Create Jupyter notebook for clustering #330
Conversation
|
Thanks for your pull request. It looks like this may be your first contribution to a Google open source project (if not, look below for help). Before we can look at your pull request, you'll need to sign a Contributor License Agreement (CLA). 📝 Please visit https://cla.developers.google.com/ to sign. Once you've signed (or fixed any issues), please reply here with What to do if you already signed the CLAIndividual signers
Corporate signers
ℹ️ Googlers: Go here for more info. |
1 similar comment
|
Thanks for your pull request. It looks like this may be your first contribution to a Google open source project (if not, look below for help). Before we can look at your pull request, you'll need to sign a Contributor License Agreement (CLA). 📝 Please visit https://cla.developers.google.com/ to sign. Once you've signed (or fixed any issues), please reply here with What to do if you already signed the CLAIndividual signers
Corporate signers
ℹ️ Googlers: Go here for more info. |
|
Check out this pull request on You'll be able to see Jupyter notebook diff and discuss changes. Powered by ReviewNB. |
|
@googlebot I signed it!
|
|
CLAs look good, thanks! ℹ️ Googlers: Go here for more info. |
1 similar comment
|
CLAs look good, thanks! ℹ️ Googlers: Go here for more info. |
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_with_keras.ipynb
Outdated
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
| @@ -0,0 +1,536 @@ | |||
| { | |||
There was a problem hiding this comment.
There was a problem hiding this comment.
How should I improve it? The version I updated also has the name apply_clustering_to_dense.
There was a problem hiding this comment.
The new apply_clustering_to_dense name seems good to me!
There was a problem hiding this comment.
Sorry, I am confused. What was your thought on apply_clustering_to_first?
There was a problem hiding this comment.
I just didn't understand what "first" stood for in the name. Because it looked like it just applies clustering to the layer if it's in the list of layers to be clustered and leaves it otherwise. So I just didn't quite understand what the 'first' referred to.
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
tensorflow_model_optimization/g3doc/guide/clustering/clustering_example.ipynb
Show resolved
Hide resolved
|
@alanchiao @TamasArm @akarmi Nearly all of the review comments are addressed. There are at least two TODOs 1) find the version which I can "pip install" which includes the newly merged PRs; 2) change the way cluster_weights is imported after clustering APIs are exposed to the public. |
| @@ -0,0 +1,470 @@ | |||
| { | |||
There was a problem hiding this comment.
Nit: "tips" -> "use cases"
Not all of these are tips - some is just a "how to" and the emphasis is still on use cases (do they care about deployment (might not - they could just be doing some training experiments), do they want to checkpoint (might not for quick experiments), ... etc.
Reply via ReviewNB
| @@ -0,0 +1,470 @@ | |||
| { | |||
There was a problem hiding this comment.
"The optimal number of clusters per layer can be found via hyperparameter tuning."
Don't think this tip is useful since it seems like a given since all parameters are things to tune in ML.
The rest are bit more specific to compression specifically.
Reply via ReviewNB
| @@ -0,0 +1,686 @@ | |||
| { | |||
There was a problem hiding this comment.
determine if you should use it ->
determine if you should use it (including what's supported)
since some people may consider assume that already want to use weight clustering for its compression benefits but have forgotten
to first consider what's supported (e.g. custom Keras layers).
Reply via ReviewNB
| @@ -0,0 +1,686 @@ | |||
| { | |||
There was a problem hiding this comment.
Please see the pruning example with how it doesn't use tf.nn.softmax on the last layer directly and instead SparseCategoricalCrossEntropy with from_logits.
The reasoning is that it's not numerically stable to compute log (softmax(..)) directly, as described in places such as https://blog.feedly.com/tricks-of-the-trade-logsumexp/ . The log part is in the `sparse_categorical_crossentropy' loss, which operates on the softmax from tf.nn.softmax.
SparseCategoricalCrossEntropy(from_logits=True) can use the numerically stable code. In the current code with softmax and log in separate functions, it's hard for the framework to always use the numerically stable part (by fusing them and replacing them with a stable version).
Reply via ReviewNB
There was a problem hiding this comment.
Thanks! This is interesting.
By overcoming numerical instability, do you mean we need to stabilize the softmax function against underflow and overflow? If yes, I agree that we need to use the tensorflow implementation.
