<---------- Currently Undergoing Major Refactoring ---------->
With the rise of artificial intelligience, there is question on how can we integrate AI into our design framework to automate the process to finding design opportunities for different products. This github page contains a suggested framework that was created by us.
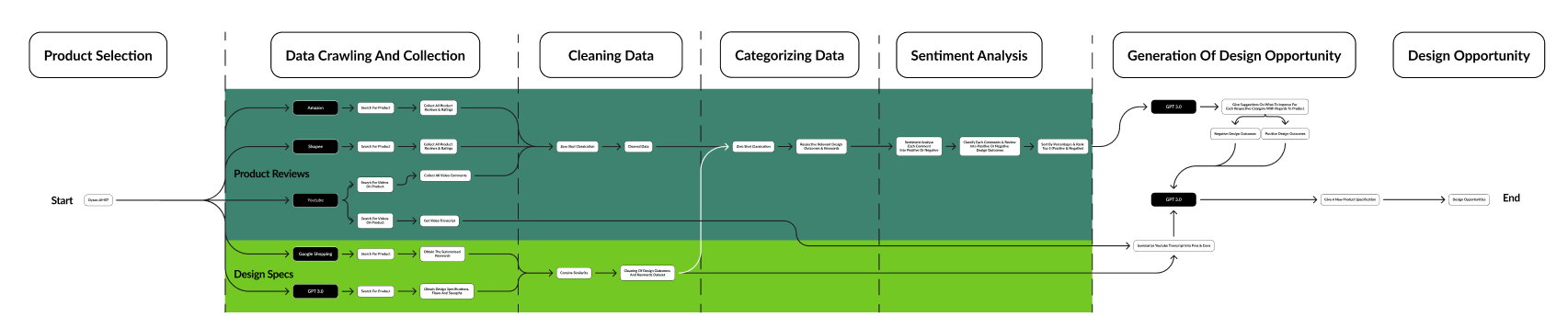
Credits to Billy for helping us visualise the framework. You can find more of Billy work here: https://awjiazhibilly.medium.com
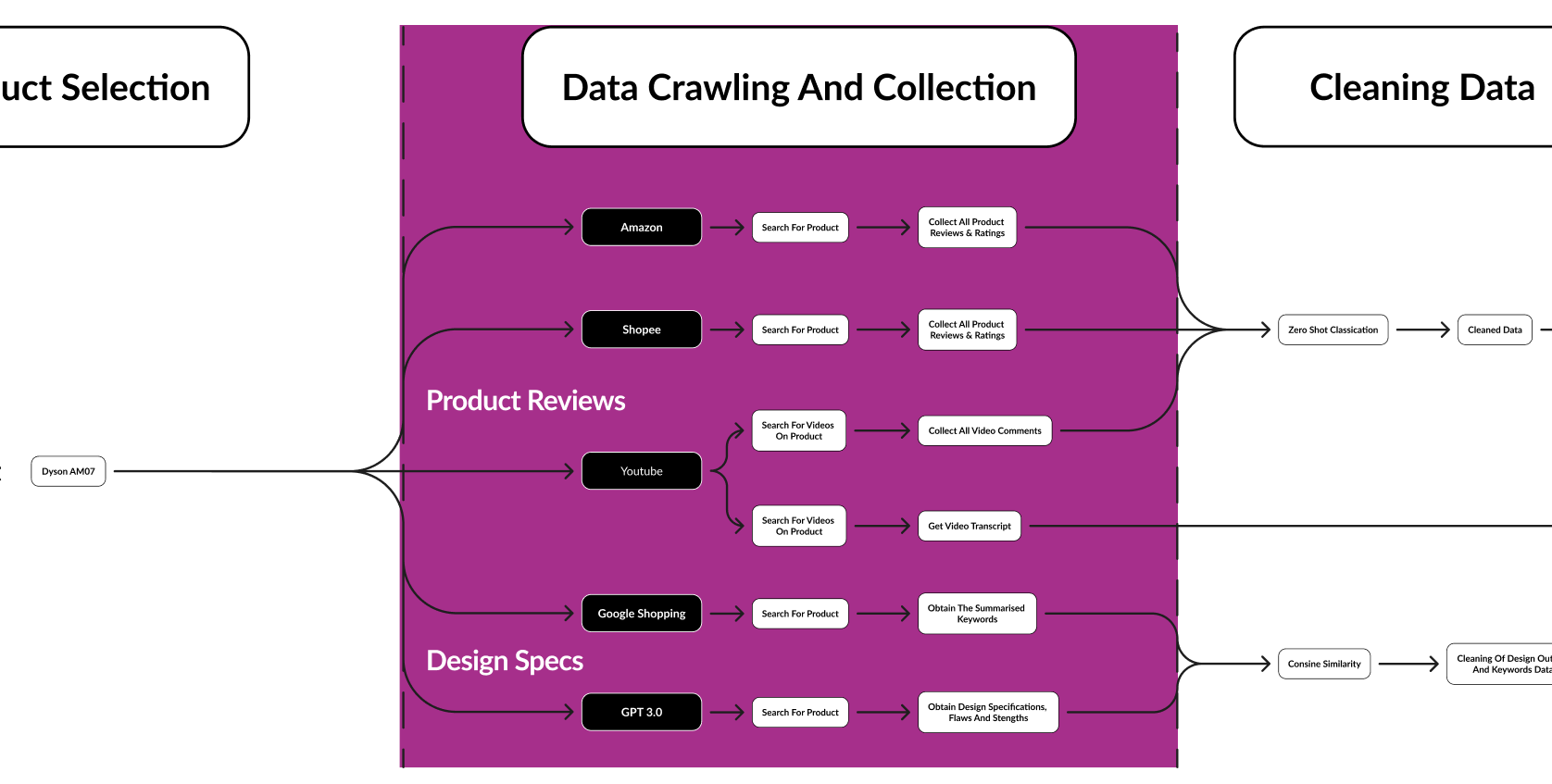
This section contains the collection of Data. There are 2 main data we will be collecting, reviews and opinons of the product from common e-commerce platforms like Amazon, Shopee as well as common content sharing platforms like Youtube.
NOTE: Webscrapping of Amazon is against their policy. This is done for educational purpose. Please contact Amazon to get access to their API for commercial uses.
Install the following libraries with pip:
pip install amazon_search_results_scraper
pip install beautifulsoup4
pip install selenium
pip install clean-text
pip install langdetect
pip install google-api-python-client
pip install youtube-transcript-api
pip install pandas
pip install numpy
This file contains several helper functions that were used in the project.
insearch_result: A function used to check if the title of the product contains all the words of the main search term.
For example, if the search term is ['dyson', 'am07'], all titles that will get choosen must have these 2 words in their titles.
save_data: A function used to save dataframes into csvs inside a folder under Data and followed by a combination of the search_terms
get_data: A function used to read csv files and converting them into a nested list
This folder contains a collection of scrapper functions used to collect data from various websites.
In order to use each function in a new python file, place Helper.py and the specific python file in the same directory as your python file and run the code in the codeblock provided.
Current functions:
get_amazon_reviews: A function that takes the search_terms and the count of number of links to be looked through. The function will return a dataframe with the product title, the link, the ratings and the respective reviews.
from Webscrapping.amazon_reviews import *
from Helper import *
#Parameters for functions
search_terms = ['pillow', 'case']
Universal_count = None (will automatically checks all links)
data = get_amazon_reviews(search_terms, None)
file_name = "YOUR DIRECTORY HERE"
save_data(data, file_name, search_terms)
get_all_shopee_reviews: A function that takes the search_terms and the count of number of links to be looked through. The function will return a dataframe with the link, the ratings and the respective reviews.
