![]()
![]()
bpe-openai is a tiktoken-compatible tokenizer API backed by the Rust
bpe-openai crate. Pathlit maintains the Python wrapper, while the core
tokenizer implementation is developed by GitHub and published in the
rust-gems
project. Published wheels bundle the tokenizer data, so the package works
out of the box on Python 3.9 and newer.
pip install bpe-openaiInstalling from a source distribution requires a Rust toolchain:
pip install --no-binary bpe-openai bpe-openai==<version>import bpe_openai as bpe
enc = bpe.get_encoding("cl100k_base")
tokens = enc.encode("Smoke tests keep releases honest.")
print(tokens)
print(enc.decode(tokens))
# Model-aware helper
chat_enc = bpe.encoding_for_model("gpt-4o")| API / Feature | Status | Notes |
|---|---|---|
get_encoding, encoding_for_model |
✅ | Supports cl100k_base, o200k_base, voyage3_base, and related models |
Encoding.encode, Encoding.decode |
✅ | Rust backend ensures parity with tiktoken |
Encoding.encode_batch |
✅ | Matches tiktoken's batching behaviour |
| Custom special tokens | Not yet configurable at runtime | |
| Legacy GPT-2 / r50k / p50k encodings | Planned; current focus is on modern OpenAI models | |
Metrics hook (set_metrics_hook) |
✅ | Emits model, token count, latency, backend version |
Legend: ✅ fully supported ·
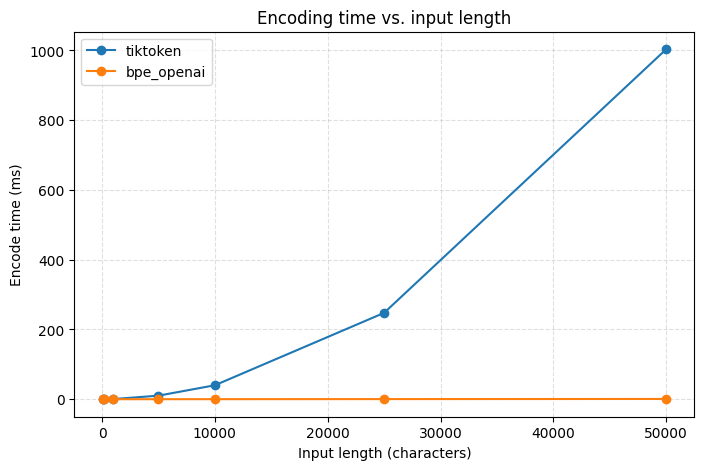
Long, repetitive prompts can hit pathological slow paths in tiktoken. To
stress-test both libraries we encoded inputs of the form "A" * n and measured
latency. bpe-openai stays effectively flat while tiktoken grows sharply with
input length, unlocking workloads like prompt templating and log chunking that
stalled with the reference implementation.
After installing from PyPI, run a quick confidence check:
python - <<'PY'
import bpe_openai as bpe
enc = bpe.get_encoding("cl100k_base")
text = "Smoke tests keep releases honest."
tokens = enc.encode(text)
assert enc.decode(tokens) == text
print("✅ bpe-openai smoke test passed.")
PYpython/– Python package wrapping the Rust tokenizer as a CPython extension.rust/– Rust crate that loads tokenizer specs and exposes the fast BPE APIs.scripts/– Helper utilities for benchmarking, parity checks, and data sync.vendor/– Vendored tokenizer definitions sourced from GitHub's upstream release.
python -m venv .venv
source .venv/bin/activate
python scripts/sync_tokenizer_data.py # ensures tokenizer assets are copied
pip install maturin
cd python
maturin develop --release
pytestThe repository includes scripts/sync_tokenizer_data.py to copy the vendored
.tiktoken.gz files into python/bpe_openai/data/ before building wheels or an
sdist.
- Update the version string in
python/pyproject.toml. The runtime fallback reads the same file, so one change keeps packaging metadata andbpe_openai.__version__in sync. - Run
python scripts/sync_tokenizer_data.pyto refresh bundled assets. - Commit the changes and tag the release (
git tag vX.Y.Z). - Push the tag. The
Release WheelsGitHub Actions workflow builds wheels, publishes a GitHub release, and uploads to PyPI via Trusted Publishing.
Contributions are warmly welcomed—whether you are filing a bug, improving parity with new OpenAI models, or squeezing out more performance. Open an issue or pull request and the Pathlit team will review quickly.