To perform Data preprocessing in a data set downloaded from Kaggle
##REQUIPMENTS REQUIRED: Hardware – PCs Anaconda – Python 3.7 Installation / Google Colab /Jupiter Notebook
Kaggle : Kaggle, a subsidiary of Google LLC, is an online community of data scientists and machine learning practitioners. Kaggle allows users to find and publish data sets, explore and build models in a web-based data-science environment, work with other data scientists and machine learning engineers, and enter competitions to solve data science challenges.
Data Preprocessing:
Pre-processing refers to the transformations applied to our data before feeding it to the algorithm. Data Preprocessing is a technique that is used to convert the raw data into a clean data set. In other words, whenever the data is gathered from different sources it is collected in raw format which is not feasible for the analysis. Data Preprocessing is the process of making data suitable for use while training a machine learning model. The dataset initially provided for training might not be in a ready-to-use state, for e.g. it might not be formatted properly, or may contain missing or null values.Solving all these problems using various methods is called Data Preprocessing, using a properly processed dataset while training will not only make life easier for you but also increase the efficiency and accuracy of your model.
Need of Data Preprocessing :
For achieving better results from the applied model in Machine Learning projects the format of the data has to be in a proper manner. Some specified Machine Learning model needs information in a specified format, for example, Random Forest algorithm does not support null values, therefore to execute random forest algorithm null values have to be managed from the original raw data set. Another aspect is that the data set should be formatted in such a way that more than one Machine Learning and Deep Learning algorithm are executed in one data set, and best out of them is chosen.
Importing the libraries
Importing the dataset
Taking care of missing data
Encoding categorical data
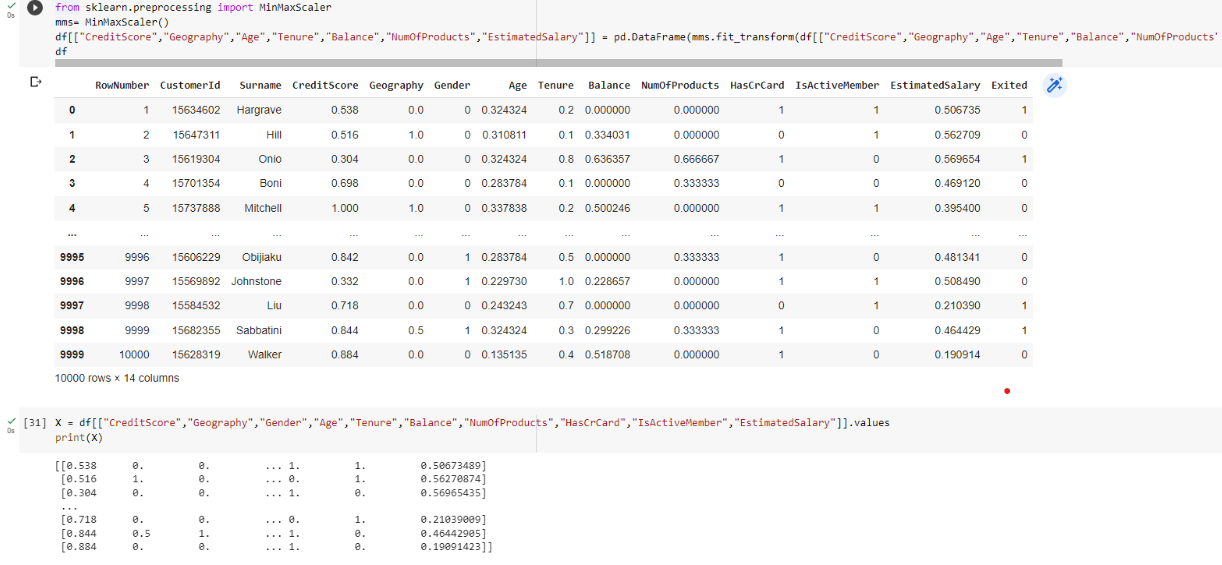
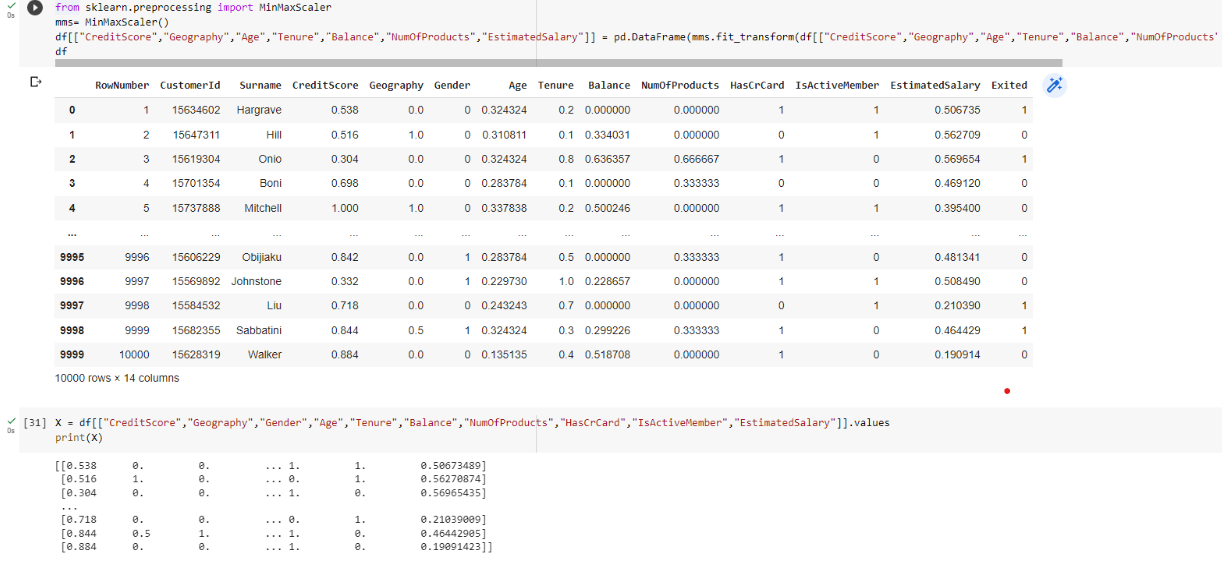
