Bmm sparse dense #33430
Bmm sparse dense #33430
Conversation
💊 Build failures summary and remediationsAs of commit d01b921 (more details on the Dr. CI page):
XLA failureJob pytorch_xla_linux_xenial_py3_6_clang7_test is failing. Please create an issue with title prefixed by This comment was automatically generated by Dr. CI (expand for details).Follow this link to opt-out of these comments for your Pull Requests.Please report bugs/suggestions on the GitHub issue tracker. This comment has been revised 266 times. |
05ef9cc to
06b33ee
Compare
|
The clang-tidy check is failing to install clang-tidy: |
|
@pearu @nikitaved How about you guys do the first pass reviewing the algorithm? I can help with more framework review but I'd like you guys to do the bulk of the actual algorithm review. |
|
Below are charts of sparse-dense bmm's performance compared to a workaround function that someone posted to the original issue. My performance script is here: https://github.com/kurtamohler/pytorch-perf-test-scripts/blob/master/bmm-sparse-dense/bmm_perf.py The "input cases" that the x-axis refers to are the input size combinations found in the same order in the table below the charts. "Pre-coalescing" means that before bmm() is called, I'm coalescing the sparse matrix outside the timed loop so that it does not have to be done inside the timed bmm() call. Measuring with and without the pre-coalescing step allows us to see how much of an impact coalescing has on the run time. Note that the way the workaround works, it does not need a coalesced sparse matrix, so it can skip that step. It looks like coalescing increases run time significantly in some cases but not in others. The builtin methods are almost always faster than the workarounds, and CUDA is almost always faster than CPU.
Input cases:
|
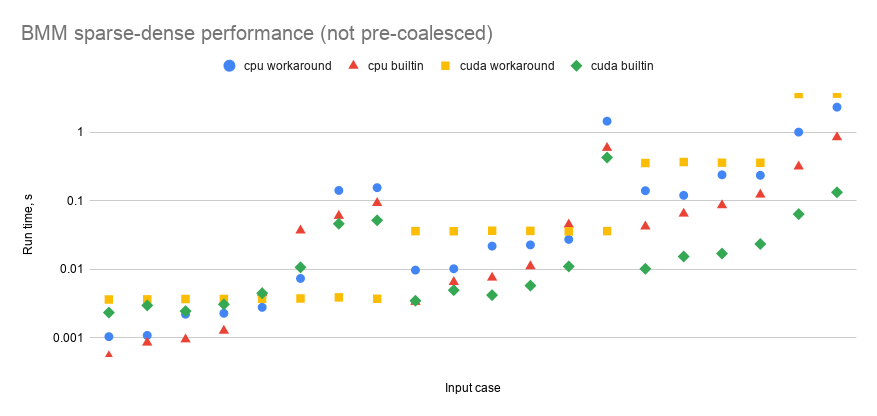
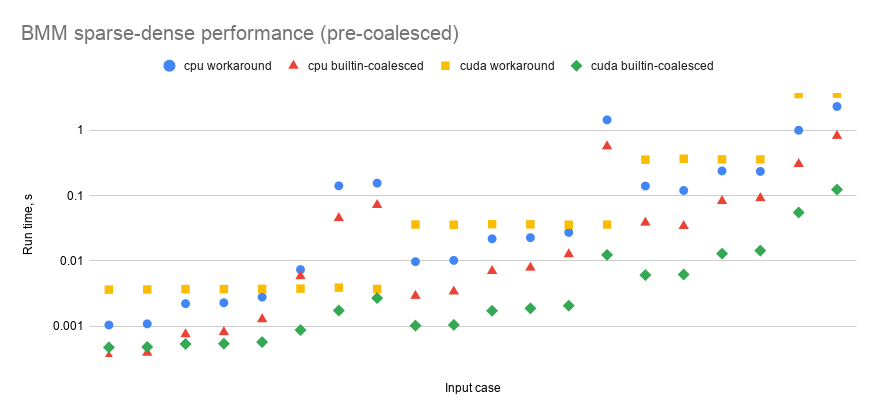
|
I'm getting some CI errors related to JIT: I'm not really sure what I need to do. |
|
@kurtamohler Alright, it's this problem. Can you split bmm into two functions, cc'ing @eellison if you have a better protocol. (I am aware that we could also just bash this out by finding the schema string in JIT and updating it, but I kind of don't want to do that here; I feel the JIT doesn't want to see the determinism flag.) |
|
@ezyang @kurtamohler is the error is in shape analysis because |
|
Alright well I'm not sure if what I just changed fixed the issue or not. I haven't figured out how to manually run the failing test. So I'll just let CI run it. |
716b27c to
f1aba62
Compare
|
Yesterday I discovered that my CPU implementation has a flaw in its method of searching the 3-D sparse tensor's indices for each 2-D matrix. Apparently, depending on how you create the sparse tensor, the tensor of indices can be laid out in either row-major or column-major order in memory. Looks like the Here is an example of how two different sparse tensors' index matrices can have different strides: I have a working fix to my search function that takes this into account, and I will push it shortly. |
035faa4 to
61c1f64
Compare
|
