Weekend Task - String Programs - TF-IDF #40
Replies: 21 comments
-
|
Beta Was this translation helpful? Give feedback.
-
package week4;
import java.io.*;
import java.lang.reflect.Array;
import java.text.DecimalFormat;
import java.util.*;
public class TFandIDFtextAnalysis {
public static void writeInFile(String s1, String s2, String s3, String s4,String file1, String file2, String file3, String file4) {
try (FileWriter fw1 = new FileWriter(file1);FileWriter fw2 = new FileWriter(file2);
FileWriter fw3 = new FileWriter(file3);FileWriter fw4 = new FileWriter(file4);){
fw1.write(s1);
fw2.write(s2);
fw3.write(s3);
fw4.write(s4);
} catch (IOException e) {
System.out.println(e.getMessage());
}
}
public static String[] readFromFile(String file1, String file2, String file3, String file4) {
try(FileReader fr1 = new FileReader(file1);
FileReader fr2 = new FileReader(file2);
FileReader fr3 = new FileReader(file3);
FileReader fr4 = new FileReader(file4);) {
String[] res = new String[4];
int i = 0;
for(String s : res)
res[i++] = "";
int ch;
while ((ch = fr1.read()) != -1)
res[0] += (char) ch;
while ((ch = fr2.read()) != -1)
res[1] += (char) ch;
while ((ch = fr3.read()) != -1)
res[2] += (char) ch;
while ((ch = fr4.read()) != -1)
res[3] += (char) ch;
return res;
}
catch (IOException e) {
System.out.println(e.getMessage());
return new String[0];
}
}
public static List<String> filterString(String s) {
String[] strArr = s.replaceAll("\\p{Punct}", "").toLowerCase().split("\\s");
strArr = removeStopWord(strArr);
return Arrays.asList(strArr);
}
public static String[] removeStopWord(String[] s) {
String stopWords = "i, me, my, myself, we, our, ours, ourselves, you, you’re, you’ve, you’ll, you’d, your, yours, yourself, yourselves, he, most, other, some, such, no, nor, not, only, own, same, so, then, too, very, s, t, can, will, just, don, don’t, should, should’ve, now, d, ll, m, o, re, ve, y, ain, aren’t, could, couldn’t, didn’t, didn’t, the, a, by, is, of";
String[] arr = stopWords.split(", ");
for (String str1 : arr) {
for (String str2 : s)
if (str2.equals(str1)) {
s = remove(s, str1);
}
}
return s;
}
public static String[] remove(String[] array, String element) {
if (array.length > 0) {
int index = -1;
for (int i = 0; i < array.length; i++) {
if (array[i].equals(element)) {
index = i;
break;
}
}
if (index >= 0) {
String[] copy = (String[]) Array.newInstance(array.getClass()
.getComponentType(), array.length - 1);
if (copy.length > 0) {
System.arraycopy(array, 0, copy, 0, index);
System.arraycopy(array, index + 1, copy, index, copy.length - index);
}
return copy;
}
}
return array;
}
public static Set<String> getCommonWords(List<List<String>> input) {
Set<String> res = new HashSet<>();
for(List<String> s : input) {
for (String x : s)
res.add(x);
}
return res;
}
public static double[][] wordFreqTable(Set<String> setOfCommonWords, List<List<String>> listofString) {
double[][] tf = new double[4][setOfCommonWords.size()];
List<String> commonWords = new ArrayList<>();
commonWords.addAll(setOfCommonWords);
String[][] strings = new String[4][setOfCommonWords.size()];
int i = 0, j = 0;
for (List<String> line : listofString)
strings[i++] = line.toArray(new String[0]);
for (i = 0; i < 4; i++)
for (j = 0; j < setOfCommonWords.size(); j++)
if (Arrays.asList(strings[i]).contains(commonWords.get(j)))
tf[i][j]++;
return tf;
}
public static double[][] normalizedTFtable(double[][] tf, int row, int col) {
double[] sumRow = new double[row];
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
sumRow[i] = sumRow[i] + tf[i][j];
}
}
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
tf[i][j] /= sumRow[i];
}
}
return tf;
}
public static double[] getIDFandDisplayIDF(double[][] tfAndIdf, int row, int col,Set<String> setOfCommonWords){
double[] IDF = new double[col];
for (int i = 0; i < col; i++) {
for (int j = 0; j < row; j++) {
IDF[i] += tfAndIdf[j][i];
}
}
DecimalFormat df = new DecimalFormat("#0.0000");
System.out.print("IDF\t");
for (String words : setOfCommonWords) {
System.out.print(words + "\t");
}
System.out.print("\n\t");
for (int i = 0; i < col ; i++) {
IDF[i] = Math.log10(row / IDF[i]);
System.out.print(df.format(IDF[i]) + "\t");
}
System.out.println("\n");
return IDF;
}
public static void displayTable(double[][] tf, int n, int m, Set<String> setOfCommonWords) {
