Development
- Node.js 20.19.x, 22.12+, or 24+ and npm
- Rust stable
- Tauri prerequisites for your platform
- On Windows: Microsoft C++ Build Tools and WebView2
npm installNative app:
npm run tauri devBrowser mock mode:
npm run devBrowser mode does not use the Rust backend. It loads src/data/mockSession.ts after clicking Open a repository.
npm run test:rust
npm run build
npm run test:unit
npm run test:e2e:webtest:rust includes integration tests in src-tauri/tests/ that spawn the built diff-drift binary. test:unit runs the vitest component tests in tests/unit/.
Native E2E:
npm run test:e2e:tauriNative E2E builds a debug Tauri app and launches it with isolated environment variables:
DIFF_DRIFT_E2E_REPODIFF_DRIFT_E2E_EXPORT_PATHDIFF_DRIFT_E2E_STATE_FILEDIFF_DRIFT_E2E_BIN
Rust analyzer benchmarks are local-only and are not part of CI:
npm run benchFor optimization work, capture a Criterion baseline before changing code, then compare after:
cargo bench --manifest-path src-tauri/Cargo.toml -- --save-baseline pre-opt
cargo bench --manifest-path src-tauri/Cargo.toml -- --baseline pre-optThe deterministic product benchmark is part of CI:
npm run eval:engineIt builds temporary git repos from eval/cases/*.case.mjs, runs diff-drift check --json, and scores the result against each case oracle. Generated repos, reports, packets, answers, and latest score JSON live under .eval/ and are ignored.
Generate blind-review packets for another agent or human:
npm run eval:packetsPackets are written to .eval/packets/<case-id>/ with a prompt, Diff Drift markdown report, raw git diff, and metadata without the oracle. Save blind-agent JSON answers under .eval/answers/<case-id>.json — include an evaluator: { id, kind: "model" | "human", note } field so the scorecard can attribute them — then score:
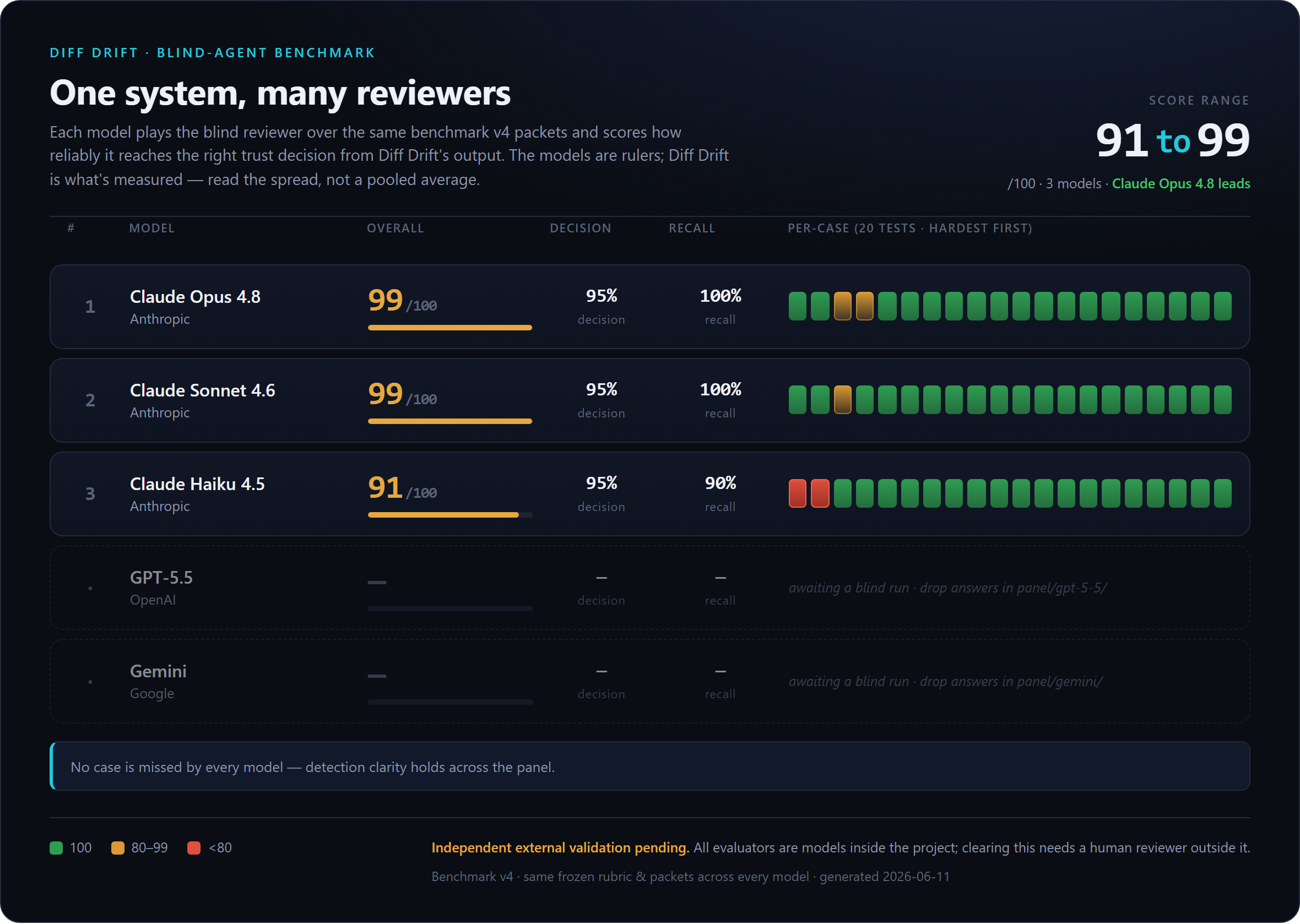
npm run eval:score-agentBlind-agent scoring writes .eval/results/agents/latest.json, .eval/results/agents/latest.md, and .eval/results/agents/latest.html. This scorecard is advisory, not a blocker: use it to see whether reviewers reach the right decisions, cite the right evidence, and where the report or rubric is confusing. Engine eval remains the CI gate; blind-agent scorecards are local product-quality telemetry with no network calls. Working outputs under .eval/ stay uncommitted; the one exception is published benchmark snapshots in eval/benchmarks/<version>/ (answers + scorecard), which exist so anyone can rescore the headline number from a fresh clone: npm run eval:score-agent -- eval/benchmarks/v3/answers. The scorecard reports decision accuracy, severity-weighted recall, localization, precision, and per-rule recall, lists every evaluator, and shows an "independent external validation pending" banner until a non-project human evaluator has contributed. The rubric, aliases, and accepted decisions are frozen before answers are generated; scorer changes start a new benchmark version instead of rewriting older scores. See Eval Methodology for the contract and A/B Study Design for the planned packet-vs-raw-diff study.
Use --case <case-id> with eval:engine or eval:packets to narrow a run while developing a fixture. Use --keep to preserve the generated temp repo path printed by the script for debugging.
Measure flag noise on real repos you choose (nothing bundled, nothing uploaded):
npm run eval:fp-replayIt reads fp-replay.config.json (copy fp-replay.config.example.json) and writes per-rule flag counts to .eval/results/fp-replay/latest.md — see Eval Methodology.
Visual regression checks are local-only and are not run in CI. They cover the browser mock onboarding, loaded session, and dismissed states.
npm run test:visualRegenerate baselines intentionally after a reviewed UI change:
npm run test:visual:update
npm run test:visual.github/workflows/ci.yml runs on every push/PR: cargo test + cargo clippy -- -D warnings on Windows; npm run build + unit tests + the web E2E on Ubuntu; a native Tauri build smoke (debug, no bundle) plus an advisory native E2E on Windows; and cargo audit + npm audit dependency gates on Ubuntu. Keep clippy clean — warnings fail the build.
The debug binary also serves the CLI: cargo run -- check <path> --json (or run the built diff-drift.exe check …). It is read-only by design; see the User Guide for flags and exit codes.
Rust unit tests use src-tauri/src/test_fixture.rs to build temporary git repos with git2. They should not depend on demo/ or a globally installed git binary.
The optional demo repo can be seeded with:
npm run seed:demoKeep changes narrow:
- Backend analyzer changes need Rust tests.
- Frontend copy or interaction changes need web E2E updates when assertions change.
- Native behavior changes should run native E2E locally when practical.
- Documentation changes should avoid repeating the README in every page.
-
src-tauri/src/rules.rs: rule predicates and tests. -
src-tauri/src/session.rs: analysis orchestration and counts. -
src-tauri/src/watcher.rs: live updates. -
src/App.tsx: main frontend state. -
src/types.tsandsrc-tauri/src/model.rs: shared contract.