from Webscrapping.shopee_reviews import *
from Helper import *
#Parameters for functions
search_terms = ['pillow', 'case']
Universal_count = None (will automatically check all links)
data = get_all_shopee_reviews(search_terms, None)
file_name = "YOUR DIRECTORY HERE"
save_data(data, file_name, search_terms)
get_youtube_captions: A function that takes the search_terms, an api_key from ____________ and the count of number of videos to be scanned and returns a dataframe with all the captions of the respective youtube videos.
from Webscrapping.youtube_captions import *
from Helper import *
# Parameters for functions
search_terms = ['pillow', 'case']
youtube_api_key = INSERT_YOUR_KEY_HERE
Universal_count = 5
data = get_youtube_captions(search_terms, youtube_api_key, Universal_count)
file_name = "YOUR DIRECTORY HERE"
save_data(data, file_name, search_terms)
get_youtube_comments: A function that takes the search_terms, an api_key from ____________ and the count of number of videos to be scanned and returns a dataframe with the comments from those videos.
from Webscrapping.youtube_comments import *
from Helper import *
# Parameters for functions
search_terms = ['pillow', 'case']
youtube_api_key = INSERT_YOUR_KEY_HERE
Universal_count = 5
data = get_youtube_comments(search_terms, youtube_api_key, Universal_count)
file_name = "YOUR DIRECTORY HERE"
save_data(data, file_name, search_terms)
get_reddit_comments: A function that takes the search_terms, an api_key from reddit apps and the count of the number of posts to be scanned and returns a dataframe with the comments from those threads.
from Webscrapping.reddit_comments import *
from Helper import *
# Parameters for functions
search_terms = ['pillow', 'case']
number_of_posts = 5
reddit_api_key = INSERT_YOUR_KEY_HERE
reddit_secret =INSERT_YOUR_KEY_HERE
data = get_reddit_comments(search_terms, number_of_posts, reddit_api_key, reddit_secret)
file_name = "YOUR DIRECTORY HERE"
save_data(data, file_name, search_terms)
get_apple_insider_comments: A function that takes a list of articles and return a dataframe with the comments from the links provided.
from Webscrapping.apple_insider import *
from Helper import *
# Parameters for functions
list_of_articles = [INSERT_YOUR_ARTICLES_HERE]
data = get_apple_insider_comments(list_of_articles)
file_name = "YOUR DIRECTORY HERE"
save_data(data, file_name, search_terms)
get_hardware_zone_comments: A function that takes the number of pages to scan from the iphone chat room on the hardware zone and returns a dataframe with the comments from the various pages scanned.
from Webscrapping.hardware_zone import *
from Helper import *
# Parameters for functions
Universal_count = 5
data = get_hardware_zone_comments(Universal_count)
file_name = "YOUR DIRECTORY HERE"
save_data(data, file_name, search_terms)
Current functions:
get_googleshopping_reviews: A function that takes the search_terms and returns a dataframe of the keywords collected as well as a dictionary of keywords.
from Design_Opportunities.google_shopping import *
from Helper import *
# Parameters for functions
search_terms = ['pillow', 'case']
data = get_googleshopping_reviews(search_terms)
file_name = "YOUR DIRECTORY HERE"
save_data(data, file_name, search_terms)

This section will cover data cleaning. We will have to firstly clean the design opportunities by removing similar design opportunities. This will be done by using cosine similarity.
Once the design opportunities are cleaned, we also have to clean product reviews. Product reviews may often include irrelevant data such as comments about product shipping, quality of video made etc. These data does not value add to our design opportunities but may rather confuse our later models, thus they will have to be remove from our dataset. We will be using zero shot classification for this.