DecimalFormat df = new DecimalFormat("#0.00000");
System.out.print("D/W\t");
for (String words : setOfCommonWords) {
if(words.length() > 7)
System.out.print(words + "\t");
else
System.out.print(words + "\t\t");
}
System.out.println();
for (int i = 0; i < n; i++) {
System.out.print("D " + (i + 1) + ":\t");
for (int j = 0; j < m; j++) {
System.out.print(df.format(tf[i][j]) + "\t\t");
}
System.out.println();
}
}
public static double[][] getTFandIDF(double[][] tfAndIdf, double[] idf, int row, int col) {
for (int j = 0; j < col; j++) {
for (int i = 0; i < row; i++)
tfAndIdf[i][j] *= idf[j];
}
return tfAndIdf;
}
public static void main(String[] args) {
String s1 = "My name is Groot.";
String s2 = "My ship is a Starship.";
String s3 = "The ship I drive, is, a Starship Benatar.";
String s4 = "My ship is a Benatar model of Starship !!";
String file1 = "week4/file1.txt";
String file2 = "week4/file2.txt";
String file3 = "week4/file3.txt";
String file4 = "week4/file4.txt";
/**
* Write in File:
*/
writeInFile(s1,s2,s3,s4,file1,file2,file3,file4);
/**
* Read from files:
*/
String[] stotal = readFromFile(file1,file2,file3,file4);
/**
* Filter the strings:
*/
List<List<String>> filteredString = new ArrayList<>();
for(String s : stotal)
filteredString.add(filterString(s));
/**
* Finding commom words:
*/
Set<String> setOfCommonWords = new HashSet<>();
setOfCommonWords = getCommonWords(filteredString);
/**
* Freqency of occurrences:
*/
double[][] tf = new double[4][setOfCommonWords.size()];
tf = wordFreqTable(setOfCommonWords, filteredString);
System.out.println("\n ---- Count table ---- \n");
displayTable(tf, 4, setOfCommonWords.size(), setOfCommonWords);
/**
* IDF and Normalize this data across the rows to sum it to one for each document to generate our final TF table.
*/
System.out.println("\n ---- IDF Table -----\n");
double[] idf = new double[setOfCommonWords.size()];
idf = getIDFandDisplayIDF(tf, 4, setOfCommonWords.size(),setOfCommonWords);
normalizedTFtable(tf, 4, setOfCommonWords.size());
System.out.println("\n --- Normalized TF table ---- \n");
displayTable(tf, 4, setOfCommonWords.size(), setOfCommonWords);
/**
* FINAL TS AND IDF table:
*/
getTFandIDF(tf, idf, 4, setOfCommonWords.size());
System.out.println("\n------ FINAL TF and IDF Table: ------\n");
displayTable(tf, 4, setOfCommonWords.size(), setOfCommonWords);
}
} |
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
import java.io.IOException; public class DocsOperation { } |
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
import java.util.; class StringsOperations } } |
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
import java.io.*;
import java.util.*;
import java.lang.reflect.Array;
import java.text.DecimalFormat;
public class TFandIDFAnalysis {
public static void writeInFile(String s1, String s2, String s3, String s4,String file1, String file2, String file3, String file4) {
try (FileWriter fw1 = new FileWriter(file1);FileWriter fw2 = new FileWriter(file2);
FileWriter fw3 = new FileWriter(file3);FileWriter fw4 = new FileWriter(file4);){
fw1.write(s1);fw2.write(s2);fw3.write(s3);fw4.write(s4);
} catch (IOException e) {
e.printStackTrace();
}
}
public static String[] readFromFile(String file1, String file2, String file3, String file4) {
try(FileReader fr1 = new FileReader(file1);FileReader fr2 = new FileReader(file2);
FileReader fr3 = new FileReader(file3);FileReader fr4 = new FileReader(file4);) {
String[] res = new String[4];
int i = 0;
for(String s : res)
res[i++] = "";
int ch;
while ((ch = fr1.read()) != -1) res[0] += (char) ch;
while ((ch = fr2.read()) != -1) res[1] += (char) ch;
while ((ch = fr3.read()) != -1) res[2] += (char) ch;
while ((ch = fr4.read()) != -1) res[3] += (char) ch;
return res;
}
catch (IOException e) {
e.printStackTrace();
return new String[0];
}
}
public static List<String> filterString(String s) {
String[] strArr = s.replaceAll("\\p{Punct}", "").toLowerCase().split("\\s");
strArr = removeString(strArr);
return Arrays.asList(strArr);
}
public static String[] removeString(String[] s) {
String stopWords = "i, me, my, myself, we, you, you’re, you’ve, you’ll, you’d, your, yours, yourself, yourselves, he, most, other, some, such, no, nor, not, only, own, same, so, then, too, very, s, t, can, will, just, don, don’t, should, should’ve, now, d, ll, m, o, re, ve, y, ain, aren’t, could, couldn’t, didn’t, didn’t, the, a, by, is, of";
