지난강의에서 MySQL을 통해 RDB를 간단하게 알아보고 사용하는것을 해 보았습니다.
기초적인 내용만 배웠지만 PostgreSQL과 비교하면서 어떤 특징을 가지고 있고,
어떤 장단점을 가지고 있는지 알아봅시다.
설치를 문제없이 끝나고 나서 보면, 시작메뉴에 관련 프로그램들이 보이지 않는데
C:\Program Files\PostgreSQL\16\pgAdmin 4\runtime\pgAdmin4.exe
위 파일을 실행하면 됩니다.
MySQL처럼 PostgreSQL도 GUI를 통해 Database를 생성 할 수 있습니다.
그런데 Table을 생성하려고 보면 해당 탭이 바로 보이지는 않습니다.
이유는 바로 Table은 Schema 하위에 있기 때문입니다.
Schema를 열고 기본으로 설정된 Public Schema를 보면 Table 탭이 있습니다.
이 탭에 우클릭을 하면 Table을 생성 할 수 있습니다.
하지만 MySQL에서는 Database와 Table만 만들었지 Schema를 만든적은 없습니다.
이유는 바로 MySQL의 특징인데, 사실 만들었던것은 모두 Schema라는 것입니다.
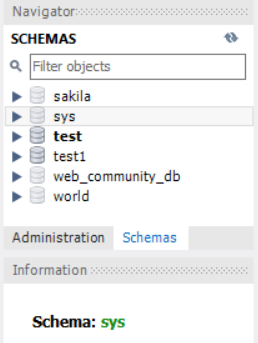
"실제로 MySQL의 GUI를 보면 Schema라고 되어있다."
Schema는 간단히 말하면 DB를 논리적으로 나눠놓은 공간입니다.
Database는 DB들을 물리적으로 나눠놓은 공간이고,
Table은 데이터가 저장되는 DB입니다.
그리고 이 가운데에 있는것이 데이터들을 논리적으로 나누어 관리하는 Schema 입니다.
Database들은 물리적으로 나뉘어져 있기에 서로 참조할수 없습니다.
하지만 Schema들은 논리적으로 나뉘어져 있을 뿐,
같은 공간 내에 있기 때문에 다른 Schema의 Table을 참조해 사용 할 수 있습니다.
앞서 말했듯이 MySQL의 Database는 Schema라고 했었습니다.
Database는 물리적으로 나뉘어진 구조기 때문에 참조를 못한다고 했었는데,
MySQL에서는 어떨지 보면
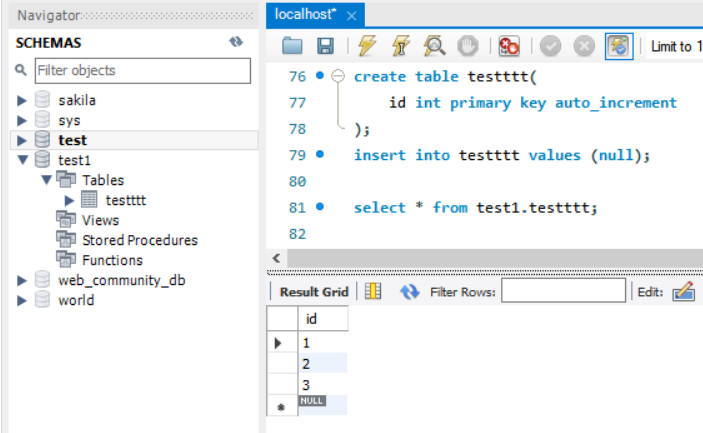
"Navigater를 보면 test를 사용중이지만, test1의 테이블을 select할수 있다."
다른 Database의 테이블을 읽는것을 볼 수 있습니다.
MySQL에서는 문자열을 입력할때 "또는 '을 모두 사용 할 수 있었습니다.
하지만 PostgreSQL에서는 따옴표의 용법이 살짝 다릅니다.
PostgreSQL은 문자열을 입력받을때 무조건 '를 사용해야만 합니다.
MySQL을 생각하고 "를 사용하면 에러를 볼 수 있습니다.
PostgreSQL에서 Database나 Table 등을 만들때,
이름에 대문자를 넣으면 모두 소문자로 교체되어 생성되게 되는데,
만약 이름에 대문자를 사용하고 싶을 때,
이름을 "로 감싸주면 대문자를 사용할 수 있게 됩니다.
MySQL과 PostgreSQL은 자료형에서도 조금 차이가 있습니다.
MySQL에 저장되는 데이터는 형식의 차이가 있을뿐,
column당 하나의 데이터가 저장됩니다.
그런데 PostgreSQL은 자료형으로 배열을 지원해서
하나의 column에도 여러 데이터를 저장 할 수 있습니다.
이 외에도 json을 지원하는 등 MySQL과는 확실한 차이를 보입니다.
또한 PostgreSQL에는 serial이라는 자료형이 있는데,
int형의 PK를 만들때 Primary key auto_increment를 일일히 입력할 필요 없이
위 내용이 자동으로 적용된 자료형입니다.
데이터베이스는 여러 단위로 나뉩니다.
Tablespace > Data File > Segment > Extent > Block
가장 작은 단위인 Block은 Page 또는 DataBlock이라고 불립니다.
한 페이지 안에는 하나의 Row가 들어가게 됩니다.
Extent는 Page들의 집합이며,
Segment는 Extent들의 모음입니다.
Tablespace 가장 큰 단위이며 데이터를 물리적으로 저장하는 공간입니다.
DB를 여러곳에서 동시에 이용할 경우엔 여러개의 Transaction이 실행되게 됩니다.
