auto_tune_lr + StochasticWeightAveraging returns error #14755
Description
First check
- I'm sure this is a bug.
- I've added a descriptive title to this bug.
- I've provided clear instructions on how to reproduce the bug.
- I've added a code sample.
- I've provided any other important info that is required.
Bug description
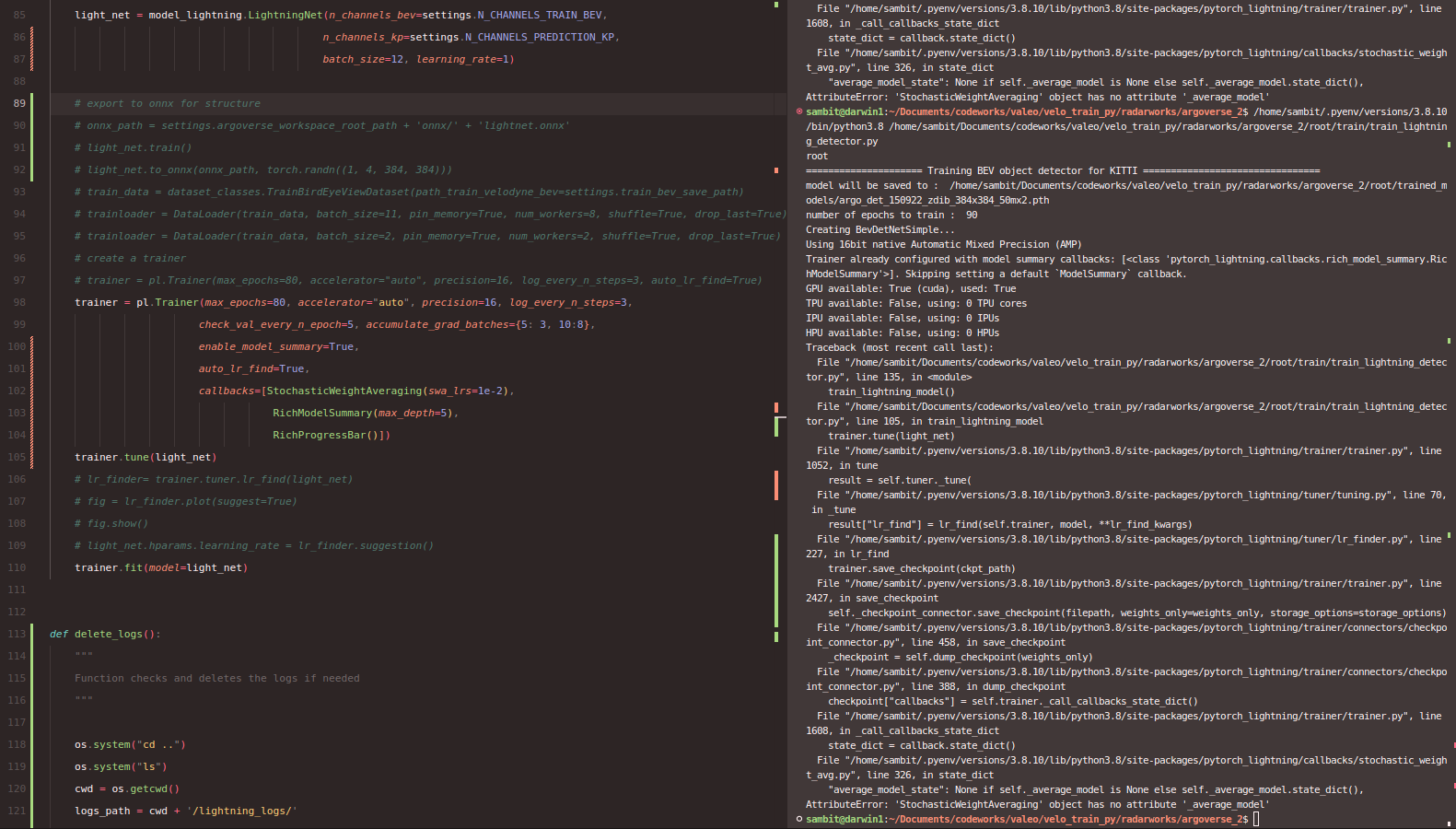
As seen above, when I try to use the auto_lr_tune feature together with SWA, I get this error (bottom right)
The same code works fine when I remove the auto_tune_lr flag.
