Math KDTree
A kd-tree is a data structure to store multidimensional points in such a way, that it is easy and fast to repeatedly find nearest neighbours.
For further explanations see http://en.wikipedia.org/wiki/Kd-tree.
For loading this package you can use the ConfigurationOfSciSmalltalk :
Gofer new smalltalkhubUser: 'SergeStinckwich' project:'SciSmalltalk';
package:'ConfigurationOfSciSmalltalk'; load.
"this loads Math-KDTree and the tests:"
(ConfigurationOfSciSmalltalk project version:#stable)
load:'Math-Tests-KDTree'.
"and if you want to make the code more efficient,
this can eventually help (it did help me):"
(ConfigurationOfSciSmalltalk project version:#stable)
load:'Math-Benchmarks-KDTree'.You construct a kdtree using #withAll:
kd:=KDTree withAll: aCollectionOfVectors.where a Vector can be any collection of numbers that understands #at:
You can then find the nearest neighbours of anotherVector in aCollectionOfVectors with #nnSearch:i:
kd nnSearch: anotherVector i: numberOfNearestNeighbours.that is essentially everything that is to say about its use. the IndexedKDTree returns the indices of the nearest neighbours (in aCollectionOfVectors) instead of the nearest neighbours itself. and if more than one neighbour is searched, it additionally returns the squared distances between the vector and its neighbours, iow for each nearest neighbour it returns an Array #(index squaredDistance).
Let me make a simple application just as an example how it can be used (attention: i do use some code here, that uses the package Math-DHB-Numerical, but one could do the same without that of course, i think its only the Float random expression).
"let's say we have some simple 1-dimensional data"
sine:= (1 to: 50 by: 0.2)collect: [:i|i sin ].
"let's blur that a little bit"
dirtysine :=sine collect: [:i|i +Float random-0.5].
"now suppose we want to clean up the mess by partititioning that mess and then
averaging the most similar partitions.
ok, first we calc the partition"
partitionLength:=30.
partition := (1 to: (dirtysine size+1 -partitionLength))collect:
[:i|( dirtysine copyFrom: i to:( i+partitionLength-1)) ].
"then we make a kdtree so that it does not take too long
to find the most similar parts"
tree:=KDTree withAll: partition.
"say we want to average 30 partitions"
numberOfNeighbours :=30.
"then we go through all partitions, find its neighbours
and calc the average for each of them"
averagedPartition :=(1 to: partition size)collect: [:i| |neighbours|
neighbours :=(tree nnSearch: (partition at: i) i: numberOfNeighbours)
reduce: [ :a :b | a + b ].
neighbours / numberOfNeighbours].
"what we have now with 'averagedPartition' is an averaged version of
'partition' . we can now reconstruct a somewhat smoother version of the
original mess by undoing the partition thing, iow reversing the calculation
of the partition we did in the first part"
reconstruction :=Array new:(sine size).
(1 to: sine size)do:[:i| |n sum|
n:=0.
sum:=0.
1 to: averagedPartition first size do:[:k|
(i between: k and: (averagedPartition size+k-1)) ifTrue:
[n:=n+1.sum:=sum+((averagedPartition at:(i+1-k))at:k)] ].
reconstruction at:i put: (sum/n)].
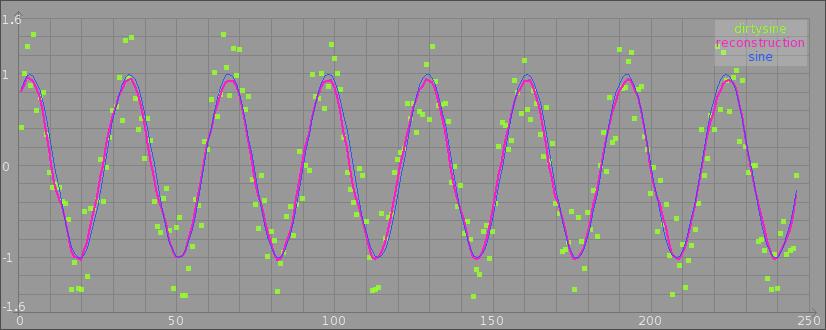
"ok, lets calc the errors"
((sine - dirtysine) squared sum / sine size)sqrt . " 0.2901228130544897"
((sine - reconstruction) squared sum / sine size)sqrt . " 0.07493816828762763"
"well, it seems the code did its thing"The result of this calculation looks like this:
Now for some speed comparisons - the speed obviously depends on which kind of collection one uses to store the vectors. the benchmarks use data consisting of 2000 vectors and search 20 times for the 10 nearest neighbours of different vectors:
KDTreeBenchmark run:5 with: FloatArray .
" Report for: KDTreeBenchmark
Benchmark SearchTree4Dim
SearchTree4Dim total: iterations=5 runtime: 15.2ms +/-4.1
Benchmark BuildTree1Dim
BuildTree1Dim total: iterations=5 runtime: 82.40ms +/-0.81
Benchmark BuildTree4Dim
BuildTree4Dim total: iterations=5 runtime: 106.40ms +/-0.81
Benchmark BuildAndSearchStupidNN1Dim
BuildAndSearchStupidNN1Dim total: iterations=5 runtime: 192.0ms +/-1.3
Benchmark SearchTree1Dim
SearchTree1Dim total: iterations=5 runtime: 2.80ms +/-0.99
Benchmark BuildAndSearchStupidNN4Dim
BuildAndSearchStupidNN4Dim total: iterations=5 runtime: 212.0ms +/-4.2"
KDTreeBenchmark run:5 with: Array .
" Report for: KDTreeBenchmark
Benchmark SearchTree4Dim
SearchTree4Dim total: iterations=5 runtime: 18.8ms +/-3.7
Benchmark BuildTree1Dim
BuildTree1Dim total: iterations=5 runtime: 41.60ms +/-0.81
Benchmark BuildTree4Dim
BuildTree4Dim total: iterations=5 runtime: 50.8ms +/-4.7
Benchmark BuildAndSearchStupidNN1Dim
BuildAndSearchStupidNN1Dim total: iterations=5 runtime: 230.0ms +/-1.8
Benchmark SearchTree1Dim
SearchTree1Dim total: iterations=5 runtime: 2.80ms +/-0.99
Benchmark BuildAndSearchStupidNN4Dim
BuildAndSearchStupidNN4Dim total: iterations=5 runtime: 322.4ms +/-4.1"one can see that FloatArrays are fastest for searching (because of their use of primitives in some timeconsuming calculation) but the difference to the other collections are not that great anymore with the latest changes in the code. but the build time is longest. Arrays generally work quite nicely.