This repository contains the code and resources for building a Stack Overflow tag predictor using machine learning techniques. The goal of this project is to predict relevant tags for Stack Overflow questions based on their content.
- About the Project
- Dataset
- Preprocessing
- Vectorization
- Performance & Web scrapping
- Visualization
- Usage
Stack Overflow is a popular platform for developers to ask and answer technical questions. However, tagging questions with relevant keywords is crucial for efficient searching and categorization. This project aims to automate the process of tagging Stack Overflow questions using machine learning. Currently the attempt is made to predict the top 5 tags from the dataset.
The training dataset used in this project was obtained from Kaggle and consists of questions along with their associated tags. Preprocessing steps include lemmatization and stop word removal.
- Lemmatization: The text data is lemmatized to reduce words to their base or dictionary form.
- Stop Word Removal: Common stop words are removed from the text data to improve model performance.
Two vectorization methods are used in this project:
-
TF-IDF (Term Frequency-Inverse Document Frequency):
Models: Logistic Regression, Naive Bayes, Support Vector Machine (SVM), Artificial Neural Network (ANN)
-
Word2Vec:
Models: Logistic Regression, Support Vector Machine (SVM), Recurrent Neural Network (RNN)
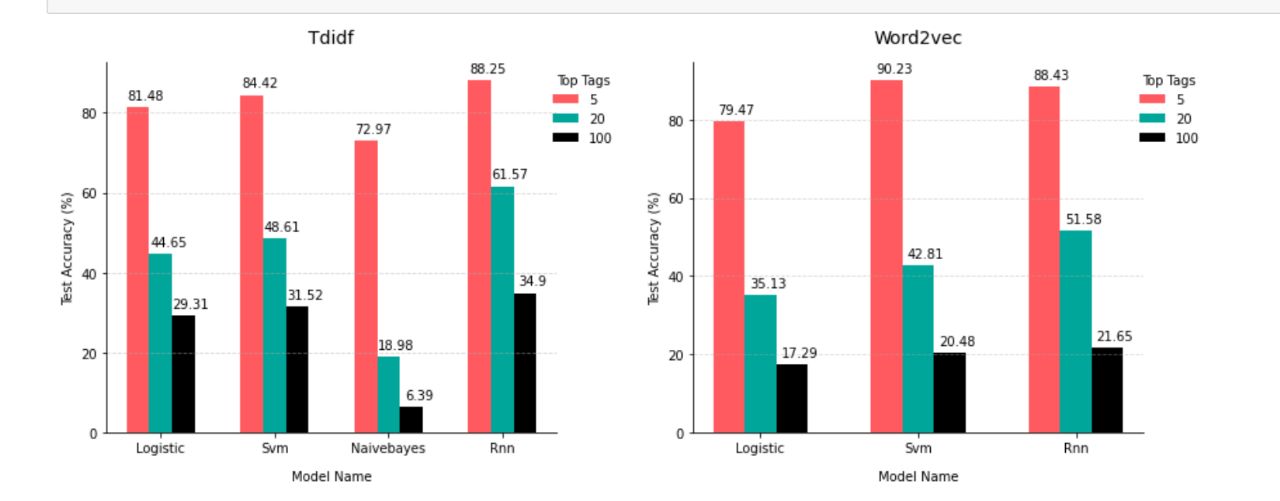
The performance of the models was evaluated using metrics such as accuracy, precision, recall, and F1-score. On the test dataset, the SVM model with Word2Vec achieved the highest accuracy of 90.23%, followed by RNN with 88.43%.
To further evaluate the model's performance, a new test dataset was created by web scraping Stack Overflow questions. The models were tested on this new dataset, and the results showed that the SVM model achieved an accuracy of approximately 92%, while the RNN model achieved an accuracy of 91%.
-
Clone the repository:
git clone https://github.com/YourUsername/StackOverflow-Tag-Predictor.git
-
Get the dataset. (Link)
-
Run the model training and evaluation scripts.
-
Predict tags for new Stack Overflow questions using the trained model.
- Thanks to the sklearn library for the models.
- Kaggle for the dataset of questions and tags.
- Stack Overflow for permitting data scraping to access its invaluable question dataset.