1. U: unlabeled pool
2. Q: select queries
3. S: human annotator
4. L: labeled training set
5. G: machine learning model
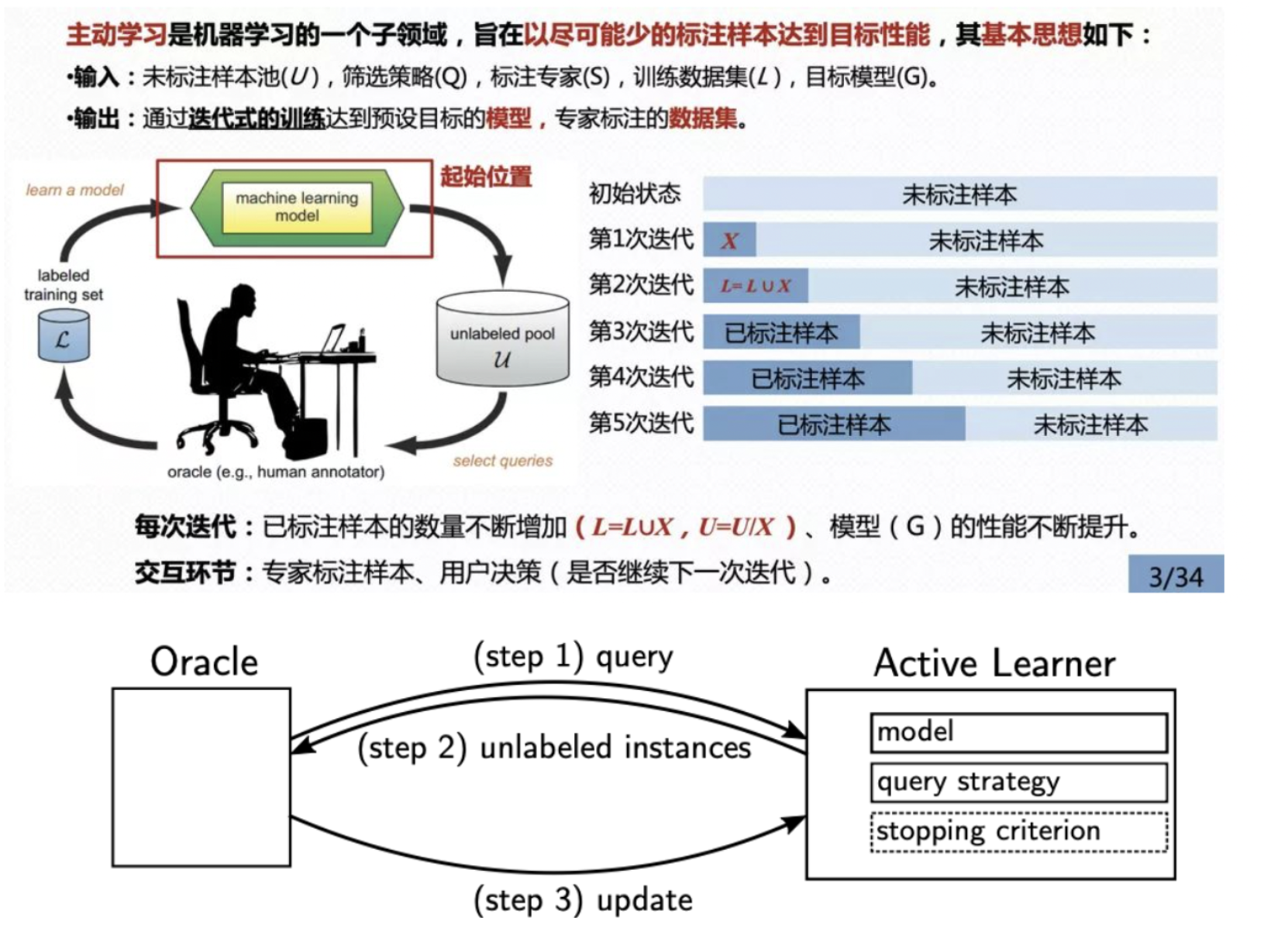
Referenced from https://coding-zuo.github.io/2022/02/21/%E4%B8%BB%E5%8A%A8%E5%AD%A6%E4%B9%A0Active-Learning-%E5%9F%BA%E7%A1%80/
Number of rows in training set: 25655
Number of rows in validation set: 5498
Number of rows in test set: 5498
Number of rows in training set: 490000
Number of rows in validation set: 105000
Number of rows in test set: 105000
Number of rows in training set: 4015
Number of rows in validation set: 860
Number of rows in test set: 861
Number of rows in training set: 4015
Number of rows in validation set: 860
Number of rows in test set: 861
Number of rows in training set: 8376
Number of rows in validation set: 1796
Number of rows in test set: 1795
Number of rows in training set: 32889
Number of rows in validation set: 7048
Number of rows in test set: 7048
Number of rows in training set: 88333
Number of rows in validation set: 18928
Number of rows in test set: 18929
Number of rows in training set: 13192
Number of rows in validation set: 2827
Number of rows in test set: 2827
Number of rows in training set: 36374
Number of rows in validation set: 7794
Number of rows in test set: 7795
Number of rows in training set: 7469
Number of rows in validation set: 1600
Number of rows in test set: 1601
1. Random: random pick unlabelled sampled
2. Max Entropy: pick samples with the largest margin
3. Least Confidence value
4. MC Dropout
1. CMBAL: Base
2. CMBAL Variant 1
3. CMBAL Variant 2
step1: creat experiment configutration parameters at config folder, e.g config/arxiv/arxiv_init_250_batch_50_freq_1000.json
step2: python main.py --strategy RANDOM --config config/arxiv/arxiv_init_250_batch_50_freq_1000.json