Side questions:
1) If we use SparseCategoricalCrossEntropy with from_logits=false combined with the last layer of the model as softmax, it will end up with this clipping in Keras, which generates a bound [1e-7, 1-1e-7] on the output probability. However, will this clipping work if the input values are NaNs already? It should be no? But if yes, is the bound keeping the output of log(softmax(...)) stable?
2) In general, what use cases will be suited for the Keras clipping?
There was a problem hiding this comment.
re 1): The probability calculation never generates nans. But it can saturate to 0.0 or 1.0, which will generate nans in the loss calculation, so clipping prevents the nans from being generated.
Also note that in graph mode keras can bypasses the softmax and executes the from_logits=True path, and so the results can be different depending on how you're using the model. That's bad.
re 2): None. It keeps beginners out of trouble, but for any serious application you shouldn't use it. Any example that hits the saturation gets a gradient of zero => is being ignored by the training procedure. For a small number of classes this will be all your worst classified examples (which would be an important signal). For a large number of classes this could be a significant fraction of your data.
If you want to export a model that outputs probabillities, add a softmax layer immediately before exporting.
There was a problem hiding this comment.
The probability calculation never generates nans
What is the probability here?
Nans can be generated after softmax function (when the denominator of the softmax becomes 0), which is the input for keras clipping afaik.
Also note that in graph mode keras can bypasses the softmax and executes the from_logits=True path,Did not know that. Will look for the code at some point. Thanks!
re 2):
Agreed. Thanks!
There was a problem hiding this comment.
What is the probability here?
The softmax output.
denominator of the softmax becomes 0
How do you make the denominator 0? it't the sum of exponentials. Sure some of those exponentials could underflow, but any good implementations subtracts the largest logit from all the logits (logits = logits - max(logits)) So it's impossible for everything to underflow.... unless all your logits are -inf? If you have infs or nans in your logits then you have a different problem.
Right?
There was a problem hiding this comment.
Thanks!
How do you make the denominator 0?
I was thinking in exp(x) when x is very very negative (not sure whether it has to be -inf), the exp(x) will underflow.
Sure some of those exponentials could underflow, but any good implementations subtracts the largest logit from all the logits
Yes, indeed. And I did not know all implementations already have this. Will check the details myself.
|
Left a few remaining comments. Looks good to me otherwise and we can merge this as an initial version. Added @MarkDaoust as a final reviewer. I'm adding the FYI @lamberta. |
|
I ran the e2e tutorial on TF 2.2 and saw the following error message. @arovir01. Please address.
|
|
Hi Both, I ran the e2e tutorial on TF 2.2 and saw the following error message. @arovir01. Please address. Did you use the dev package or the I tried it locally with the top commit in tfmot (939bed8) with this end-to-end example and it works. When I tried it in colab it fails because of the package installed at the beginning of the file. The reason is that the latest tfmot master will include the fix for the function strip_clustering(), while the tfmot released package does not have it afaik.
If we decide to use the latest tfmot dev package in this notebook, there is also the change for |
|
| Did you use the dev package or the
Ah I mistake - I ran it with the latest TFMOT release instead of more recent commit. Looks good to me then. |
tensorflow_model_optimization/g3doc/guide/clustering/clustering_comprehensive_guide.ipynb
Show resolved
Hide resolved
| @@ -0,0 +1,686 @@ | |||
| { | |||
There was a problem hiding this comment.
| @@ -0,0 +1,686 @@ | |||
| { | |||
There was a problem hiding this comment.
Reading the available docs it's not clear what's happening inside, so I'm really left guessing.
I assume:
- The clustering tools replace weights with a smaller weight-cluster array, and indices into that array (can't that be gzipped so show the size difference directly?)
strip_clusteringthen resets to the original style of direct-weight array, but using the clustered weights? Either I don't understand:- How this all works,
- Or why
strip_clusteringis necessary to show the size difference here.
So maybe it could use little more explanation.
Reply via ReviewNB
There was a problem hiding this comment.
Good point - I'll make the equivalent change on the pruning side.
I think something along the lines of "strip_clustering removes any tf.Variable that clustering only needs during training, which would otherwise add to model size during serving" would work. This avoids any references to implementation details (e.g. the wrapper)
| @@ -0,0 +1,686 @@ | |||
| { | |||
There was a problem hiding this comment.
