eig_backward: faster and with complex support #52875
Conversation
💊 CI failures summary and remediationsAs of commit 0637e70 (more details on the Dr. CI page):
ci.pytorch.org: 1 failedThis comment was automatically generated by Dr. CI (expand for details).Follow this link to opt-out of these comments for your Pull Requests.Please report bugs/suggestions to the (internal) Dr. CI Users group. |
2848273 to
9335685
Compare
Codecov Report
@@ Coverage Diff @@
## master #52875 +/- ##
==========================================
- Coverage 77.64% 77.64% -0.01%
==========================================
Files 1869 1869
Lines 182385 182406 +21
==========================================
+ Hits 141617 141630 +13
- Misses 40768 40776 +8 |
|
@IvanYashchuk, would you review this? |
Sure, will do! |
There was a problem hiding this comment.
This is great! I don't have any questions regarding math or implementation. I left a few suggestions for comments and tests.
Could you also post the runtime for the OpInfo checks? (--durations=0 option for pytest)
I suspect the gradgradcheck on cuda could be slow.
|
@IvanYashchuk , thank you for the review. The slowest one is the complex gradcheck with 9 secs, next comes for doubles with 3 secs. |
|
@anjali411 , @IvanYashchuk , thank you very much for your valuable comments. I have updated the PR accordingly. Please, have a look. |
There was a problem hiding this comment.
@anjali411 has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
|
@nikitaved could you benchmark the performance for different dtypes using |
|
@anjali411 , you want to benchmark |
Just the analytical gradient computation, so |
|
@anjali411 , all right, will do. Luckily, in this case the backward computation dominates over, say, |
| op=torch.eig, | ||
| dtypes=floating_and_complex_types(), | ||
| test_inplace_grad=False, | ||
| supports_tensor_out=False, |
There was a problem hiding this comment.
This will hit a logical merge conflict with #53259, which is landing soon. We should rebase this on top of it (where this metadata should no longer be needed).
|
@anjali411 , I did run the benchmarks, and the results are almost identical across all the dtypes, about 5.2 nanoseconds for matrices of sizes Test Scriptimport sys
import pickle
print('Using pytorch %s' % (torch.__version__))
torch.manual_seed(13)
shapes = [(1000, 1000), (2000, 2000), (4000, 4000)]
results = []
repeats = 10
device = 'cpu'
dtypes = [torch.double, torch.cdouble]
for device, dtype in itertools.product(['cpu', 'cuda'], dtypes):
print(f"{device}, {dtype}")
for mat1_shape in shapes:
eigvals = torch.rand(*mat1_shape[:-1], dtype=dtype, device=device)
eigvecs = torch.rand(*mat1_shape, dtype=dtype, device=device)
x = torch.linalg.solve(eigvecs, eigvecs * eigvals.unsqueeze(-2))
x.requires_grad_(True)
eigenvalues, eigenvectors = torch.eig(x, eigenvectors=True)
ones_matrix = torch.ones_like(x)
ones_vector = torch.ones_like(eigenvalues)
tasks = [(f"{torch.autograd.backward((eigenvalues, eigenvectors), (ones_vector, ones_matrix), retain_graph=True)}", "torch.eig backward")]
timers = [Timer(stmt=stmt, label=f"torch.eig.backward() input dtype:{dtype} device:{device}", sub_label=f"{(mat1_shape)}", description=desc, globals=globals()) for stmt, desc in tasks]
for i, timer in enumerate(timers * repeats):
results.append(
timer.blocked_autorange()
)
print(f"\r{i + 1} / {len(timers) * repeats}", end="")
sys.stdout.flush()
del eigvals, eigvecs, eigenvalues, eigenvectors, ones_matrix, ones_vector
with open('eig_backward.pkl', 'wb') as f:
pickle.dump(results, f)ResultsEDIT: upon further investigation it looks like the script is broken, as timings do not change with the size. Scriptfrom IPython import get_ipython
import torch
import itertools
torch.manual_seed(13)
torch.set_num_threads(1)
ipython = get_ipython()
cpu = torch.device('cpu')
cuda = torch.device('cuda')
def generate_input(shape, dtype=torch.double, device=cpu):
eigvals = torch.rand(*shape[:-1], dtype=dtype, device=device)
eigvecs = torch.rand(*shape, dtype=dtype, device=device)
input = (eigvecs * eigvals.unsqueeze(-2)) @ eigvecs.inverse()
input.requires_grad_(True)
return input
def run_test(size, device, dtype):
print(f"size: {size}, device: {device}, dtype: {dtype}")
x = generate_input((size, size), dtype=dtype, device=device)
eigvals, eigvecs = torch.eig(x, eigenvectors=True)
onesvals = torch.ones_like(eigvals)
onesvecs = torch.ones_like(eigvecs)
command = "torch.autograd.backward((eigvals, eigvecs), (onesvals, onesvecs), retain_graph=True)"
if device == cuda:
command = command + "; torch.cuda.synchronize()"
ipython.magic(f"timeit {command}")
print()
dtypes = [torch.double]
devices = [cpu, cuda]
sizes = [10, 100, 1000]
for device, dtype, size in itertools.product(devices, dtypes, sizes):
run_test(size, device, dtype)This PRPrevious versionEDIT2: @robieta , if you have time, could you please have a look at the initial benchmarking script with TImer. The timings shown seem to be almost the same independently on the matrix size, which is weird. I suspect it is rather a mistake on my side... |
| // narrow extracts the column corresponding to the imaginary part | ||
| is_imag_eigvals_zero = at::allclose(D.narrow(-1, 1, 1), zeros); | ||
| } | ||
| // path for torch.linalg.eig with always a complex tensor of eigenvalues | ||
| else { | ||
| is_imag_eigvals_zero = at::allclose(at::imag(D), zeros); | ||
| // insert an additional dimension to be compatible with torch.eig. |
There was a problem hiding this comment.