How to reproduce the bug
class LightningNet(pl.LightningModule):
"""
Class defined a Lightning network
"""
def __init__(self, n_channels_bev, n_channels_kp, batch_size, learning_rate) -> None:
super().__init__()
self.learning_rate = learning_rate
self.batch_size = batch_size
N_CHANNELS_IN_HEADS = 128
self.network = BevDetNetSimple(in_channels=n_channels_bev, out_kp_channels=n_channels_kp, scale_H=2, scale_W=2, predict_3d_center=True)
self.loss_kp_focal = local_losses.FocalLoss(gamma=2)
self.loss_rot_focal = local_losses.FocalLoss(gamma=2)
self.loss_hwl = torch.nn.SmoothL1Loss(reduction='sum')
self.loss_dxdy = torch.nn.SmoothL1Loss(reduction='sum')
self.hparams["batch_size"] = self.batch_size
self.save_hyperparameters()
def forward(self, x):
"""
Passes input through the network
"""
xout_kp, xout_hwl, xout_rot, xout_xyz = self.network(x)
return xout_kp, xout_hwl, xout_rot, xout_xyz
def configure_optimizers(self):
optimizer = torch.optim.AdamW(self.parameters(), lr=(self.lr or self.learning_rate)) # define optimizer
return optimizer
def train_dataloader(self):
"""
Configure your data loader here here
"""
train_set = dataset_classes.TrainBirdEyeViewDataset(path_train_velodyne_bev=argo_settings.train_bev_save_path)
train_loader = DataLoader(train_set, batch_size=self.batch_size, shuffle=True, num_workers=4, drop_last=True, pin_memory=True)
return train_loader
def val_dataloader(self):
val_set = dataset_classes.ValidateBirdEyeViewDataset(path_train_velodyne_bev=argo_settings.val_bev_save_path)
val_loader = DataLoader(val_set, batch_size=8)
return val_loader
def log_train_bev_anno(self, bev_train, kp_y):
"""
Function logs BEV with key points annotated on it
"""
bev = bev_train.clone().cpu().numpy()[0][:, :, 0:3]
kp_y = kp_y.clone().cpu().numpy()[0]
r, c = np.where(kp_y == 1)
bev[r, c, 0] = 1
# writer = self.experiment
# writer.add_image("bev_anno", bev)
self.log("train_x_kp", bev)
# new in lightning - defined training lofic
def training_step(self, batch, batch_idx):
"""
Define the training logic here
batch_idx: provides
NOTE: Lightning docs say we don't need to do .cuda()
"""
train_x_bev, train_y_kp, train_y_hwl, train_y_rot, train_y_dxdy = batch
# self.log_train_bev_anno(train_x_bev, train_y_kp) # send one sample for logging
train_x_bev = train_x_bev.permute(0, 3, 1, 2) # BCHW
train_y_hwl = train_y_hwl.permute(0, 3 ,1, 2)
train_y_dxdy = train_y_dxdy.permute(0, 3, 1, 2)
y_hat, y_hat_hwl, y_hat_roty, y_hat_dxdy = self.network(train_x_bev)
loss_kp = self.loss_kp_focal(y_hat, train_y_kp)
loss_hwl = self.loss_hwl(y_hat_hwl, train_y_hwl)
loss_rot = self.loss_rot_focal(y_hat_roty, train_y_rot)
loss_dxdy = self.loss_dxdy(y_hat_dxdy, train_y_dxdy)
total_loss = 0.97 * loss_kp + 0.9 * loss_hwl + 0.92 * loss_rot + 0.85 * loss_dxdy
self.log("train_loss", total_loss)
return total_loss
def validation_step(self, batch, batch_idx):
val_x_bev, val_y_kp, val_y_hwl, val_y_rot, val_y_dxdy = batch
val_x_bev = val_x_bev.permute(0, 3, 1, 2) # BCHW
val_y_hwl = val_y_hwl.permute(0, 3 ,1, 2)
val_y_dxdy = val_y_dxdy.permute(0, 3, 1, 2)
y_hat, y_hat_hwl, y_hat_roty, y_hat_dxdy = self.network(val_x_bev)
loss_kp = self.loss_kp_focal(y_hat, val_y_kp)
loss_hwl = self.loss_hwl(y_hat_hwl, val_y_hwl)
loss_rot = self.loss_rot_focal(y_hat_roty, val_y_rot)
loss_dxdy = self.loss_dxdy(y_hat_dxdy, val_y_dxdy)
total_loss_val = 0.97 * loss_kp + 0.9 * loss_hwl + 0.92 * loss_rot + 0.85 * loss_dxdy
self.log("val_loss", total_loss_val)
return total_loss_val
def on_epoch_start(self):
"""
Callback invoked at start of epoch
"""
print("Starting epoch --> ", self.current_epoch)
self.epoch_timer_start = timeit.default_timer()
model_save_path = argo_settings.MODEL_SAVE_PATH_INTERIM + str(self.current_epoch) + '.pth'
print("Saving --> ", model_save_path)
torch.save(self.state_dict(), model_save_path)
return self.epoch_timer_start
def on_epoch_end(self):
"""
Callback invoked after every epoch
"""
print("Finished epoch number --> ", self.current_epoch)
self.epoch_timer_stop = timeit.default_timer()
self.epoch_time_s = (self.epoch_timer_stop - self.epoch_timer_start)
self.log("epoch_time_s", self.epoch_time_s)
# also save weights every 10th epoch
if self.current_epoch % 10 == 0:
model_save_path = argo_settings.MODEL_SAVE_PATH_INTERIM + str(self.current_epoch) + '.pth'
print("Saving --> ", model_save_path)
return self.epoch_time_sError messages and logs
# Error messages and logs here please
File "/home/sambit/.pyenv/versions/3.8.10/lib/python3.8/site-packages/pytorch_lightning/callbacks/stochastic_weight_avg.py", line 326, in state_dict
"average_model_state": None if self._average_model is None else self._average_model.state_dict(),
AttributeError: 'StochasticWeightAveraging' object has no attribute '_average_model'
Important info
#- Lightning Component (e.g. Trainer, LightningModule, LightningApp, LightningWork, LightningFlow): Trainer
#- PyTorch Lightning Version (e.g., 1.5.0): 1.7.6
#- Lightning App Version (e.g., 0.5.2):
#- PyTorch Version (e.g., 1.10): 1.12 + CU11.3
#- Python version (e.g., 3.9): 3.8.10
#- OS (e.g., Linux): Linux
#- CUDA/cuDNN version: CUDA11.3
#- GPU models and configuration: RTX3090
#- How you installed Lightning(`conda`, `pip`, source): pip
#- Running environment of LightningApp (e.g. local, cloud): local
More info
No response