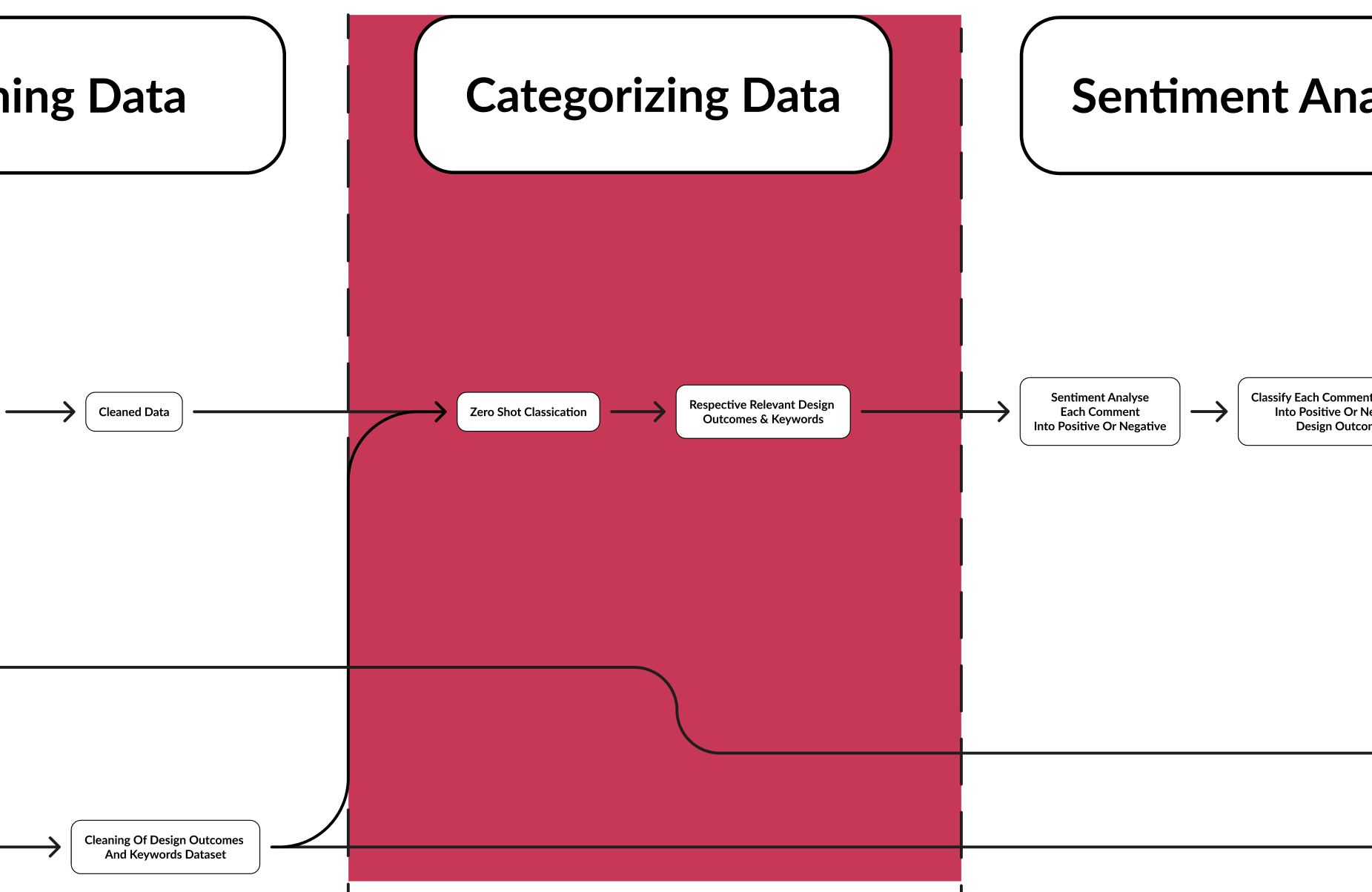
This section will cover data categorisation. We will be using zero shot classification, with our cleaned design opportunities as our labels.