@anjali411 , @mruberry , @IvanYashchuk , something to think about at some point in the future. Default proximity parameters for allclose are quite conservative for CUDA tensors of type torch.float, we could think about relaxing them.
There was a problem hiding this comment.
Similar to what Numpy is doing for some methods when it comes to proximity to zero, we could set epsilon for the imaginary part based on both dtype and the input size.
| eigvals, eigvecs = eigpair | ||
| if dtype.is_complex: | ||
| # eig produces eigenvectors which are normalized to 1 norm. | ||
| # Note that if v is an eigenvector, so is v * e^{i \phi}, |
There was a problem hiding this comment.
If v is an eigenvector, so is alpha * v, where alpha is a scalar, the underlying scalar field is Complex numbers, so we are good.
There was a problem hiding this comment.
LGTM. Just needs a minor change as #53259 has been merged. thank you @nikitaved
43a4c89 to
0637e70
Compare
|
@anjali411 merged this pull request in 8f15a2f. |
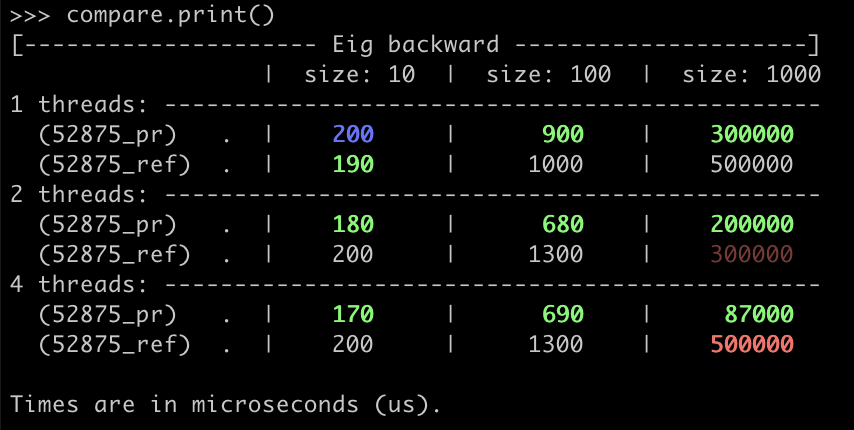
I think you meant By the way, I wrote a variant (https://gist.github.com/robieta/16b91831721cb8be121f04ed9c917375), and it matches the conclusion that this PR is an improvement. So good job!
|
pytorch#52875 introduced this bug, as 'supports_tensor_out' has been phased out & replaced with 'supports_out'
Summary: As per title. Compared to the previous version, it is lighter on the usage of `at::solve` and `at::matmul` methods. Fixes pytorch#51621 Pull Request resolved: pytorch#52875 Reviewed By: mrshenli Differential Revision: D26768653 Pulled By: anjali411 fbshipit-source-id: aab141968d02587440128003203fed4b94c4c655
Summary: pytorch#52875 introduced this bug, as `supports_tensor_out` was replaced with `supports_out` in pytorch#53259, so CI checks are failing. Pull Request resolved: pytorch#53745 Reviewed By: gmagogsfm Differential Revision: D26958151 Pulled By: malfet fbshipit-source-id: 7cfe5d1c1a33f06cb8be94281ca98c635df76838
As per title. Compared to the previous version, it is lighter on the usage of
at::solveandat::matmulmethods.Fixes #51621