



Install AdalFlow with pip:
pip install adalflowPlease refer to the full installation guide for more details.
- Try the Building Quickstart in Colab to see how AdalFlow can build the task pipeline, including Chatbot, RAG, agent, and structured output.
- Try the Optimization Quickstart to see how AdalFlow can optimize the task pipeline.
- Embracing a design pattern similar to PyTorch, AdalFlow is powerful, light, modular, and robust.
AdalFlow provides
Model-agnosticbuilding blocks to build LLM task pipelines, ranging from RAG, Agents to classical NLP tasks like text classification and named entity recognition. It is easy to get high performance only using manual prompting. - AdalFlow provides a unified auto-differentiative framework for both zero-shot prompt optimization and few-shot optimization. It advances existing auto-optimization research, including
Text-GradandDsPy. Through our research,Text-Grad 2.0andLearn-to-Reason Few-shot In Context Learning, AdalFlowTrainerachieves the highest accuracy while being the most token-efficient.
Here is an optimization demonstration on a text classification task:
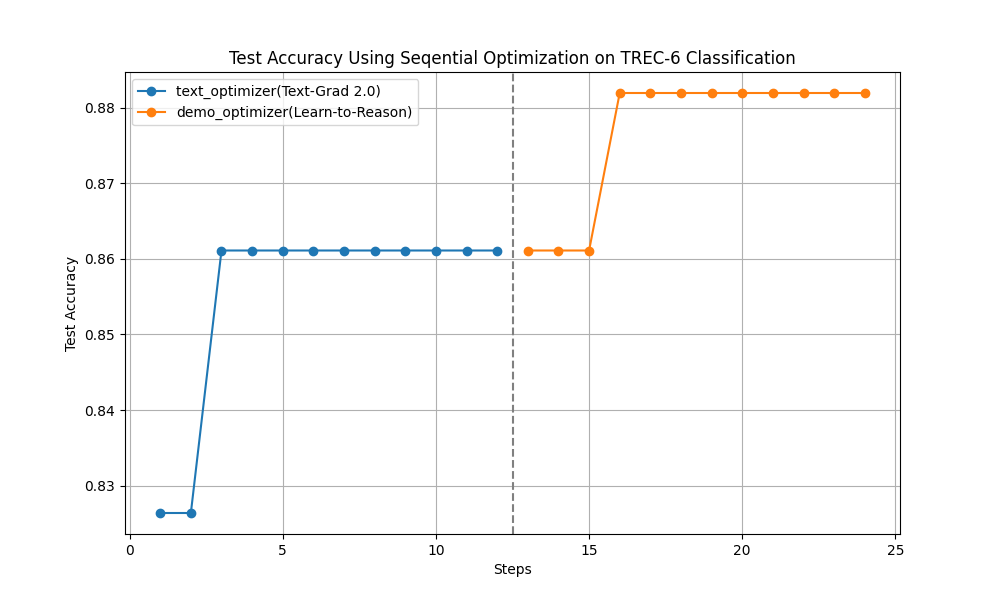

Among all libraries, AdalFlow achieved the highest accuracy with manual prompting (starting at 82%) and the highest accuracy after optimization.
Further reading: Optimize Classification
LLMs are like water; AdalFlow help you quickly shape them into any applications, from GenAI applications such as chatbots, translation, summarization, code generation, RAG, and autonomous agents to classical NLP tasks like text classification and named entity recognition.
