retrieved. Nevertheless, the computation eventually hits the scheduler, and I can watch its progress.I can see that there are over 1 million tasks. Most of the time is being spent in tasks called
open_dataset-concatenateandstore-concatenate. There are 315360 of each task, and each takes about ~20s. Doing the math, at this rate it will take a couple of days to upload the data, this is slower than scp by a factor of 2-5.I'm not sure if it's possible to do better. Just raising this issue to start a discussion.
A command line utility to import netcdf directly to gcs/zarr would be a very useful tool to have.
The text was updated successfully, but these errors were encountered: