调查Neo4j data importer 功能,使用流程和交互体验 #7
Valdanitooooo
started this conversation in
General
Replies: 0 comments
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Uh oh!
There was an error while loading. Please reload this page.
-
调查Neo4j data importer 功能,使用流程和交互体验
地址
https://data-importer.graphapp.io/
导入例子数据
通过帮助里的Welcome tutorial -> Review an example 导入 例子数据
Preview界面可以查看少量抽样数据,而且具有部分的图分析功能
点击导入,成功后可以查看结果,包括使用时间,导入记录数,分不同步骤的查询语句,方便验证导入是否成功。
节点导入分2步,这些使得用户很容易理解导入过程到底做了什么,是否和预期的一致:
边导入只有 Load Query, dgraph和neo4j应该都是2个数据节点之间只有1条同类型的边,而nebula需要在边上有一个特殊id不同才能添加多条同类型边。因此不需要唯一索引。
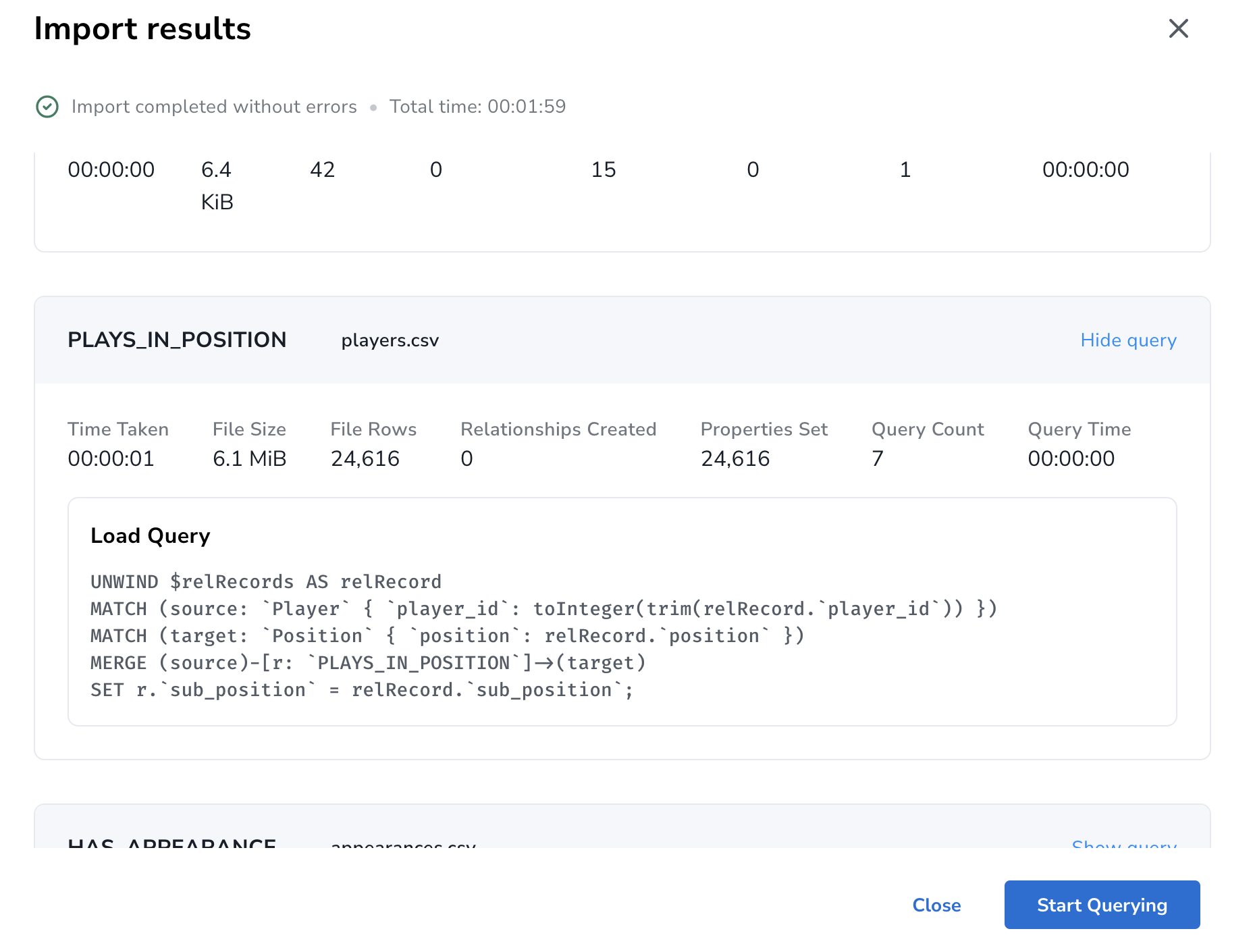
百万条边或节点导入速度都很快,单机上几秒到几十秒
左侧 CSV文件列表有字段列表,右侧有mapping details
字段列表有绿点表示被mapping,也有sample数据让用户理解字段的含义
右侧的mapping details 让用户选schema节点映射到哪个文件
节点Properties下,用户可以选择CSV文件里哪些字段加入到节点schema的属性,系统会自动读取前面几十/几百行,判断类型。