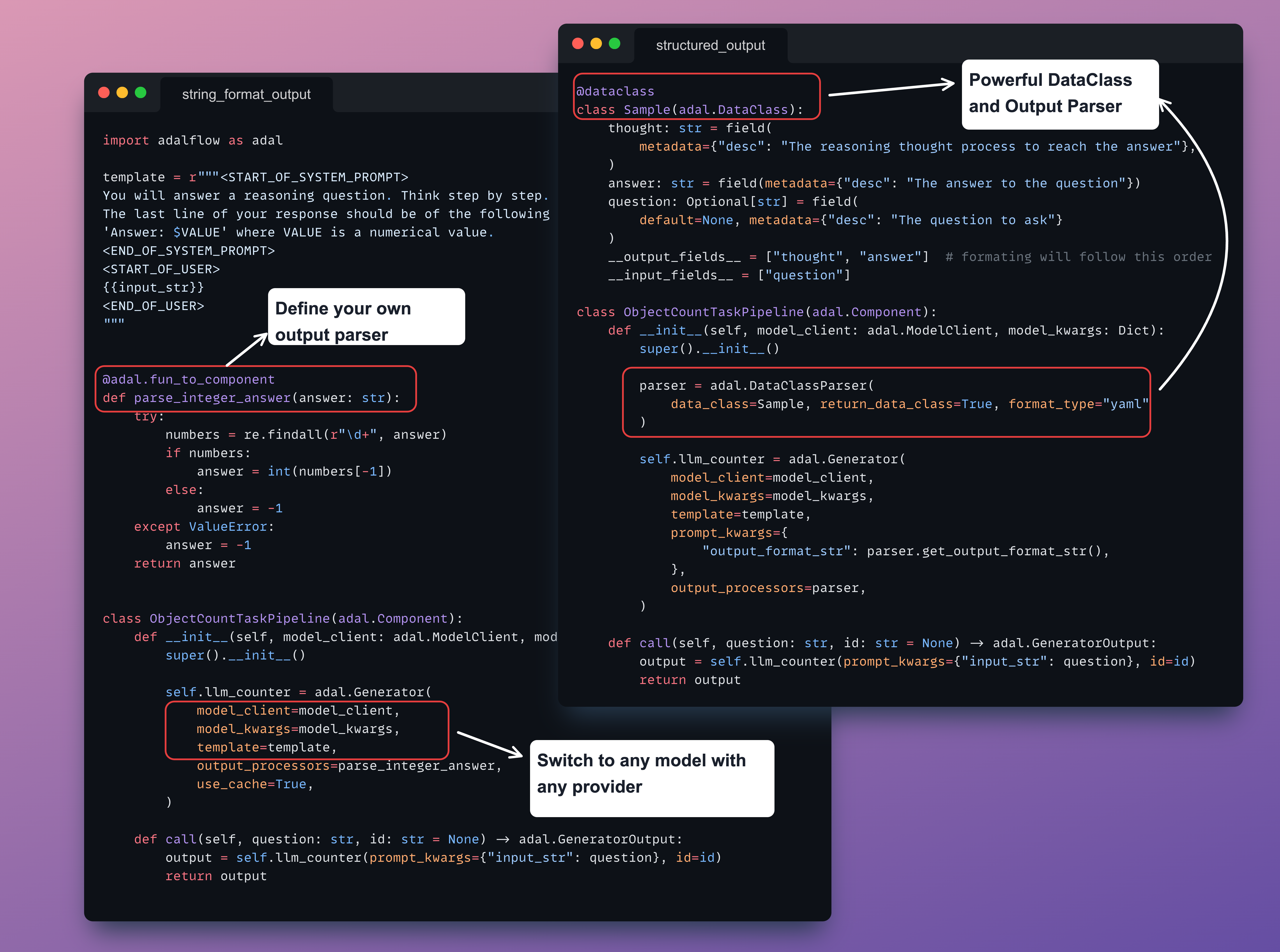
AdalFlow has two fundamental, but powerful, base classes: Component for the pipeline and DataClass for data interaction with LLMs.
The result is a library with minimal abstraction, providing developers with maximum customizability.
You have full control over the prompt template, the model you use, and the output parsing for your task pipeline.
Many providers and models accessible via the same interface:
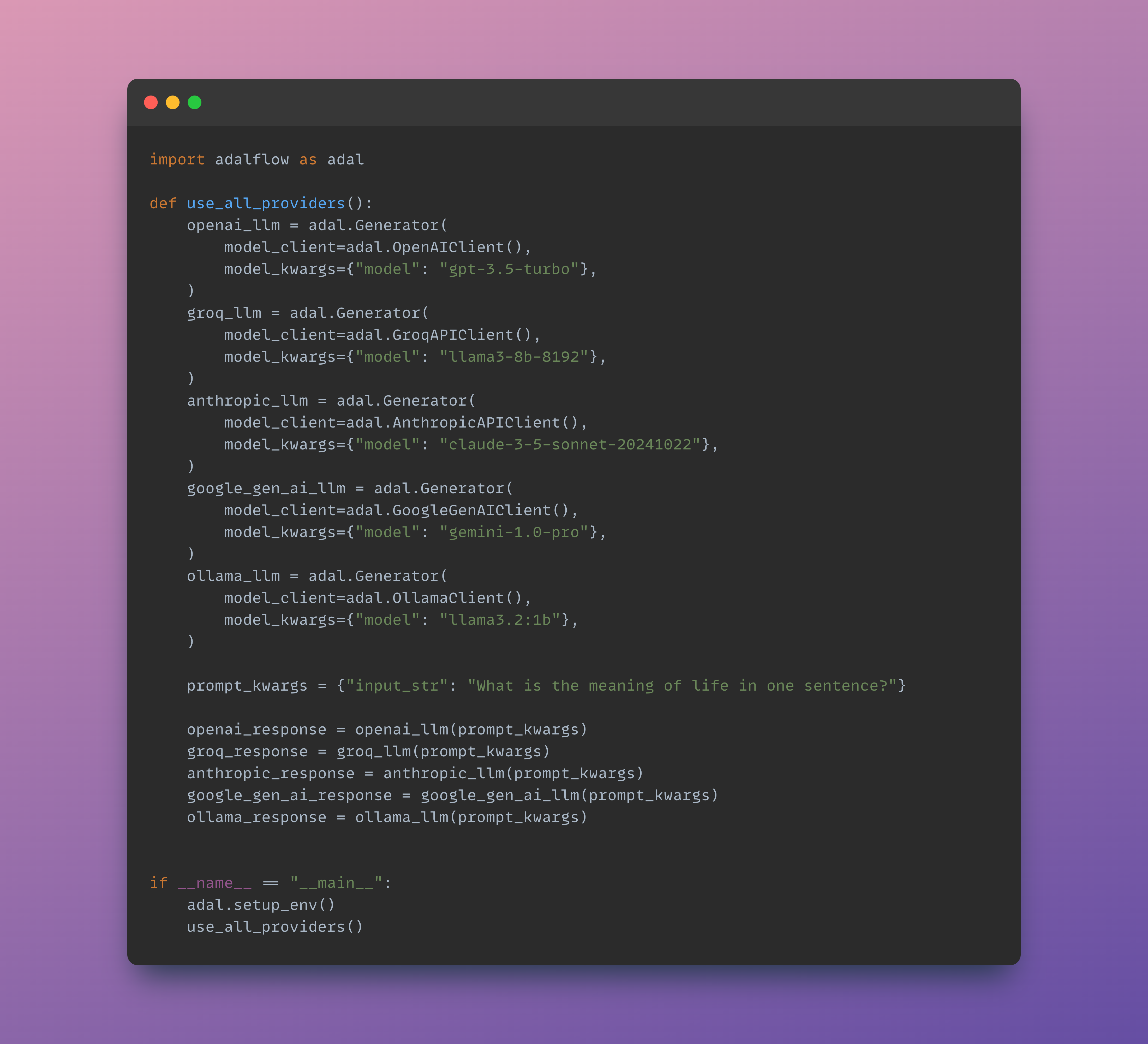
Further reading: How We Started, Design Philosophy and Class hierarchy.
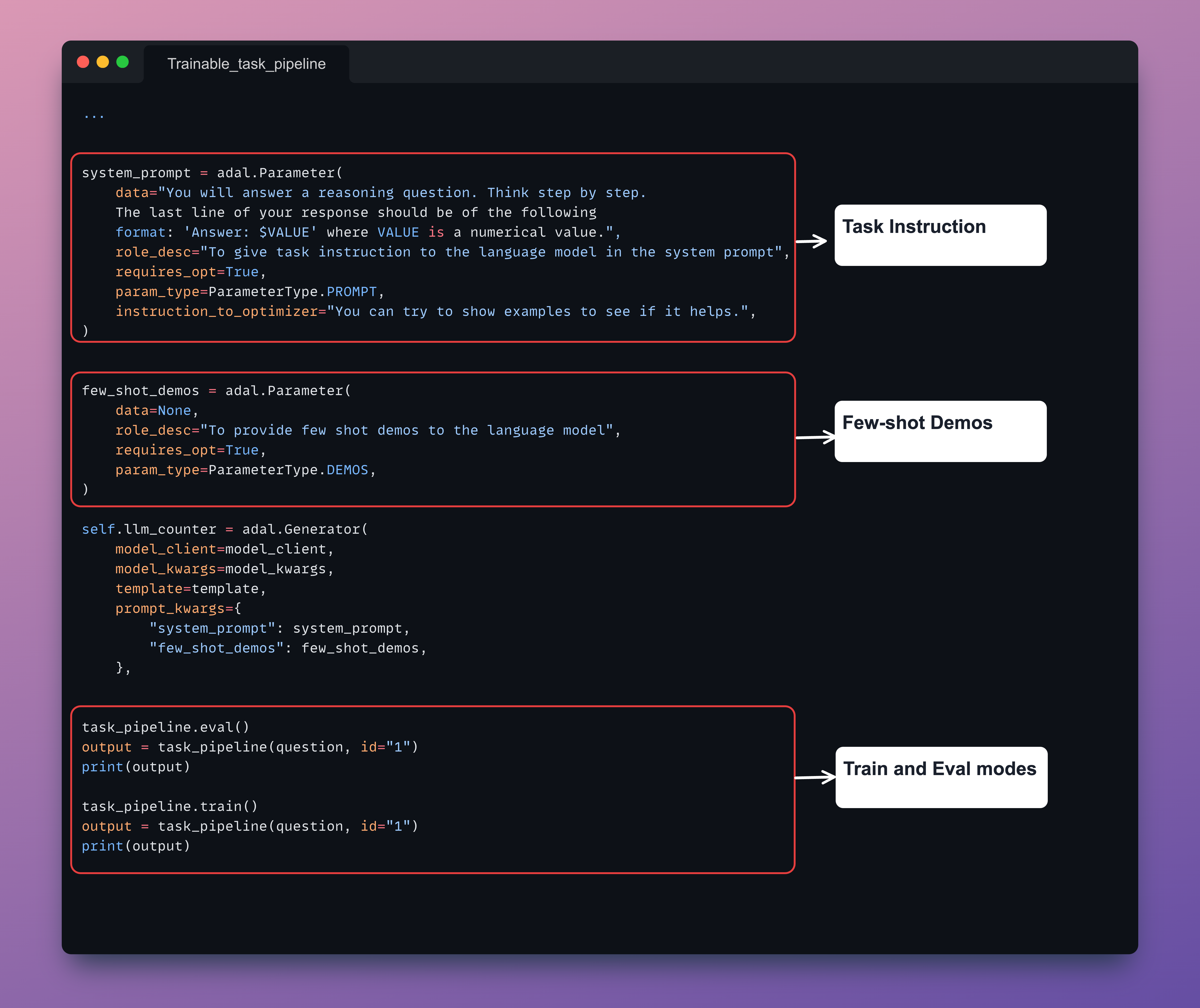
AdalFlow provides token-efficient and high-performing prompt optimization within a unified framework.
To optimize your pipeline, simply define a Parameter and pass it to AdalFlow's Generator.
Whether you need to optimize task instructions or run some few-shot demonstrations,
AdalFlow's unified framework offers an easy way to diagnose, visualize, debug, and train your pipeline.
