This repository contains my solution approach from the FreeCodeCamp Machine Learning with Python Project - SMS Text Classifier challenge. ( ⭐️ Star repo on GitHub — it helps! )

In this challenge, we will create a machine learning model that will classify SMS messages as either "ham" or "spam". A "ham" message is a normal message sent by a friend. A "spam" message is an advertisement or a message sent by a company..
We need to create a function called predict_message that takes a message string as an argument and returns a list. The first element in the list should be a number between zero and one that indicates the likeliness of "ham" (0) or "spam" (1). The second element in the list should be the word "ham" or "spam", depending on which is most likely.
For this challenge, you will use the SMS Spam Collection dataset. The dataset has already been grouped into train data and test data.
You can access the full project instructions and starter code on Google Colaboratory.
Create a copy of the notebook either in your own account or locally. Once you complete the project and it passes the test (included at that link), "HAVE FUN WHILE SOLVING IT". If you are submitting a Google Colaboratory link, make sure to turn on link sharing for "anyone with the link."
All code section are available directly and the detailed description of the data can be found in colab.
The project needs the following header files for the implementation:
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- import tensorflow as tf
- from tensorflow import keras
- import tensorflow_datasets as tfds
- from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
- import seaborn as sns
- from tensorflow.keras.preprocessing.text import Tokenizer
- from tensorflow.keras.preprocessing.sequence import pad_sequences
- from tensorflow.keras.callbacks import EarlyStopping
- from tensorflow.keras.models import Sequential
- from tensorflow.keras.layers import Embedding, GlobalAveragePooling1D, Dense, Dropout
To run the project, do the following steps:
- Dowload the repo.
- Install all the above mentioned libraries.
python3 fcc_sms_text_classification.py- Check if following output is present in the end.
You passed the challenge. Great job!
Spam Wordcloud

Ham Wordcloud
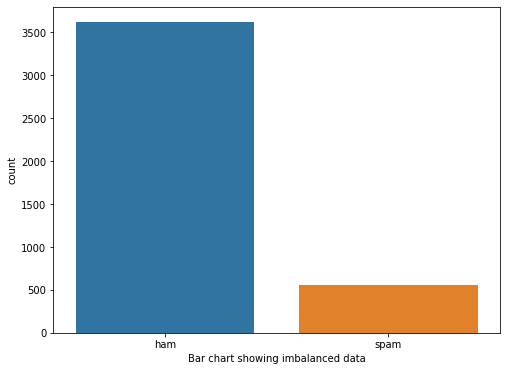

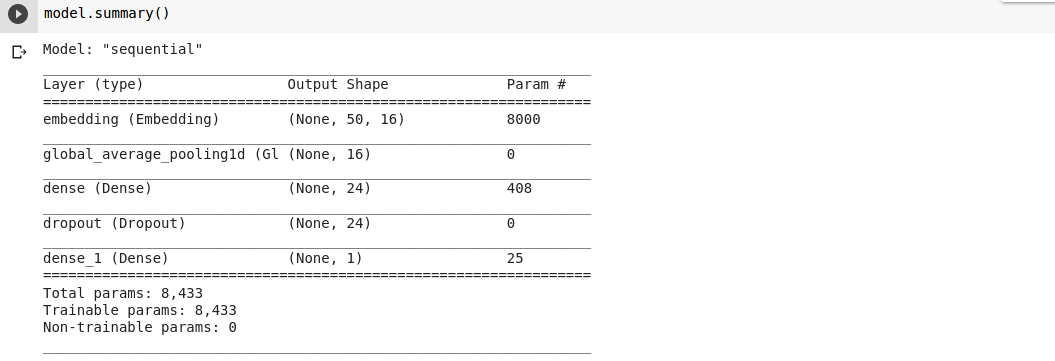
Model Summary
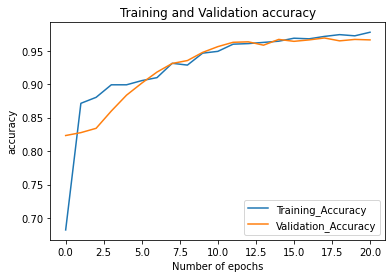
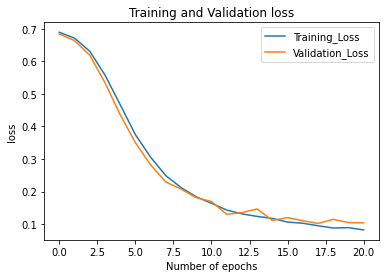
Train Dataset Accuracy:
loss: 0.0826 - accuracy: 0.9777
Test Dataset Accuracy:
loss: 0.1043 - accuracy: 0.9662
- Rohit Kumar Singh
Feel free to send us feedback on file an issue. Feature requests are always welcome. If you wish to contribute, please take a quick look at this colab.
Written with StackEdit.