re the hip errors (cc @iotamudelta ) for now you should just ifdef out the code in the HIP case and say that it's not supported on HIP |
|
It looks like either missing features in ROCm or (more likely) a mishipification. Agreed with @ezyang that this can be ifdef'd out for now, we'll have a look what's up there and may also ping you if we need some input? |
|
Alright, thanks for letting me know. I'll put in the ifdef. |
61c1f64 to
dbc89bb
Compare
|
@peterjc123, I think you're right, |
There was a problem hiding this comment.
@ezyang is landing this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
|
Drat, it looks like our internal version of cusparse is too old. Is there a way you can add macro ifdefs that appropriate test the version of cusparse before making API calls? |
|
Alright, I changed the ifdefs so that an error is thrown if the cuda version is less than 10.1. I also added a test to make sure the error is being thrown correctly and skip the other tests if less than cuda 10.1. |
|
Looks like the macos environment doesn't have the |
There was a problem hiding this comment.
@ezyang has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
|
Darnit, the version string comparison module I was using doesn't exist on macos and windows: |
|
I removed the packaging module import and chose to use this method of comparison instead: Hopefully that's robust enough not to break. |
|
Wasn't robust enough. I think this will be. |
There was a problem hiding this comment.
@ezyang has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
|
This looks like it was sufficient. Unfortunately it looks like we need to merge with master. |
There was a problem hiding this comment.
@ezyang is landing this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
|
@ezyang, do you know what caused Facebook Internal to fail? |
|
it's fake, I think |
Summary: Fixes #42406 ### cusparse Xcsrmm2 API: (#37202) - new: https://docs.nvidia.com/cuda/cusparse/index.html#cusparse-generic-function-spmm - old (deprecated in cuda 11): https://docs.nvidia.com/cuda/archive/10.2/cusparse/index.html#csrmm2 Before: |cuda ver | windows | linux | |--|--|--| | 10.1 | old api | old api | | 10.2 | old api | new api | | 11 | old api (build error claimed in #42406) | new api | After: |cuda ver | windows | linux | |--|--|--| | 10.1 | old api | old api | | 10.2 | old api | **old api** | | 11 | **new api** | new api | ### cusparse bmm-sparse-dense API <details><summary>reverted, will be revisited in the future</summary> (cc kurtamohler #33430) - new: https://docs.nvidia.com/cuda/cusparse/index.html#cusparse-generic-function-spmm Before: |cuda ver | windows | linux | |--|--|--| | 10.1 | not supported | new api | | 10.2 | not supported | new api | | 11 | not supported | new api | After: |cuda ver | windows | linux | |--|--|--| | 10.1 | not supported | new api | | 10.2 | not supported | new api | | 11 | **new api** | new api | </details> Pull Request resolved: #42412 Reviewed By: agolynski Differential Revision: D22892032 Pulled By: ezyang fbshipit-source-id: cded614af970f0efdc79c74e18e1d9ea8a46d012
Add sparse-dense BMM operation for CUDA and CPU.
Closes #5672