Paper · Project Page · BibTeX
This repository contains the official implementation of Volume Transformer (Volt).
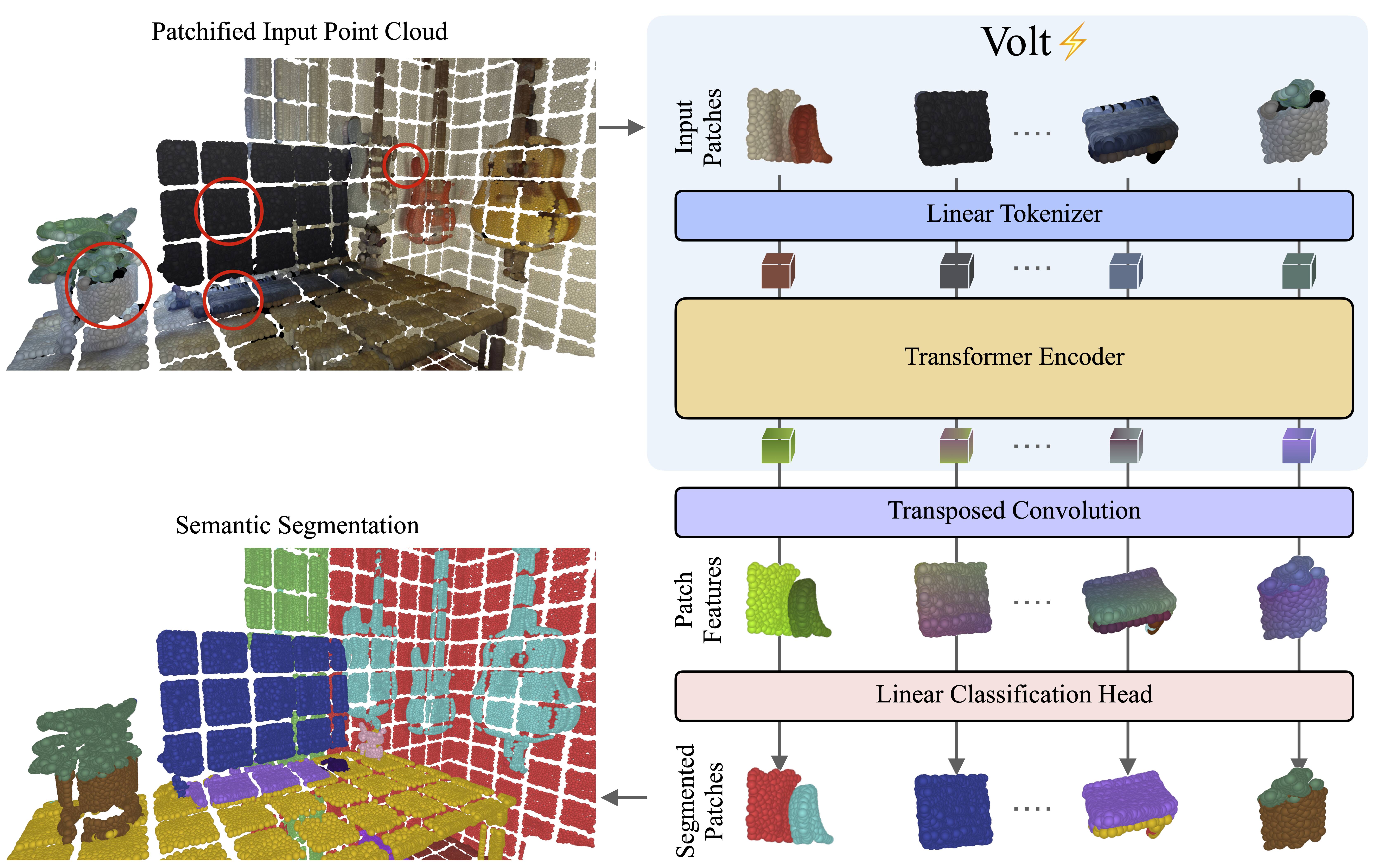
Volt partitions the input 3D scene into non-overlapping volumetric patches and embeds each patch into a token with a linear tokenizer. The resulting token sequence is processed by a Transformer encoder with global attention. The latent tokens are then upsampled back to the voxel resolution with a single transposed convolution and mapped to semantic predictions by a linear classification head.
The core Volt model implementation can be found in
pointcept/models/volt/volt_base.py.
- 2026-04-22: Code release.
This repository is built on top of Pointcept and incorporates components from SGIFormer for instance segmentation. For integrating image features with 3D backbones, please refer to our DITR codebase.
We recommend using uv, a fast Python package and environment manager, to install the environment.
To install uv on macOS and Linux, run:
curl -LsSf https://astral.sh/uv/install.sh | shThen set up the environment with:
# Make sure to load CUDA 12.6 beforehand
# This will automatically create a virtual environment (.venv) and install dependencies from pyproject.toml
uv sync
source .venv/bin/activateFollow the dataset setup instructions in the Pointcept README.
Preprocessing for indoor datasets is identical to Pointcept.