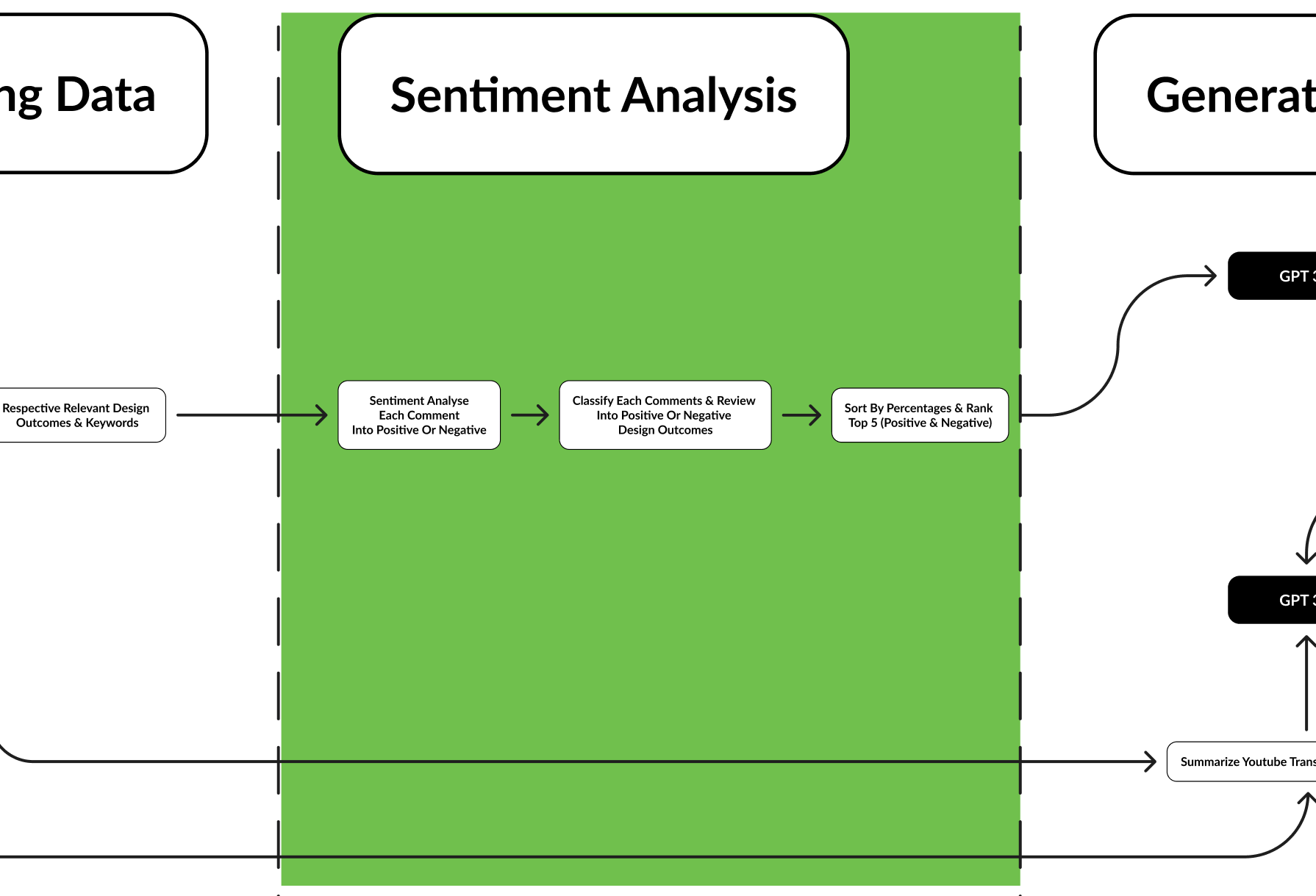
This section will cover sentiment analysis. We will be using Flair to classify if each review in their respective category is negative or positive. Afterwhich, the overall sentiment of each design opportunity to highlight which are areas of concerns that are of higher priority as they are a widespread issue.

This section will cover the creation of design opportunities. After ranking our design opportunities according to their priority levels, we summarised all the reviews with regards to the design opportunities and pass it through GPT-3 to come out with either suggestions or areas that should be maintained. Combining this with the summarised youtube reviews, we are able to come out with a list of new design opportunities for our product.