This is a project still in early stages of development so, heavy changes should be expected !!!
Btw, read this if you want to use the software ;)
![]()
Take screenshots of various services and websites on an automated form
This is a project I am developing with various purposes.
- The first one is to get in touch with python. As for now I've only used it as a resource for small scripts as a bash substitute in most cases.
- The second one is to begin with a middle-sized project. It's been a while since I tried to start a project from beginning to end and this is feels like a right project to do it, not too complicated but with some time of development and a lot of learning put in it.
Probably there's more to it than what I've just wrote but, you get the idea right? :)
As this project is built upon Selenium using Google Chrome, Chromedriver and Google Chrome are a must that should be satisfied in order to be able to take advantage of this Software.
-
Install Google Chrome from your package manager or download it from here
- It's also possible to use Chromium instead of Google Chrome for those who desire it
-
Install Chromedriver 2.35 from your package manager o dowload it from here
Run the following to install required python dependecies
λ pip install -r requirements.txtThe configuration is present on config.json . Only the parameters that are written on it are customizable. (More options are coming :))
I'ts possible to pass another configuration through the command line with the -c or -config options.
{
"browser_settings":{
"avaliable_browsers":["Chrome","Firefox"],
"browser_to_use": "Firefox",
"horizontal_resolution": 1920,
"vertical_resolution": 1080,
"site_load_timeout":10
},
"driver_paths":{
"Chrome":"../resources/chromedriver.exe",
"Firefox":"../resources/geckodriver.exe"
},
"general_settings":{
"number_of_threads": 8
}
}λ python.exe .\capture.py -h
██╗
██████╗ ██╗ ██╗ ██████╗ ████████╗ ██████╗ ██████╗ ██████╗ █████╗ ████████╗
██╔══██╗██║ ██║██╔═══██╗╚══██╔══╝██╔═══██╗██╔════╝ ██╔══██╗██╔══██╗ ██╔═██╔═██╗
██████╔╝███████║██║ ██║ ██║ ██║ ██║██║ ███╗██████╔╝███████║ ██║ ██║ ██║
██╔═══╝ ██╔══██║██║ ██║ ██║ ██║ ██║██║ ██║██╔══██╗██╔══██║ ██║ ██║ ██║
██║ ██║ ██║╚██████╔╝ ██║ ╚██████╔╝╚██████╔╝██║ ██║██║ ██║ ╚████████╔╝
╚═╝ ╚═╝ ╚═╝ ╚═════╝ ╚═╝ ╚═════╝ ╚═════╝ ╚═╝ ╚═╝╚═╝ ╚═╝ ╚═██╔══╝
╚╝
By B0vh1
usage: capture.py [-h] [-config file] [-file [file]] [-path [path]]
[-target [target]] [-threads [threads]] [-verbose [verbose]]
optional arguments:
-h, --help show this help message and exit
-config file, -c File file to read configuration from
-file [file], -f [file] file to read IP/domains from
-path [path], -p [path] path to store all data (Optional)
-target [target], -t [target] target to scan (In case there's only one
-threads [threads], -th [threads] number of threads to use (only when reading from file)
-verbose [verbose], -v [verbose] shows verbose information, if a file is specified, outputs to itCurrently the tool supports two browsers Chrome and Firefox, both have it's advantages and disadvantages.
Firefox
Works right without any user interface but it's performance gets drastically penalized as Firefox uses 4 threads each time it launches so, if we were to launch 8 processes 32 will be created resulting in a heavy bottleneck on the CPU (It looks like creating a custom profile and loading it would allow to use only one thread, I'm currently looking into it)
Chrome
Currently the best option, It allows for the most performance friendly experience but it also has its downsides. If chrome is used in headless mode, any website with an invalid certificate would be captured as a white image, if it isn't in headless mode, then for each website an annoying browser appears each time it loads a site.
As it is the software is designed to run without the headless mode activated on chrome, if you want it then go to the screenshot_tool.py and uncomment the 42th line.
# self.options.add_argument('--headless')Best Experience
The best experience achievable right now is running the default version with chromium on linux. Installing Xvfb allows us to run a virtual desktop where the browser it's openned so in the real world no annoying pop-up browsers are created.
To run the software using xvfb just type in the terminal (after having it installed) the following
xvfb-run python capture.py ...