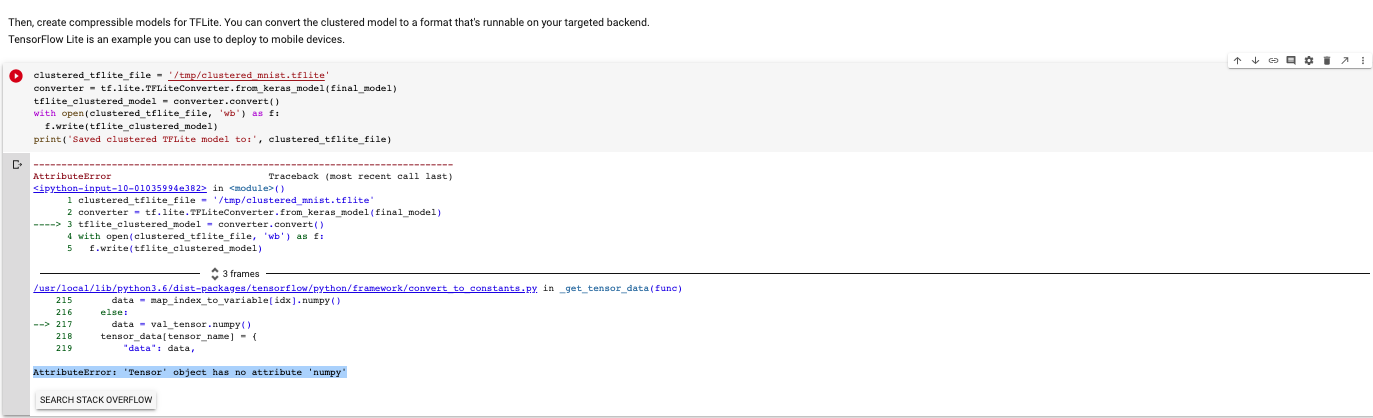
Here I'm getting an error in colab:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-20-01035994e382> in <module>()
1 clustered_tflite_file = '/tmp/clustered_mnist.tflite'
2 converter = tf.lite.TFLiteConverter.from_keras_model(final_model)
----> 3 tflite_clustered_model = converter.convert()
4 with open(clustered_tflite_file, 'wb') as f:
5 f.write(tflite_clustered_model)
3 frames
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/convert_to_constants.py in _get_tensor_data(func)
215 data = map_index_to_variable[idx].numpy()
216 else:
--> 217 data = val_tensor.numpy()
218 tensor_data[tensor_name] = {
219 "data": data,
AttributeError: 'Tensor' object has no attribute 'numpy'
Reply via ReviewNB
There was a problem hiding this comment.
@Ruomei: you can install the new package at
"pip install --index-url https://test.pypi.org/simple/ --extra-index-url https://pypi.org/simple tensorflow-model-optimization==0.4.0.dev2"
For testing.
|
Also, don't forget to add this to the _book.yaml, or it won't be correctly visible on the site. You could also add the overview at the same time. https://www.tensorflow.org/model_optimization/guide/clustering at the same time |
|
All done, thanks @alanchiao @MarkDaoust |
Thanks. @arovir01 was addressing this today afaik. |
Looks good to me Ruomei. Thanks! Once Mark finishes the review with you and you've squashed it, I'll merge it. |
19e9550 to
e616f48
Compare
@alanchiao @MarkDaoust Somehow I did not see this line. The commits are now squashed but it is fine. I can do it again if necessary. |
| @@ -0,0 +1,686 @@ | |||
| { | |||
There was a problem hiding this comment.
re 1): The probability calculation never generates nans. But it can saturate to 0.0 or 1.0, which will generate nans in the loss calculation, so clipping prevents the nans from being generated.
Also note that in graph mode keras can bypasses the softmax and executes the from_logits=True path, and so the results can be different depending on how you're using the model. That's bad.
re 2): None. It keeps beginners out of trouble, but for any serious application you shouldn't use it. Any example that hits the saturation gets a gradient of zero => is being ignored by the training procedure. For a small number of classes this will be all your worst classified examples (which would be an important signal). For a large number of classes this could be a significant fraction of your data.
If you want to export a model that outputs probabillities, add a softmax layer immediately before exporting.
This PR adds the Jupyter notebook for clustering.