Data science with AWS tutorial course creating by tubone.

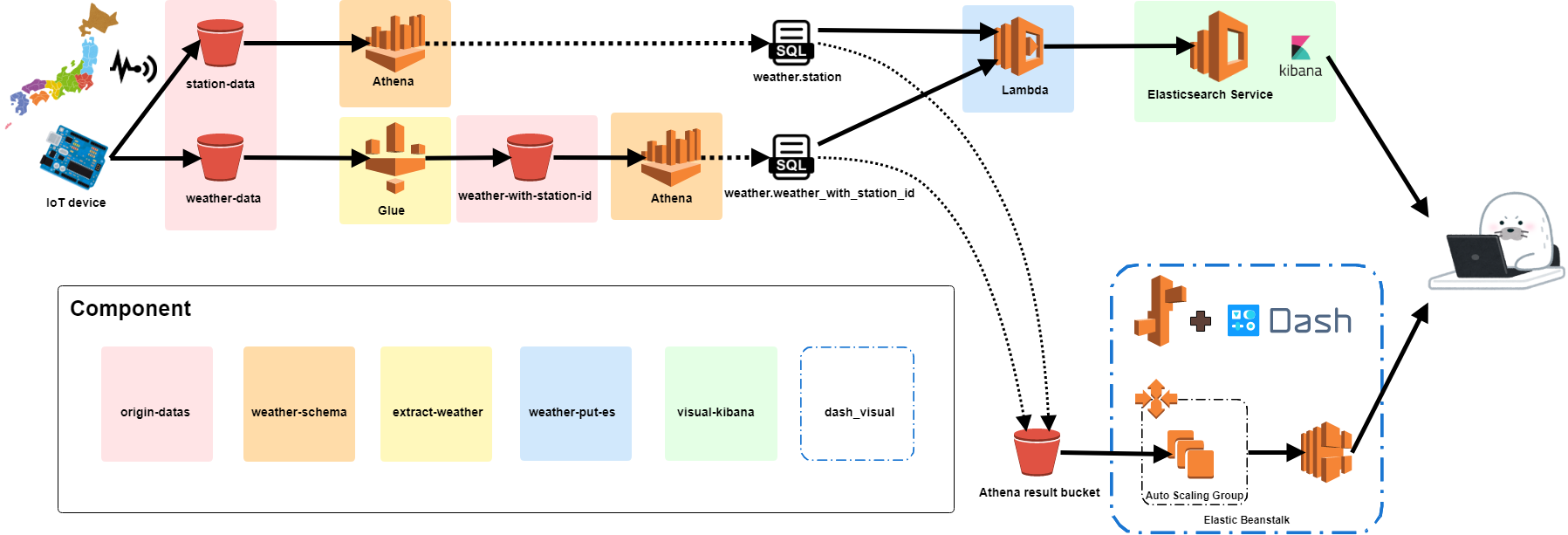
This tutorial course is handson you understanding ETL(Extract, Transform, Load) and creating those structure using AWS managed services.
If you are interested in Data science with AWS but being unskilled, Read the Text below
This tutorial will be used many managed services such as...
- S3
- Athena
- Glue
- Elastic Beanstalk
- Lambda
- Elasticsearch service(not implemented)
- Collect weather datas on weather stations in all locations in Japan. In the tutorial, you can download from kaggle using kaggle API.
- Put datas in origin buckets. Weather datas are put
weather-datas, station location datas arestation-datasprefix. - Crawl
weather-datasand ETL job because of addingstation_id. - Execute Athena queries because of creating several CSVs such as
stationandweather_with_station_id. - Put query results in the result bucket. Create Elastic Beanstalk and run
Dash. - Or put Elasticsearch using the Lambda function.
- Enjoy a
Dashplots or ElasticsearchKibana.
Weather Data for Recruit Restaurant Competition (https://www.kaggle.com/huntermcgushion/rrv-weather-data/discussion/46318)
Using two datas
- Weather
- weather data
- weather_stations.csv
- station data (include longitude latitude)
Run the command below. Using kaggle API.
make download-dataset
If you put S3 origin-datas buckets, run the command below.
make upload-weather-data
Install Terraform (0.11.0 or more)
brew install terraform
terraform --version
> Terraform v0.11.10
Or upgrade Terraform
brew upgrade terraform
terraform --version
> Terraform v0.11.10
pip install awsebcli
Install AWS CLI
brew install awscli
aws --version
> aws-cli/1.16.30
Or upgrade AWS CLI
brew upgrade awscli
aws --version
> aws-cli/1.16.30
Install Kaggle API
pip install kaggle
Install Elastic Beanstalk CLI
brew install awsebcli
make backend ENV=aws-training
make create-result-bucket ENV=aws-training
Depends on resources, The order by origin-datas => weather-schema => extract-weather => es-lib => weather-put-es
- origin-datas
- origin data buckets
- weather-schema
- Athena schema(station, weather)
- extract-weather
- glue crawler and job(create weather_with_station_id)
- es-lib
- Lambda layers for put datas into ElasticSearch
- weather-put-es
- Lambda which puts from Athena to Elasticsearch
Like below.
- remote-enable is terraform init process downloading terraform remote state(tfstate file).
- create-env is terraform init process create workspace.
- plan is terraform dry run.
- apply is that create AWS resource.
make remote-enable ENV=aws-training COMPONENT=weather-schema
make create-env ENV=aws-training COMPONENT=weather-schema
make plan ENV=aws-training COMPONENT=weather-schema
make apply ENV=aws-training COMPONENT=weather-schema
Next step, you create Athena Table using Saved query (named query).
Run 3 Saved query below with AWS admin console.
- create_station_table
- create_weather_table
- create_weather_with_station_id_table
Next, you run Glue clawler and job.
Run a clawler below with AWS admin console.
- weather-origin-clawler
Run a job below with AWS admin console.
- create_weather_csv
If you visual maps data, use Dash(https://plot.ly/products/dash/) and deploy Elastic Beanstalk.
After create Athena Table!
This program is used Mapbox and set an access token on application.py.
MAPBOX_ACCESS_TOKEN = "your token"
# FIXME: input your mapbox token
# https://docs.mapbox.com/help/how-mapbox-works/access-tokens/
Like below.
- execute-athena is execute athena query and download result csv.
- create-dashboard is create Elastic Beanstalk app
- deploy-dashboard is deploy dashboard if re-create dash codes.
make execute-athena
make create-dashboard
Visual interactive Japan map using EB and Dash.

Make Japanese tutorial using Jupyter and Gist.
Use seleniumbase.
cd dash_visual/tests/e2e
pip install -r requirements-test.txt
pytest e2e.py
Use CircleCI