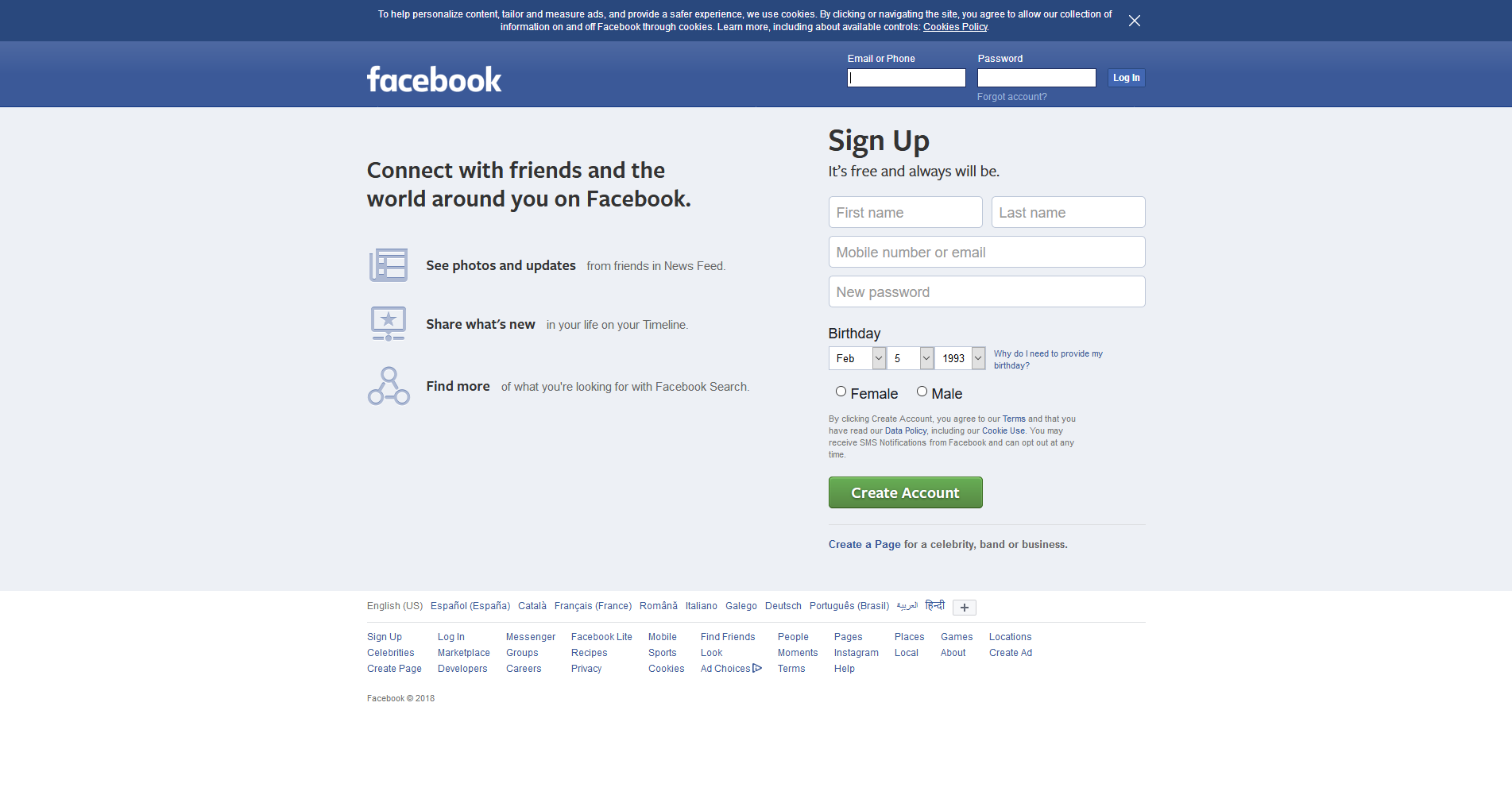
- Executing the following line
λ .\capture.py -p ../test/captures -t https://facebook.com- Will create a folder named
capturesunder the test directory
/photographi |
| /src
| capture.py
| capture_IP.py
| customip.py
| /test
| /captures
| https_facebook.com.png
| url_list.txt
| .gitignore
| LICENSE
| README.md
- And will save a screenshot like the following one with the naming scheme
PROTOCOL_ADDRESS_PORT.DOMAINEXTENSION.png
Functionalities to add to the tool
-
Configuration fileFile to specify default locations, default thread values, naming scheme...
-
Multiple protocol support
Add support for ftp (even with anonymous user) and other protocols supported by the browser
-
Ping test
Add an option to perform ping before trying to take a capture just to ensure the url/ip really exists and is avaliable
-
Download test
Add an option to perform a GET petition in order to check if the port in the url is open and if it is reachable
-
Verbose option
Add an option to show or don't verbose information
-
Exception handling
Improve exception handling with improved messages and avoid unnecessary ones
-
Improve performance
Modify how the threads behave and how the information is handled in order to reduce resources used by the tool