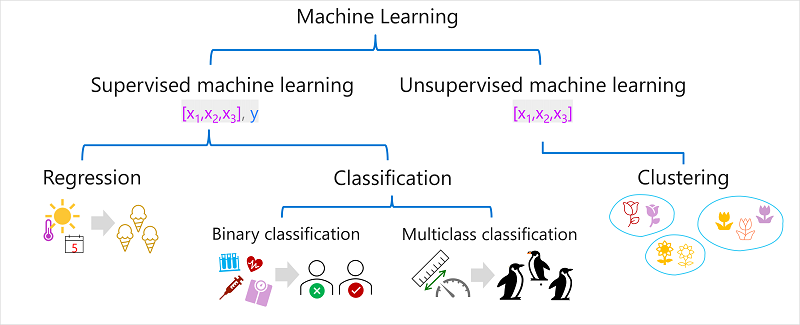
Machine learning has its origins in statistics and mathematical modeling of data. The fundamental idea of machine learning is to use data from past observations to predict unknown outcomes or values.
🔧 Machine Learning: The Intersection of Data Science and Software Engineering
-
Machine learning combines data science and software engineering to create predictive models.
-
Data scientists:
- Explore and prepare data.
- Train machine learning models using the prepared data.
-
Software developers:
- Integrate trained models into software applications.
- Use the models to predict new data values, a process known as inferencing.
-
The goal is to leverage data to create models that can be used in real-world applications to make predictions.
-
Training Data:
- Observations consist of:
- Features: The attributes or characteristics of the thing being observed.
- Label: The known value you want to predict.
- Observations consist of:
-
Mathematical Representation:
- Features are represented by x (often as a vector of multiple values, e.g., [x_1, x_2, x_3, ...].
- The label is denoted as y.
-
Applying the Algorithm:
- An algorithm is used to determine the relationship between features (x) and the label (y).
- The algorithm generalizes this relationship as a function (f) that maps x to y:
y = f(x)
-
Inferencing:
- After training, the model can be used for inferencing:
- You provide x (feature values) as input, and the model predicts y (the label).
- The output is denoted as ŷ (y-hat), representing a prediction based on the learned function, not an observed value.
- After training, the model can be used for inferencing: