[TOC]
| 姓名 | 学号 |
|---|---|
| 贺思嘉 | 181250044 |
- 包含使用开源项目https://github.com/lxyeah/findbugs-violations.git工具扫描得到的初始报告等
-
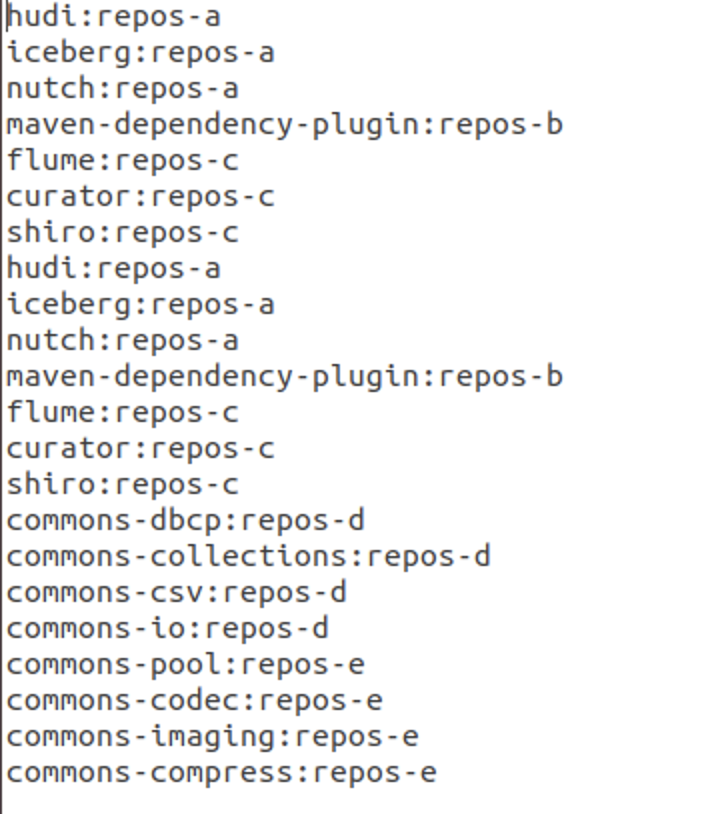
- 部分项目并没有得到扫描结果,受时间限制部分扫描出来的report没能进行tracking得到正误报,在压缩包里包含了所有扫描到的报告
- 最终扫描得到正误报的项目共4个:nutch, maven-dependency-plugin, commons-collections, commons-imaging
在实验中因为收集到正报和误报数量规模差距较大,共298条正报,14000余条误报,为了探究数据规模分布对学习结果的影响我们对不同标签的数据规模进行平衡处理,随机选取10%的误报数据与所有正报数据组成数据集,处理结果对应文件文件名包含balanced
-
clean_data
置信学习去噪处理的数据文件
-
data-phases-1
扫描得到的初始数据
-
fixed-label-dir
正报标记结果文件
-
unfixed-label-dir
误报标记结果文件
-
model_data
置信学习使用的数据文件
-
html
使用echarts实现实验结果对比可视化得到的文件
-
img
比较结果图表图片
警告标注工具代码及使用方式详情可见项目experimentData目录下readme文件
-
对机器扫描得到的全部正报数据进行人工标注,共标记数据298条
-
通过人工比对正报中监测到警告的commit和监测到警告修复的commit,结合标注标准进行标注
-
fixed-label-dir目录下文件,first为第一组人工标注,second为第二组人工标注
-
-
对机器扫描得到的误报数据进行抽样标注,共标记数据512条
-
通过人工比对正报中监测到警告的commit和前一次commit,结合标注标准进行标注
-
unfixed-label-dir目录下文件
-
sample-unfixed-label-dir目录下为所有抽样标注的文件
-
-
为了缓解人工标注过于主观的问题,我们组不同同学对数据共进行两轮标注
在论文"Confident Learning: Estimating Uncertainty in Dataset Labels"中提出置信学习是一种新兴的、具有原则性的框架,以识别标签错误、表征标签噪声并应用于带噪的学习。
一个完整的置信学习过程可以分为三个步骤:
-
Count:估计噪声标签和真实标签的联合分布
-
Clean:找出并过滤掉错误样本
-
Re-Training:过滤错误样本后,重新调整样本类别权重,重新训练
-
model_data目录下的文件
-
不对不同标签的数据规模进行平衡处理,直接输入所有的正报和误报,正报默认标签为“close”,误报默认标签为“open”,共14800余条数据
-
对不同标签的数据进行规模平衡处理,共1700余条数据
-
本实验尝试了sklearn中的三种分类模型:DecisionTreeClassifier,MultinomialNB,LogisticRegression
-
由于警告数据本身的特征,缺乏语义逻辑关系,我们认为不需要过于复杂的模型
- 数据去噪工具使用了开源项目cleanlab
-
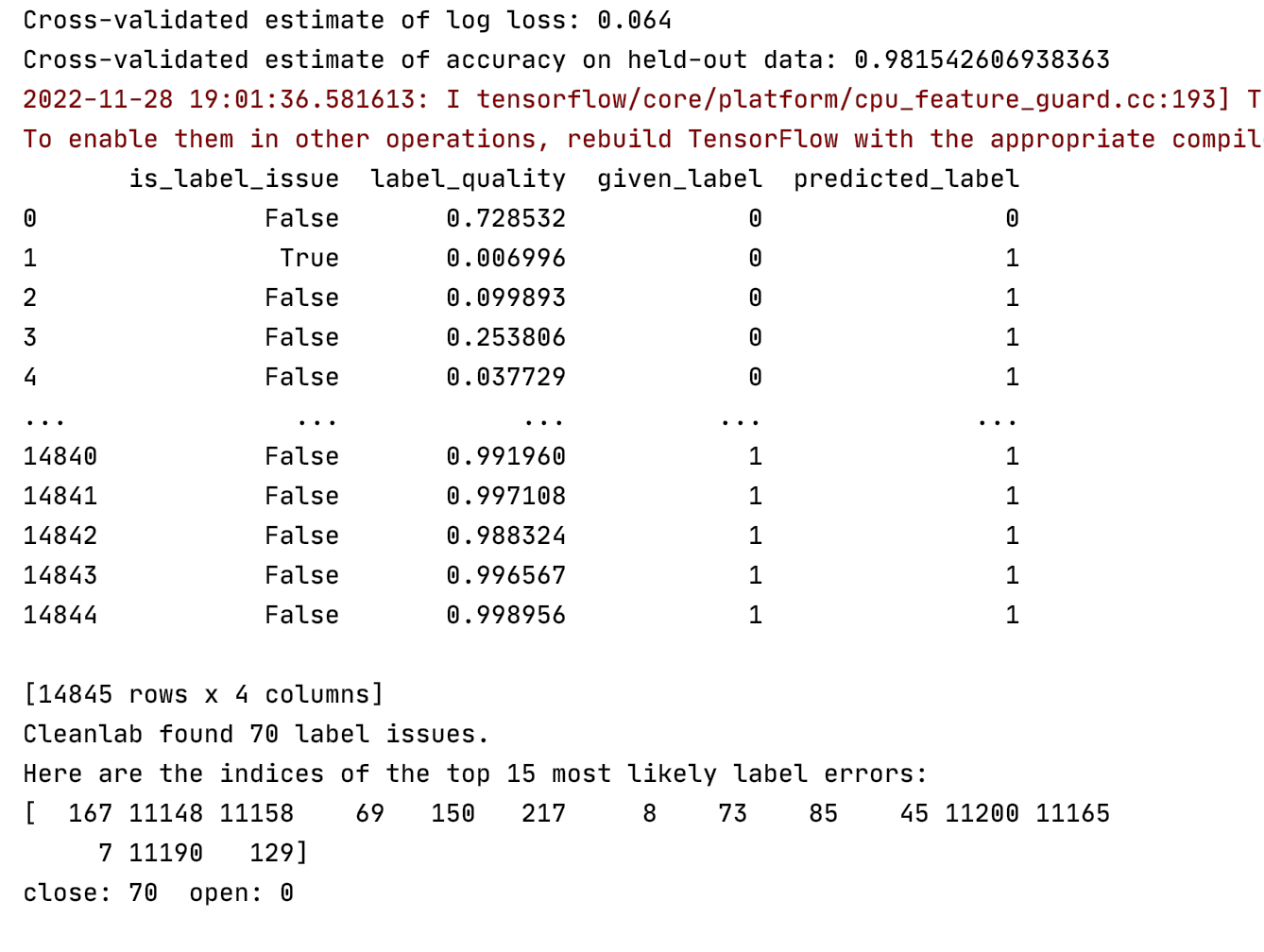
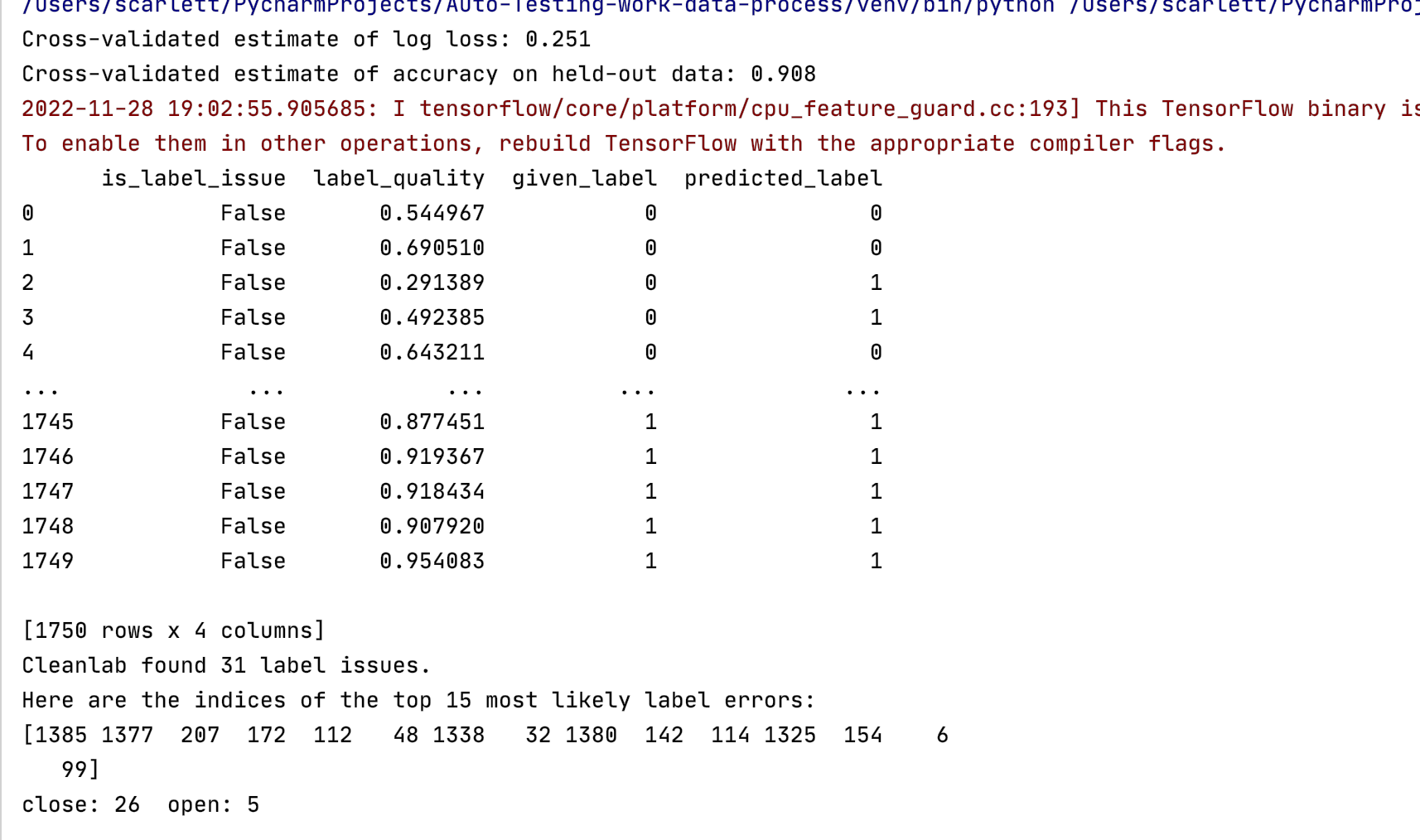
# 后续实验结果对比基于使用MultinomialNB得到的去噪结果 mnb_model = MultinomialNB() def model_clean(model): num_crossval_folds = 5 pred_probs = cross_val_predict(model, vec_warnings, labels, cv=num_crossval_folds, method="predict_proba") loss = log_loss(labels, pred_probs) # score to evaluate probabilistic predictions, lower values are better print(f"Cross-validated estimate of log loss: {loss:.3f}") predicted_labels = pred_probs.argmax(axis=1) # print(predicted_labels) acc = accuracy_score(labels, predicted_labels) print(f"Cross-validated estimate of accuracy on held-out data: {acc}") issues = CleanLearning(model).find_label_issues(vec_warnings, labels) print(issues) ranked_label_issues = find_label_issues(labels, pred_probs, return_indices_ranked_by="self_confidence") print(f"Cleanlab found {len(ranked_label_issues)} label issues.") print("Here are the indices of the top 15 most likely label errors:\n" f"{ranked_label_issues[:15]}") check_issues_labels(ranked_label_issues)
-
正报类型统计
-
误报类型统计
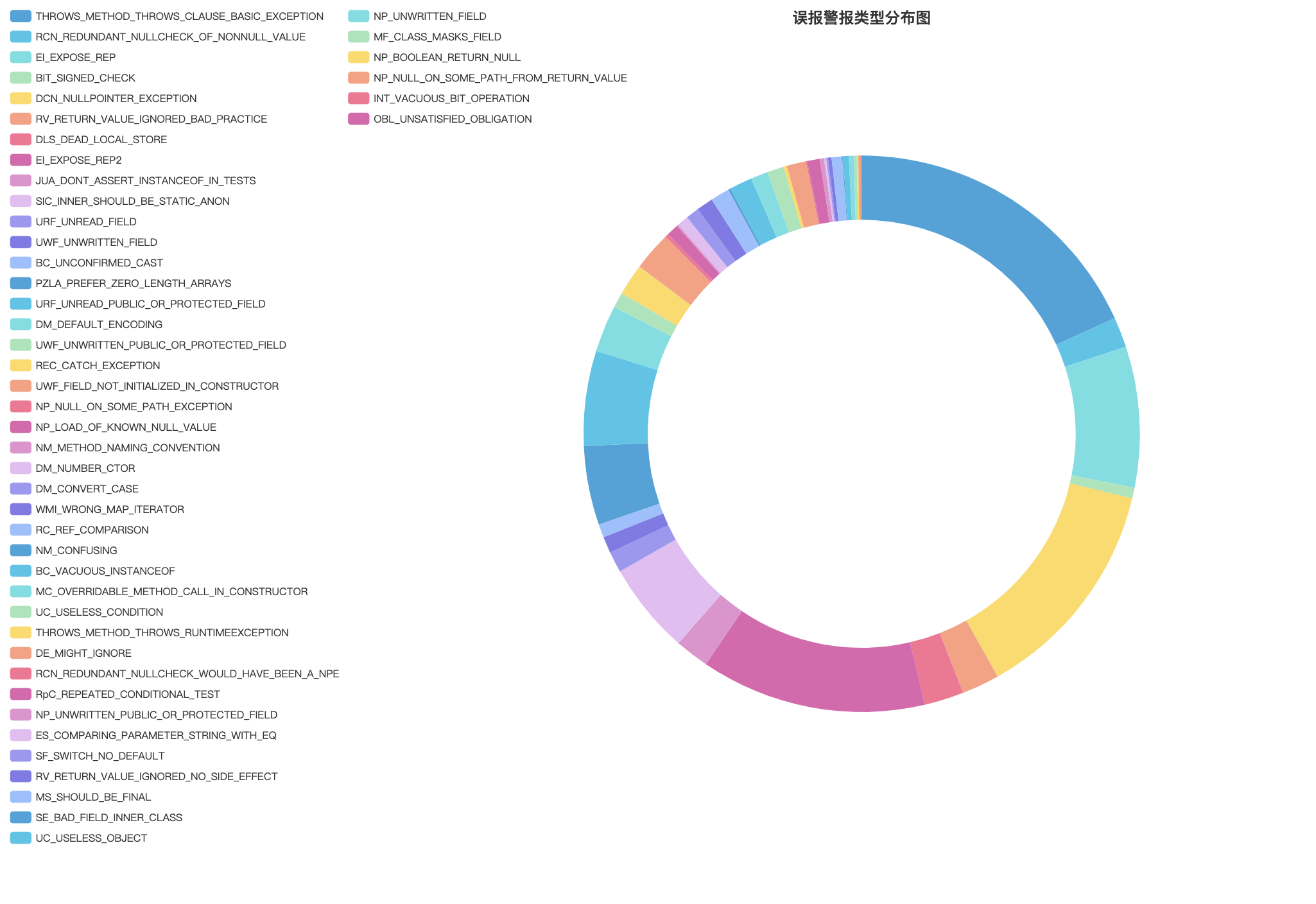
-
正报数据标注结果对比
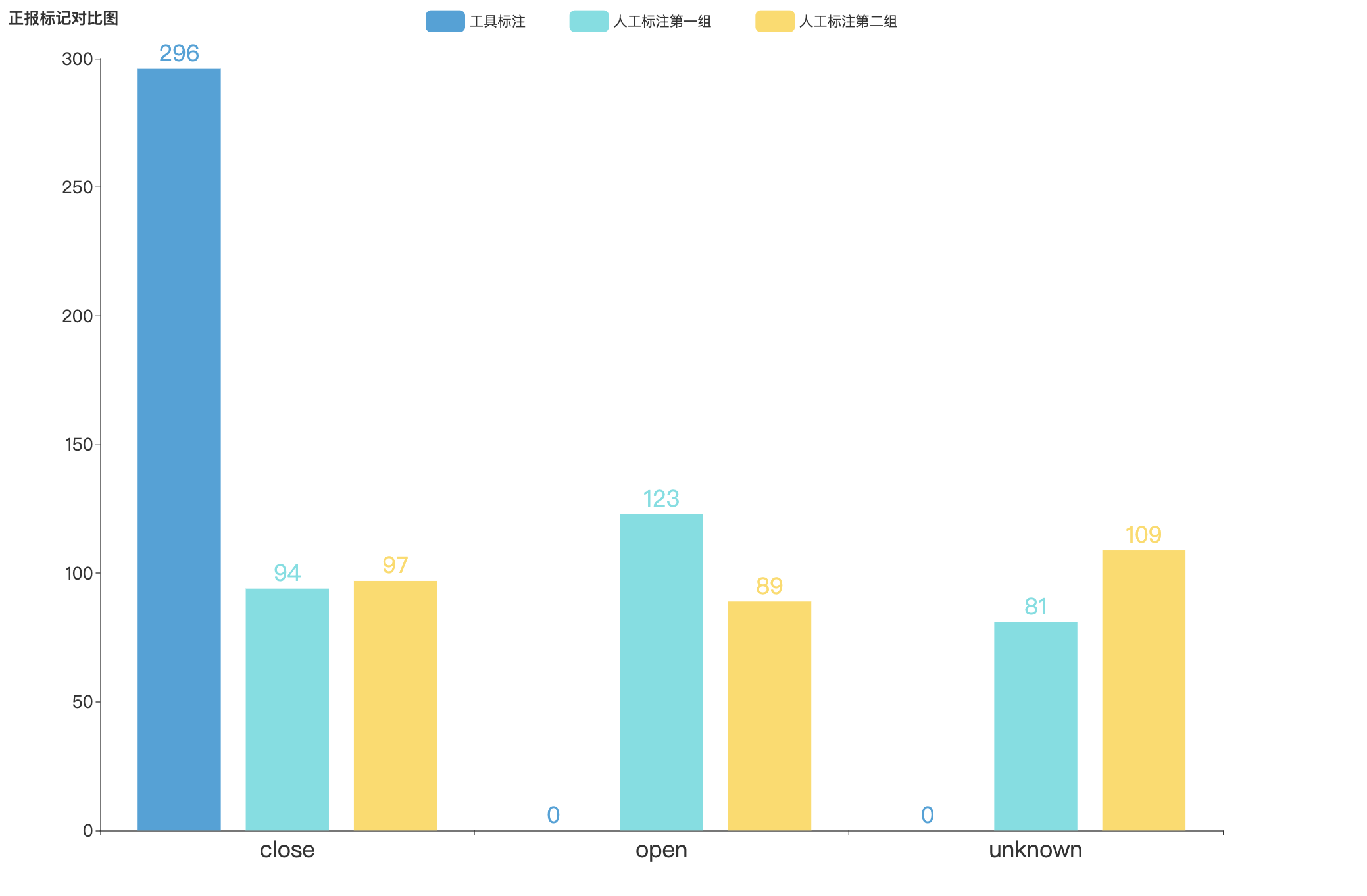
-
误报数据抽样标注结果对比
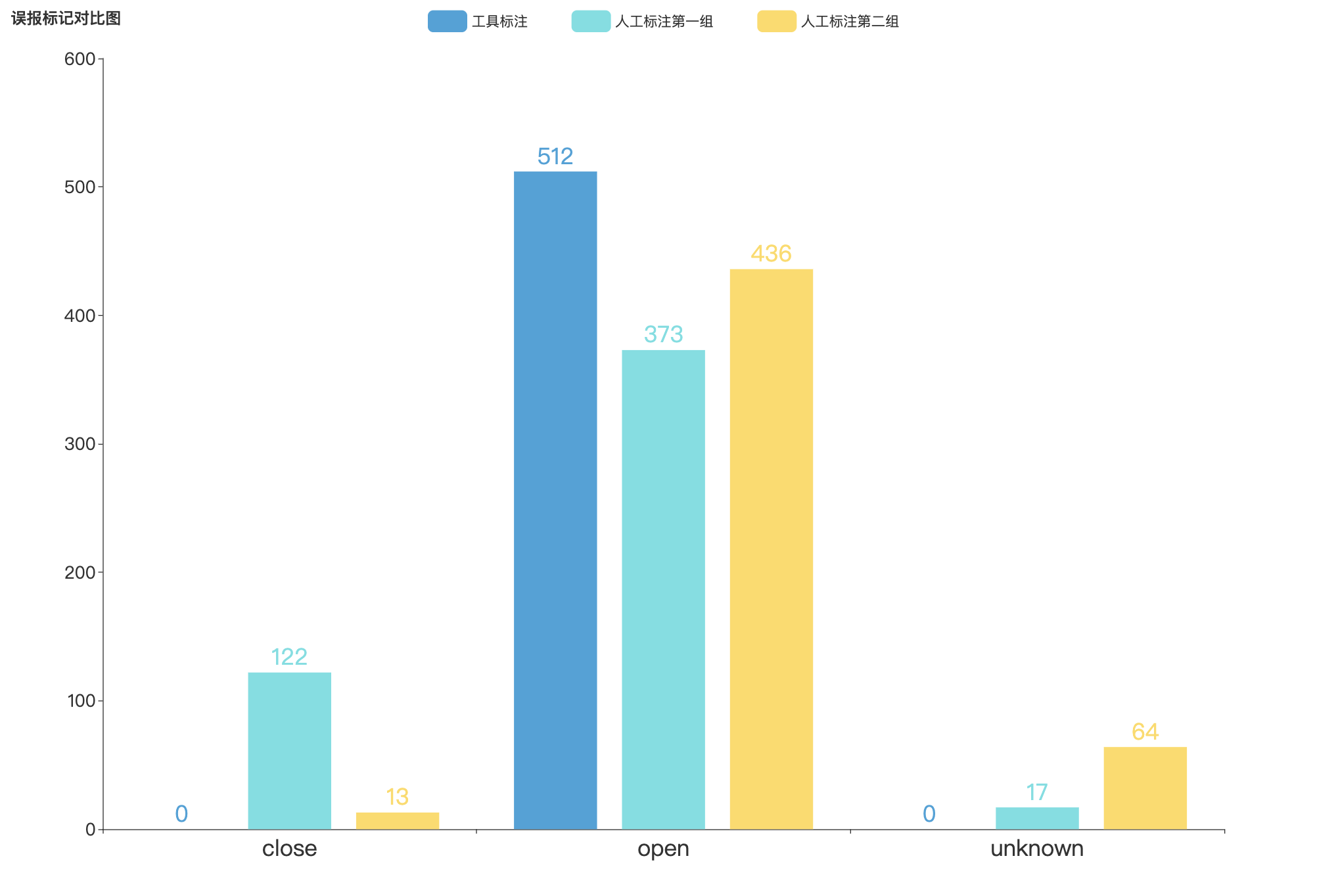
-
两次人工标注结果对比
-
正报标记结果
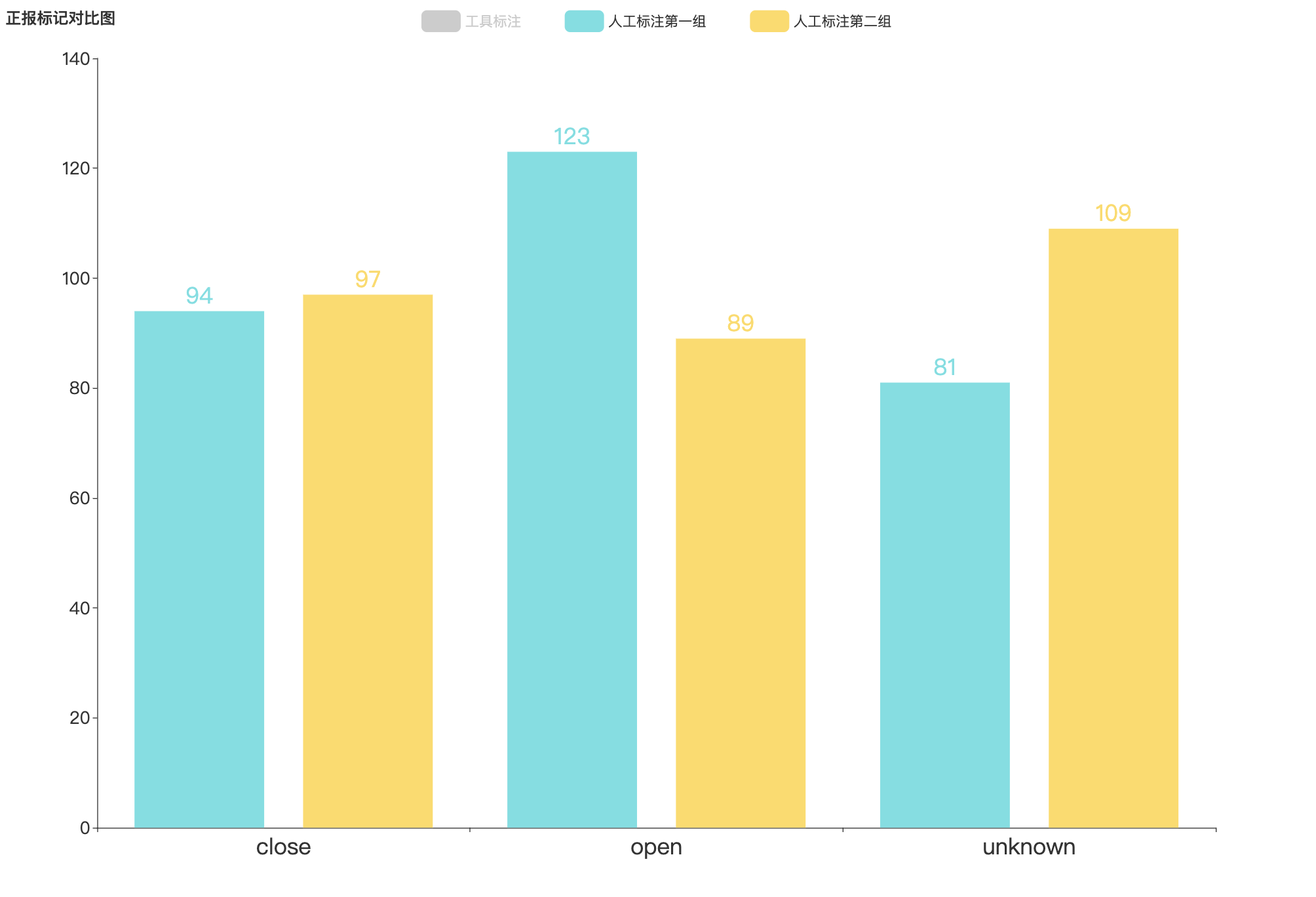
-
误报抽样标记结果
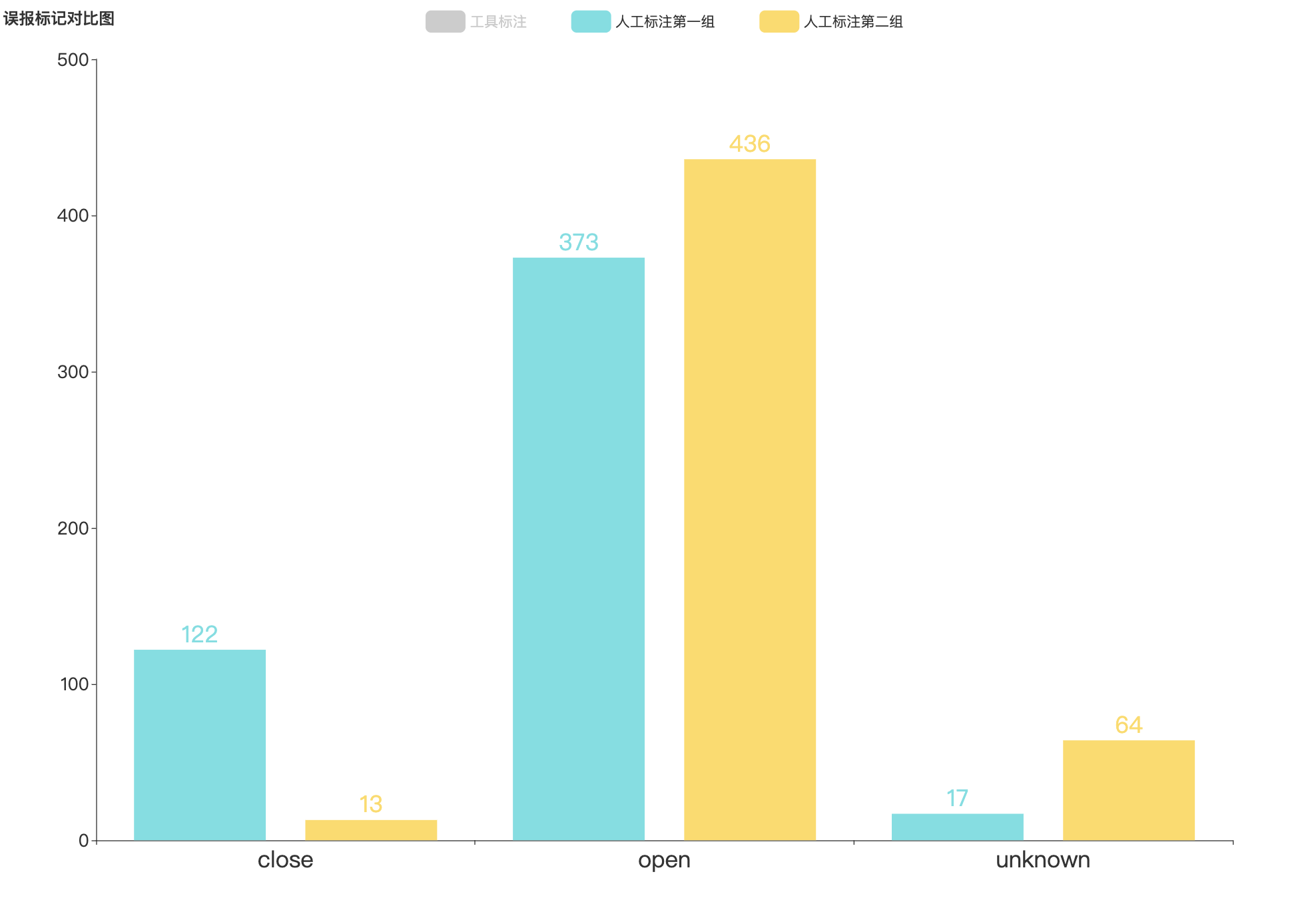
-
-
-
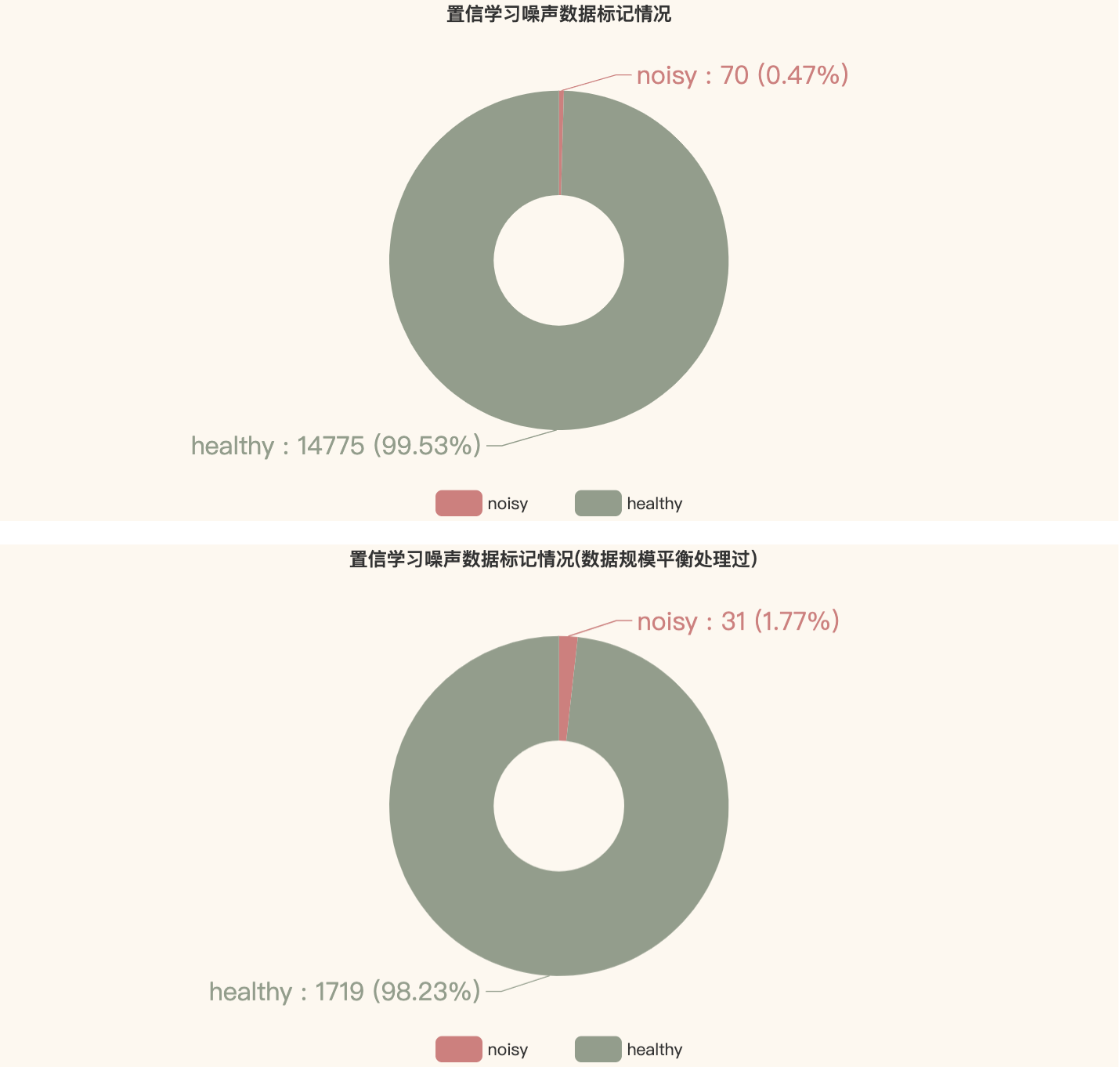
在未经平衡处理的原始数据中,噪声数据占比约0.47%,通过实验发现70条噪声数据标签均为close;在经过平衡处理的数据中(随机选取10%的误报数据与所有正报数据组成数据集),噪声数据占比约1.77%,共31条噪声数据,其中26条正报数据,5条误报数据
-
经过置信学习处理,可识别原始数据中有一定数量的噪声,去除这些噪声数据有助于实验结果出现更大差异。
-
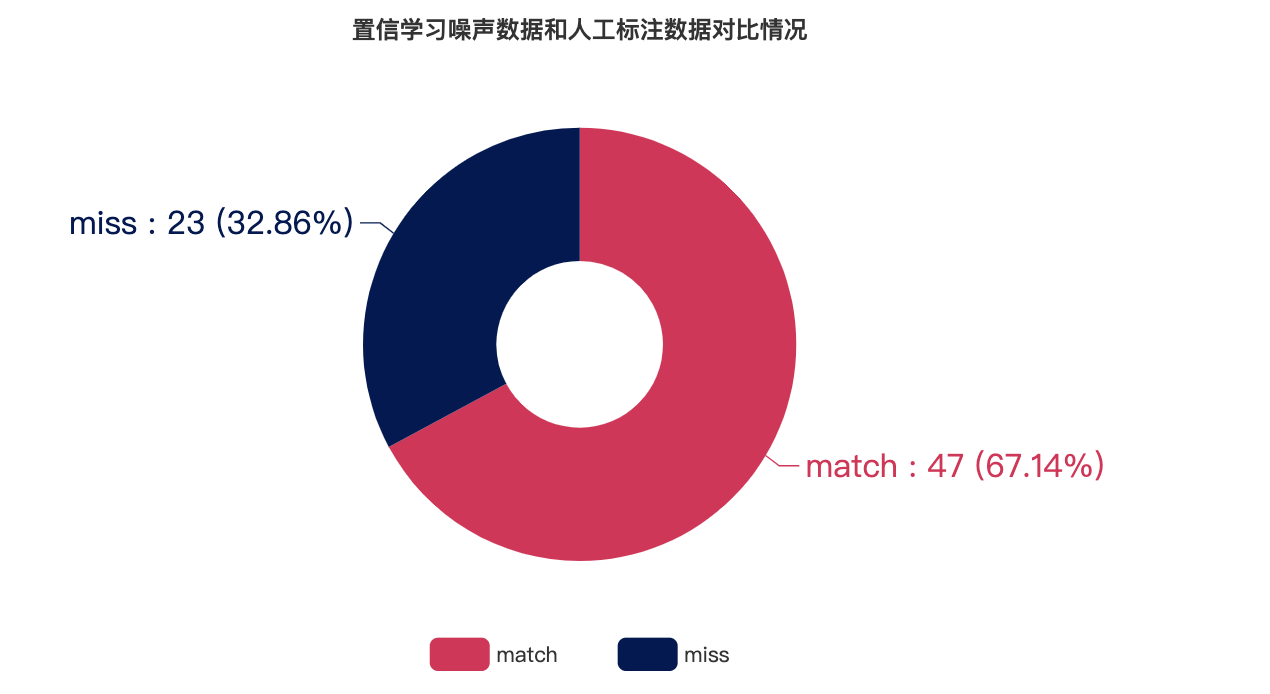
置信学习去噪结果和第一组人工标记结果对比
-
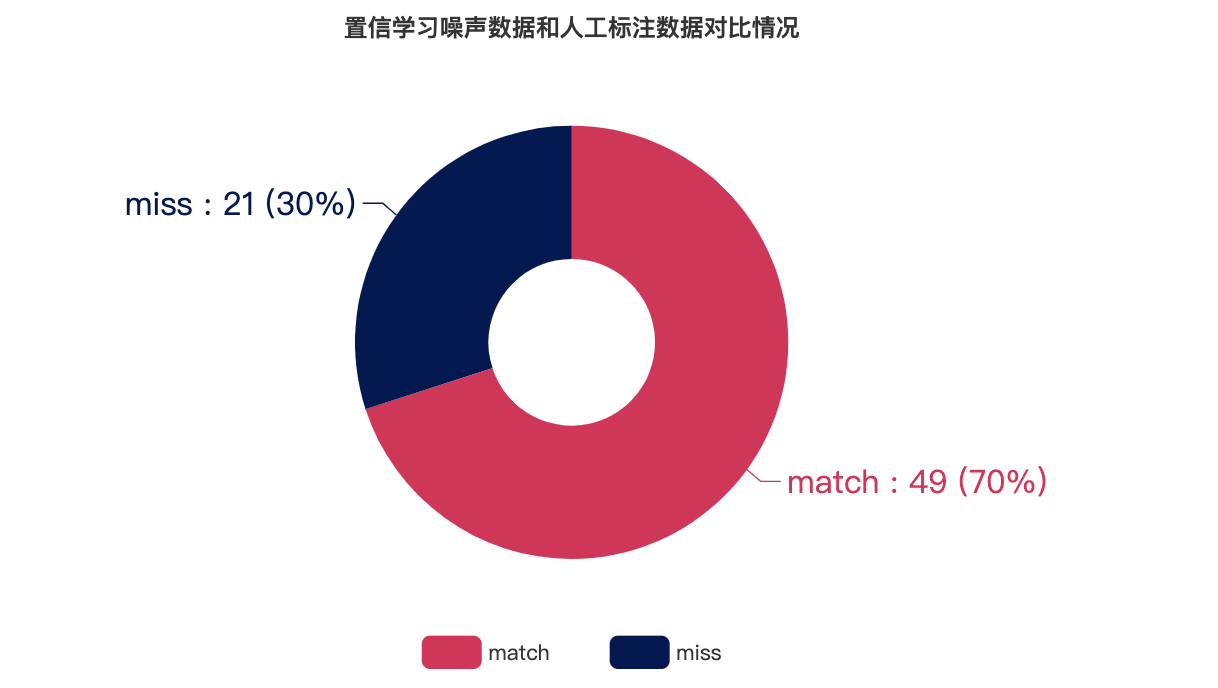
置信学习去噪结果和第二组人工标记结果对比
-
通过结合第一组人工标注与第二组人工标注结果得到用于比对的人工标注数据集,match表示置信学习得到的噪声数据和人工标记的噪声数据重合,miss表示置信学习得到的噪声数据未被人工标记
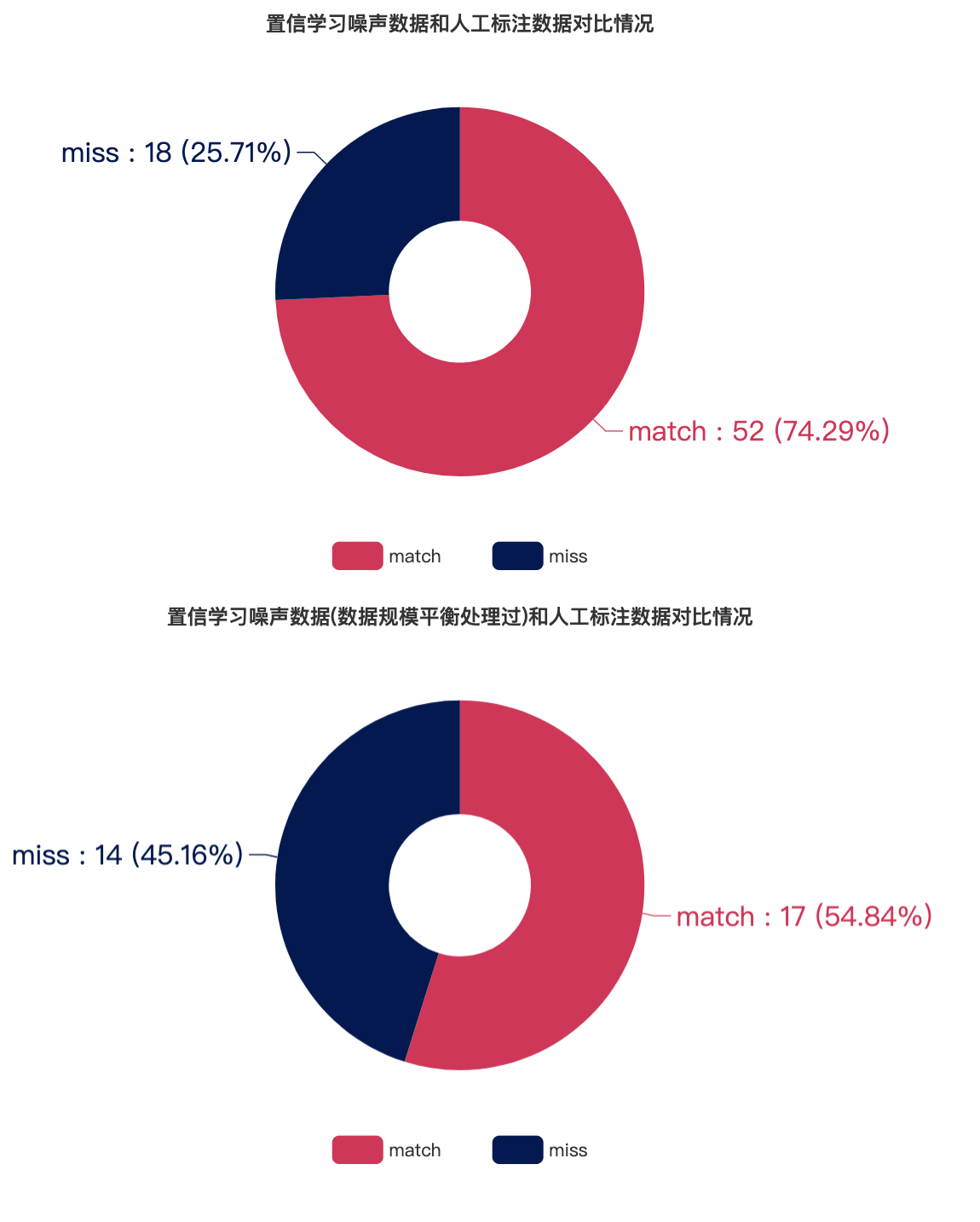
-
可以看出基于未平衡处理数据的置信学习去噪结果与人工标注的重合率达到74.3% ;基于平衡处理数据的置信学习去噪结果与人工标注的重合率也达到了55.9%
从图表数据可知,基于置信学习发现的噪声数据和人工标注的噪声数据重合度较高,因此我们认为置信学习能够对现有的自动化警告标记去噪