String[] arr = stopWords.split(", ");
for (String str1 : arr) {
for (String str2 : s)
if (str2.equals(str1)) {
s = remove(s, str1);
}
}
return s;
}
public static String[] remove(String[] array, String ele) {
if (array.length > 0) {
int idx = -1;
for (int i = 0; i < array.length; i++) {
if (array[i].equals(ele)) {
idx = i;
break;
}
}
if (idx >= 0) {
String[] copy = (String[]) Array.newInstance(array.getClass()
.getComponentType(), array.length - 1);
if (copy.length > 0) {
System.arraycopy(array, 0, copy, 0, idx);
System.arraycopy(array, idx + 1, copy, idx, copy.length - idx);
}
return copy;
}
}
return array;
}
public static Set<String> getCommWords(List<List<String>> input) {
Set<String> res = new HashSet<>();
for(List<String> s : input) {
for (String x : s)
res.add(x);
}
return res;
}
public static double[][] freqArray(Set<String> setOfCommonWords, List<List<String>> listofString) {
double[][] tf = new double[4][setOfCommonWords.size()];
List<String> commonWords = new ArrayList<>();
commonWords.addAll(setOfCommonWords);
String[][] strings = new String[4][setOfCommonWords.size()];
int i = 0, j = 0;
for (List<String> line : listofString)
strings[i++] = line.toArray(new String[0]);
for (i = 0; i < 4; i++)
for (j = 0; j < setOfCommonWords.size(); j++)
if (Arrays.asList(strings[i]).contains(commonWords.get(j)))
tf[i][j]++;
return tf;
}
public static double[][] normalizedTFtable(double[][] tf, int row, int col) {
double[] sumRow = new double[row];
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
sumRow[i] = sumRow[i] + tf[i][j];
}
}
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
tf[i][j] /= sumRow[i];
}
}
return tf;
}
public static double[] getIDFandDisplayIDF(double[][] tfAndIdf, int row, int col,Set<String> setOfCommonWords){
double[] IDF = new double[col];
for (int i = 0; i < col; i++) {
for (int j = 0; j < row; j++)
IDF[i] += tfAndIdf[j][i];
}
DecimalFormat df = new DecimalFormat("#0.0000");
for (String words : setOfCommonWords)
System.out.print(words + "\t");
for (int i = 0; i < col ; i++) {
IDF[i] = Math.log10(row / IDF[i]);
System.out.print(df.format(IDF[i]) + "\t");
}
System.out.println("\n");
return IDF;
}
public static void displayTable(double[][] tf, int n, int m, Set<String> setOfCommonWords) {
DecimalFormat df = new DecimalFormat("#0.00000");
System.out.print("D/W\t");
for (String words : setOfCommonWords) {
if(words.length() > 7)
System.out.print(words + "\t");
else
System.out.print(words + "\t\t");
}
System.out.println();
for (int i = 0; i < n; i++) {
System.out.print("D " + (i + 1) + ":\t");
for (int j = 0; j < m; j++)
System.out.print(df.format(tf[i][j]) + "\t\t");
System.out.println();
}
}
public static double[][] getTFandIDF(double[][] tfAndIdf, double[] idf, int row, int col) {
for (int j = 0; j < col; j++) {
for (int i = 0; i < row; i++)
tfAndIdf[i][j] *= idf[j];
}
return tfAndIdf;
}
public static void main(String[] args) {
String s1 = "My name is Groot.",s2 = "My ship is a Starship.",s3 = "The ship I drive, is, a Starship Benatar.",s4 = "My ship is a Benatar model of Starship !!";
String file1 = "week4/file1.txt",file2 = "week4/file2.txt",file3 = "week4/file3.txt",file4 = "week4/file4.txt";
writeInFile(s1,s2,s3,s4,file1,file2,file3,file4);
String[] stotal = readFromFile(file1,file2,file3,file4);
List<List<String>> filteredString = new ArrayList<>();
for(String s : stotal)
filteredString.add(filterString(s));
/**
* Finding commom words:
*/
Set<String> setOfCommonWords = new HashSet<>();
setOfCommonWords = getCommWords(filteredString);
/**
* Freqency of occurrences:
*/
double[][] tf = new double[4][setOfCommonWords.size()];
tf = freqArray(setOfCommonWords, filteredString);
displayTable(tf, 4, setOfCommonWords.size(), setOfCommonWords);
double[] idf = new double[setOfCommonWords.size()];
idf = getIDFandDisplayIDF(tf, 4, setOfCommonWords.size(),setOfCommonWords);
normalizedTFtable(tf, 4, setOfCommonWords.size());
System.out.println("\n --- Normalized TF table ---- \n");
displayTable(tf, 4, setOfCommonWords.size(), setOfCommonWords);
/**
* FINAL TS AND IDF table:
*/
getTFandIDF(tf, idf, 4, setOfCommonWords.size());
System.out.println("\n------ FINAL TF and IDF Table: ------\n");
displayTable(tf, 4, setOfCommonWords.size(), setOfCommonWords);
}
} |
Beta Was this translation helpful? Give feedback.