Normalizing the data
Splitting the data into test and train
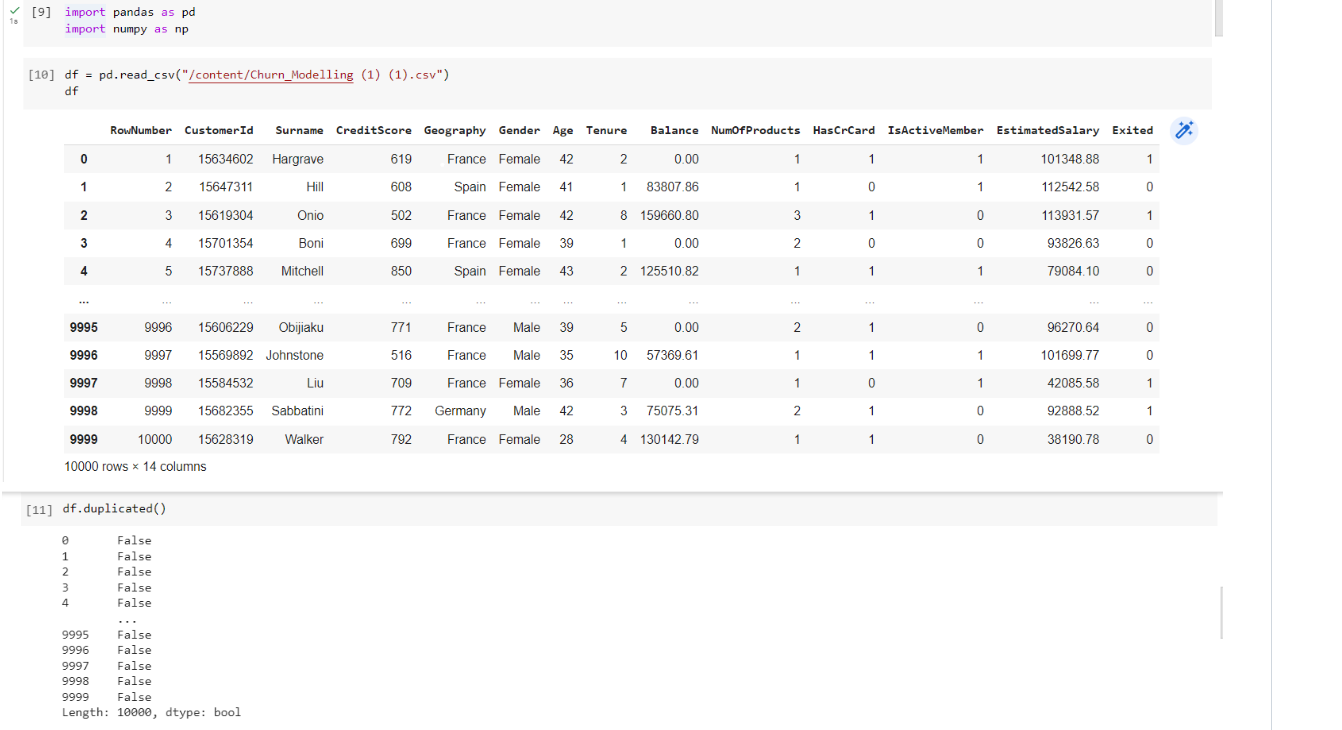
import pandas as pd import numpy as np
df.duplicated()
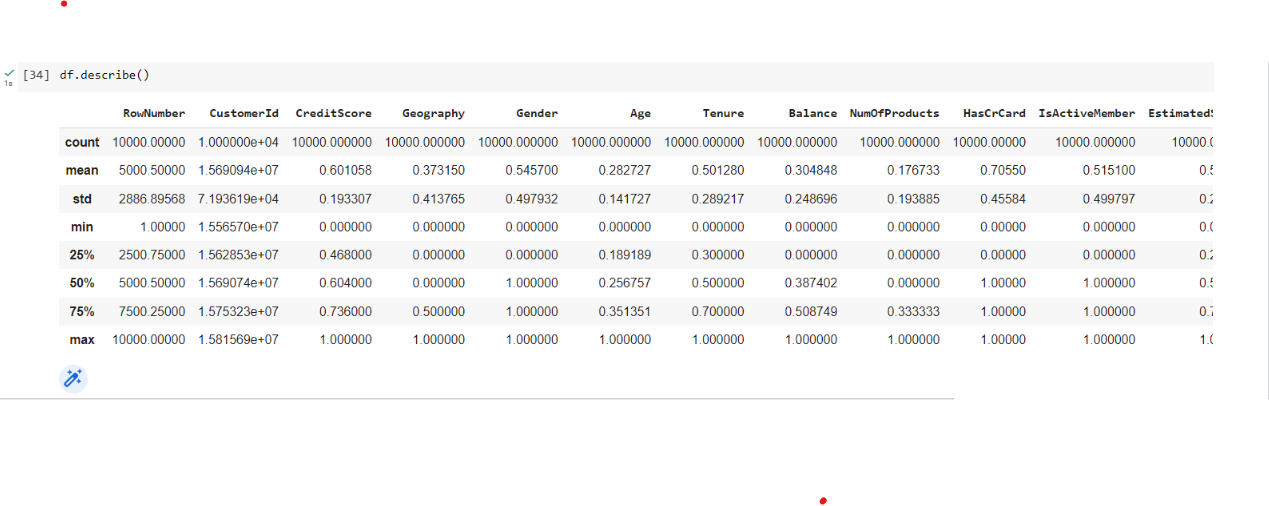
df.describe()
df.isnull().sum()
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() df["Geography"] = le.fit_transform(df["Geography"]) df["Gender"] = le.fit_transform(df["Gender"]) df
from sklearn.preprocessing import MinMaxScaler mms= MinMaxScaler() df[["CreditScore","Geography","Age","Tenure","Balance","NumOfProducts","EstimatedSalary"]] = pd.DataFrame(mms.fit_transform(df[["CreditScore","Geography","Age","Tenure","Balance","NumOfProducts","EstimatedSalary"]])) df
X = df[["CreditScore","Geography","Gender","Age","Tenure","Balance","NumOfProducts","HasCrCard","IsActiveMember","EstimatedSalary"]].values print(X)
y = df.iloc[:,-1].values print(y)
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
print(X_train) print("Size of X_train: ",len(X_train))
print(X_test) print("Size of X_test: ",len(X_test))
X_train.shape

Data preprocessing is performed in a data set downloaded from Kaggle.