이 Transaction들이 쿼리 수행 시점의 데이터를 일관적으로 보장하게 하고,
DB를 읽거나 쓸때 충돌이 일어나지 않게 하는것이 MVCC입니다.
MySQL과 PostgreSQL은 이 MVCC를 구현한 방식이 다릅니다.
먼저 MySQL은 Undo segment(Rollback segment)를 이용합니다.
Transaction들은 각자 자기만의 Undo log를 배정받습니다.
Transaction에서 변경된 데이터는 모두 이 Undo log에 저장되고,
그 뒤에 변경된 내용들은 앞의 내용을 포인터로 가리키는 형태입니다.
새 Transaction이 생기면 이 포인터로 연결된 리스트를 훑어
자신이 읽을수 있는 시점의 데이터를 가져옵니다.
Undo log는 Transaction이 존재하는동안 계속 유지되고 있으며,
그만큼 데이터에 연결된 리스트가 길어지므로
너무 오래 Transaction을 열어두게 되면 Read Latency에 영향이 생기게 됩니다.
반면 PostgreSQL은 데이터의 변경 전과 변경 후 Tuple(record)를
같은 Page내에 함께 기록하는데,
Tuple이 생성되거나 변경된 시점을
xmin, xmax라는 metadata field에 함께 저장합니다.
그리고 이 시점을 비교하는 방법으로 MVCC를 구현합니다.
Vacuum이란 PostgreSQL에서 MVCC를 구현하면서 나오게 된 PostgreSQL만의 동작입니다.
Vacuum이 하는 역할은 여러가지지만 크게 2가지의 역할이 있습니다.
첫번째는 Dead tupel 정리, 두번째는 Transaction ID Wraparound 방지입니다.
Transaction이 Commit되거나 Rollback되면
더이상 사용되지 않는 Dead tuple이 생기게 됩니다.
이 Dead tuple은 용량과 자리는 그대로 차지하기 때문에
현재 사용하는 Live tuple을 읽을때 더 많은 자원을 소모하게 합니다.
이때 vacuum을 수행하면 Dead tuple을 정리하고 처리속도를 최적화 할 수 있습니다.
이 Vacuum에도 2가지 종류가 있습니다.
일반적인 Vacuum이나 AutoVacuum은 Dead tuple을 지워서 재사용 가능하게 하지만,
공간까지 최적화 하지는 못해서, 테이블의 사이즈는 그대로 유지되게 됩니다.
반면 vacuum full을 사용하면 공간까지 최적화 하게 되나,
대상 테이블을 복사하여 처리하기 때문에 디스크 용량 여유가 필요하고,
모든 작업에 Lock이 걸리기 때문에 select 작업도 중지하게 됩니다.
vacuum은 내부 알고리즘에 따라 주기적으로 실시되며,
이것을 Auto Vacuum이라고 부릅니다.
PostgreSQL은 시점을 Tuple에 xmin, xmax라는 Transaction ID(XID)로 저장하고
이 값을 비교하여 MVCC를 구현합니다.
이때 사용되는 xmin, xmax은 4byte 값인데,
4byte는 약 43억(232)개의 Transaction을 표현 할 수 있으며
현재 XID 수치의 반은 과거, 반은 미래를 표현하는 값으로 사용되게 됩니다.
중요한것은 이 Trasaction ID는 무한하지 않다 라는 것인데요.
만약 XID가 232을 넘어가게 되면,
Transaction ID Wraparound라는 현상이 발생하게 됩니다.
이 현상은 미래와 과거의 데이터가 뒤섞이는 심각한 문제이기 때문에
Current XID - 생성시점 XID가 약 21억을 초과하기 전에
XID를 Frozen XID 이라고 부르는 값인 2로 변경해줍니다.
이 동작을 Freeze 또는 Anti Wraparound Vacuum이라고 부릅니다.
이러한 Freeze 대상을 선정하기 위해 Age라는 개념이 도입되었습니다.
Age는 Tuple이 insert 되었을때 1부터 시작하며,
DB에서 트랜잭션이 발생할 때 마다 1씩 증가합니다.
즉 Age는 생성시점 XID와 Current XID의 차이를 의미합니다.
Age가 AUTOVACUUM_FREEZE_MAX_AGE에 도달하면 Freeze를 자동으로 실행되게 되고,
수동적으로는 vacuum freeze를 사용하게 되면 모든 튜플의 XID를 2로 변경합니다.
먼저 pg 모듈을 설치해야 합니다.
npm install pg
정상적으로 node_modules 안에 모듈이 설치되더라도
실행시 pg 모듈이 없다고 오류가 뜰 경우엔
간단하게 한번 더 설치하면 해결됩니다.
설치가 끝난 뒤 사용 방법은
Java에서 MySQL을 사용하던것과 크게 다르지 않습니다.
const { Client } = require('pg');
const client = new Client({
user: "<계정>",
host : "<주소>",
database: "<데이터베이스>",
password: "<암호>",
port: 5432(기본포트),
});
먼저 pg모듈을 불러와 Client를 선언하고,
접속 정보를 넣어줍니다.
그 다음엔 client.connect();로 DB서버와 연결하고,
client.query("<쿼리문>", <처리할 함수>)를 사용하면 됩니다.
// 사용 예시
client.connect();
client.query("SELECT * FROM now()", (error, response) => {
console.log(error);
console.log(response);
client.end();
});
response는 Select의 결과를 Json으로 반환합니다.
Java에서는 .next()를 이용해 한줄 한줄 읽어야 했었지만
JS는 오브젝트가 있기 때문에 Json을 그대로 사용할 수 있습니다.
console.log(respons.rows[0].now);
//결과
//2024-03-25T23:51:48.594Z