This Dynamic Computation Graph demonstrates how our auto-differentiation and the dynamic computation graph work.
No need to manually defined nodes and edges, AdalFlow will automatically trace the computation graph for you.
Just define it as a Parameter and pass it to AdalFlow's Generator.
AdalComponent acts as the 'interpreter' between task pipeline and the trainer, defining training and validation steps, optimizers, evaluators, loss functions, backward engine for textual gradients or tracing the demonstrations, the teacher generator.
AdalFlow full documentation available at adalflow.sylph.ai:
- How We Started
- Introduction
- Full installation guide
- Design philosophy
- Class hierarchy
- Tutorials
- Supported Models
- Supported Retrievers
- API reference
AdalFlow is named in honor of Ada Lovelace, the pioneering female mathematician who first recognized that machines could go beyond mere calculations. As a team led by a female founder, we aim to inspire more women to pursue careers in AI.
The AdalFlow is a community-driven project, and we welcome everyone to join us in building the future of LLM applications.
Join our Discord community to ask questions, share your projects, and get updates on AdalFlow.
To contribute, please read our Contributor Guide.
Many existing works greatly inspired AdalFlow library! Here is a non-exhaustive list:
- 📚 PyTorch for design philosophy and design pattern of
Component,Parameter,Sequential. - 📚 Micrograd: A tiny autograd engine for our auto-differentiative architecture.
- 📚 Text-Grad for the
Textual Gradient Descenttext optimizer. - 📚 DSPy for inspiring the
__{input/output}__fieldsin ourDataClassand the bootstrap few-shot optimizer. - 📚 OPRO for adding past text instructions along with its accuracy in the text optimizer.
- 📚 PyTorch Lightning for the
AdalComponentandTrainer.
@software{Yin2024AdalFlow,
author = {Li Yin},
title = {{AdalFlow: The Library for Large Language Model (LLM) Applications}},
month = {7},
year = {2024},
doi = {10.5281/zenodo.12639531},
url = {https://github.com/SylphAI-Inc/AdalFlow}
}