Add new 按钮可以添加其他不同名字的字段。
Mapping Tab 可以用来查看,但一般不需要再做一次mapping
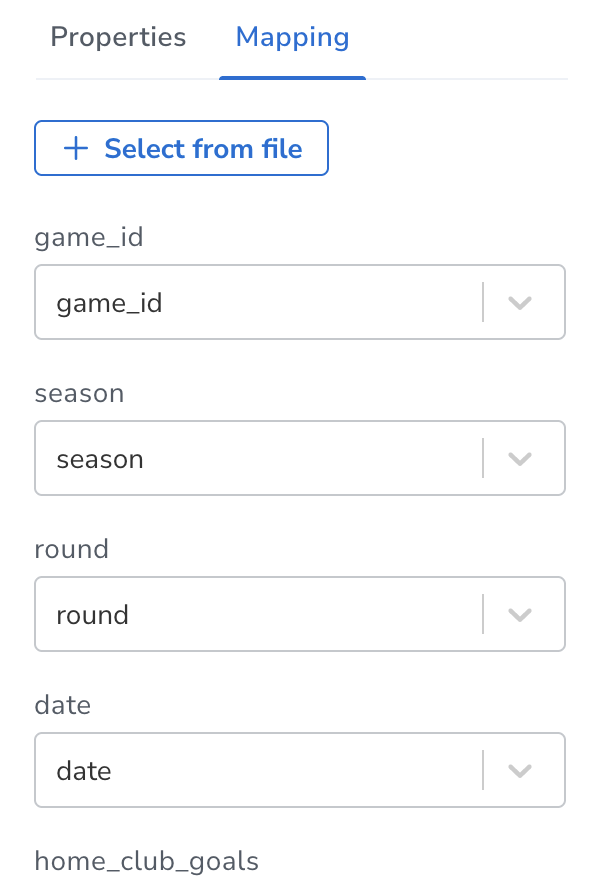
底部的ID选框标识唯一ID
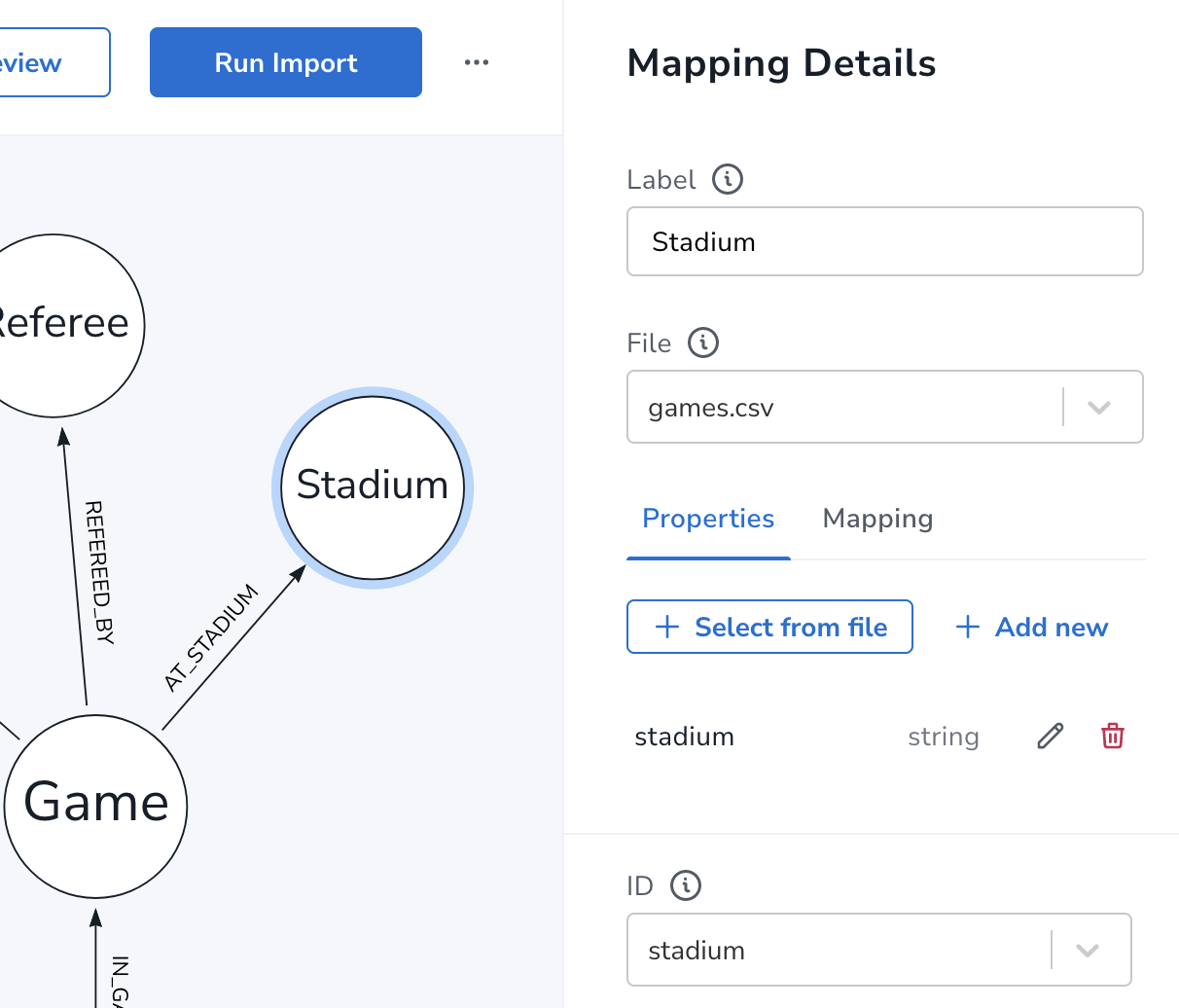
同一个表同一个行包含多个节点和关系(宽表)用同样方法映射
这个games.csv表已经用在Game节点,这里需要指定字段和唯一ID,不一定是数字,可能是string
边的映射 所在文件,From, To 以及icon提示的帮助等
边设置属性和节点类似
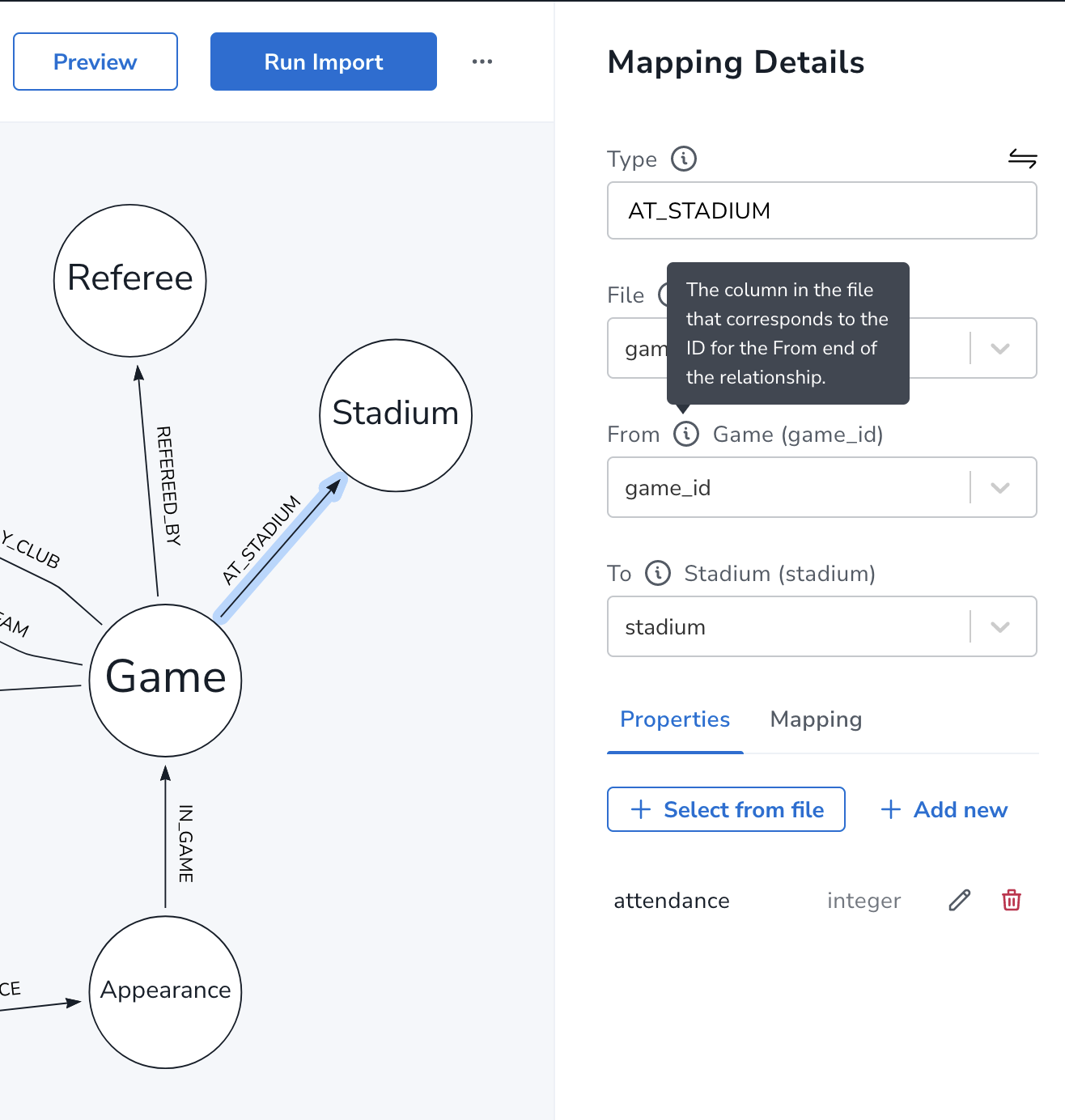
在已有节点边缘拖动快速添加新节点和边
没有完成映射的节点和边用虚线表示
Beta Was this translation helpful? Give feedback.
All reactions