For nuScenes, run the preprocessing script below. Unlike Pointcept preprocessing, we additionally write panoptic labels to the .pkl files.
uv run --no-project --python 3.12 --with nuscenes-devkit python pointcept/datasets/preprocessing/nuscenes/preprocess_nuscenes_info.py --dataset_root ${NUSCENES_DIR} --output_root ${PROCESSED_NUSCENES_DIR}For SemanticKITTI, run the following script to generate the instance database used for instance CutMix.
python pointcept/datasets/preprocessing/semantic_kitti/build_instance_db_h5.py --dataset_root ${KITTI_DIR} --output_root "data/semantic_kitti_instances"For Waymo, run the preprocessing script below. Waymo provides multiple LiDAR sensors. Unlike Pointcept preprocessing, we use only the points from the TOP LiDAR sensor, since only those points have semantic labels.
uv run --no-project --python 3.10 --with waymo-open-dataset-tf-2-11-0 python pointcept/datasets/preprocessing/waymo/preprocess_waymo.py --dataset_root ${WAYMO_DIR} --output_root ${PROCESSED_WAYMO_DIR} --splits training validation --num_workers ${NUM_WORKERS}Download UNet teacher weights from HuggingFace
hf download KadirYilmaz/Volt --include "teacher_weights/*.pth" --local-dir weights/Then, run the training script with the semseg-volt-distill config for each dataset.
### ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-volt-distill -n semseg-volt-distill
### ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-volt-distill -n semseg-volt-distill
### ScanNet++
sh scripts/train.sh -g 4 -d scannetpp -c semseg-volt-distill -n semseg-volt-distill
### NuScenes
sh scripts/train.sh -g 4 -d nuscenes -c semseg-volt-distill -n semseg-volt-distill
### SemanticKITTI
sh scripts/train.sh -g 4 -d semantic_kitti -c semseg-volt-distill -n semseg-volt-distill
### Waymo
sh scripts/train.sh -g 4 -d waymo -c semseg-volt-distill -n semseg-volt-distillFor joint training, use the semseg-volt-joint-small config instead.
### ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-volt-joint-small -n semseg-volt-joint-small
### ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-volt-joint-small -n semseg-volt-joint-small
### NuScenes
sh scripts/train.sh -g 4 -d nuscenes -c semseg-volt-joint-small -n semseg-volt-joint-small
### SemanticKITTI
sh scripts/train.sh -g 4 -d semantic_kitti -c semseg-volt-joint-small -n semseg-volt-joint-small
### Waymo
sh scripts/train.sh -g 4 -d waymo -c semseg-volt-joint-small -n semseg-volt-joint-smallFirst, run the preprocessing script to generate superpoints for ScanNet and ScanNet200.
python pointcept/datasets/preprocessing/scannet/preprocess_superpoints.py --dataset_root ${RAW_SCANNET_DIR} --output_root ${PROCESSED_SCANNET_DIR}Download the pretrained Volt-S backbone weights from HuggingFace
mkdir -p weights
curl -L -o weights/volt-small-scannet.pth https://huggingface.co/KadirYilmaz/Volt/resolve/main/Volt_experiments/joint_training_small/scannet/model/model_last.pth
curl -L -o weights/volt-small-scannet200.pth https://huggingface.co/KadirYilmaz/Volt/resolve/main/Volt_experiments/joint_training_small/scannet200/model/model_last.pthAlternatively you can train them yourself using the corresponding configs above.
Then, run the training script with the insseg-spformer-volt-S-0-base config for scannet/scannet200
### ScanNet
sh scripts/train.sh -g 4 -d scannet -c insseg-spformer-volt-S-0-base -n insseg-volt
### ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c insseg-spformer-volt-S-0-base -n insseg-voltWe provide the experiment directories, including configs, logs, and checkpoints. The experiments can also be seen from Hugging Face.
| Model | Dataset | Val mIoU | Exp. Dir |
|---|---|---|---|
| Volt-S | ScanNet | 76.3 | link |
| Volt-S | ScanNet200 | 36.1 | link |
| Volt-S | ScanNet++ | 50.2 | link |
| Volt-S | nuScenes | 81.1 | link |
| Volt-S | SemanticKITTI | 70.3 | link |
| Volt-S | Waymo | 71.2 | link |
| Model | Dataset | Val mIoU | Exp. Dir |
|---|---|---|---|
| Volt-S | ScanNet | 80.2 | link |
| Volt-S | ScanNet200 | 38.5 | link |
| Volt-S | nuScenes | 81.8 | link |
| Volt-S | SemanticKITTI | 72.8 | link |
| Volt-S | Waymo | 72.5 | link |
If you use our work in your research, please use the following BibTeX entry.
@article{yilmaz2026volt,
title = {{Volume Transformer: Revisiting Vanilla Transformers for 3D Scene Understanding}},
author = {Yilmaz, Kadir and Kruse, Adrian and Höfer, Tristan and de Geus, Daan and Leibe, Bastian},
journal = {arXiv preprint arXiv:2604.19609},
year = {2026}
}