-
import java.util.*;
import java.io.File;
import java.io.IOException;
public class Tfidf {
public static String removePunc(String str) {
str = str.replaceAll("[^a-zA-Z0-9\\s]", "");
return str;
}
public static String loweringCase(String str) {
str = str.toLowerCase();
return str;
}
public static String[] tokenization(String str) {
return str.split(" ");
}
public static StringBuilder stopWord(String[] newStr) {
String stopWord = "i, a, is, me, by, my, of, myself, we, our, ours, ourselves, you, you’re, you’ve, you’ll, you’d, your, yours, yourself, yourselves, he, most, other, some, such, no, nor, not, only, own, same, so, then, too, very, s, t, can, will, just, don, don’t, should, should’ve, now, d, ll, m, o, re, ve, y, ain, aren’t, could, couldn’t, didn’t, didn’t";
StringBuilder sb = new StringBuilder();
for (String word : newStr) {
if (!stopWord.contains(word)) {
sb.append(word + " ");
}
}
return sb;
}
public static void uniqueWords(String[] s) {
Set<String> uniqueWords = new HashSet<>();
for (String str : s)
uniqueWords.add(str);
matCreation(uniqueWords);
}
public static void matCreation(Set<String> uniqueWords) {
String[][] mat = new String[5][uniqueWords.size() + 1];
mat[0][0] = "Document";
List<String> list = new ArrayList<>(uniqueWords);
for (int i = 1; i < 4; i++) {
for (int j = 0; j <= uniqueWords.size(); j++) {
if (j == 0 && i != 0) {
int x = i + 1;
mat[i][j] = "file" + x;
} else if (i == 0 && j != 0) {
mat[i][j] = list.get(i);
// for (String str : s) {
// mat[i][j] = str;
// }
} else
mat[i][j] = "0";
}
}
for (int i = 0; i < 4; i++) {
for (int j = 0; j <= uniqueWords.size(); j++) {
System.out.print(mat[i][j] + " ");
}
System.out.println();
}
}
// public static void tf()
public static void idf(String[] allWords, Set<String> unique) {
for (String s : unique) {
int count = 0;
for (String word : allWords) {
if (s.equals(word)) {
count++;
}
}
double idf = 0;
idf = Math.round((Math.log10(4.0 / count) * 1000.00)) / (double) 1000;
System.out.println(s + " " + idf);
}
}
public static void main(String[] args) throws IOException {
String[] files = { "src/File1.txt", "src/File2.txt", "src/File3.txt", "src/File4.txt" };
StringBuilder newSb = new StringBuilder();
for (String file : files) {
File obj = new File(file);
Scanner reader = new Scanner(obj);
while (reader.hasNextLine()) {
String line = reader.nextLine();
newSb.append(stopWord(tokenization(loweringCase(removePunc(line)))));
}
reader.close();
}
String[] words = newSb.toString().split(" ");
uniqueWords(words);
}
} |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
TF-IDF
Term Frequency - Inverse Document Frequency
TF-IDF stands for Term Frequency Inverse Document Frequency and it is a measure of how frequently a word appears in a series of documents. It is a very simple concept both in understanding and implementation. Its use cases include; Weighting of NLP tasks for text classification, error detection in writing, document ranking, search engine/information retrieval, and keyword matching.
There are two elements in TF-IDF:
Like other types of data, before doing any process It is important to remove or transform your text into a form that is utilizable and more realistic. For instance, stopwords and punctuation marks do not add value to the context of the document and hence would cause issues with determining the true similarity of documents. If two documents have comas, questions, and the pronoun “I” occurring at the same frequency then would these two documents be similar?
In-text processing we do this by:
Steps to clean the data
Punctuation Removal:

In this step, all the punctuations from the text are removed. string library of Python contains some pre-defined list of punctuations such as ‘!”#$%&'()*+,-./:;?@[]^_`{|}~’
Example:
Lowering the case

It is one of the most common preprocessing steps where the text is converted into the same case preferably lower case.
Examples:
Tokenization

In this step, the text is split into smaller units. We can use either sentence tokenization or word tokenization based on our problem statement. For our case, we'll tokenize into words.
Examples:
Stop word removal

Stopwords are the commonly used words and are removed from the text as they do not add any value to the analysis. These words carry less or no meaning. A list of words that are considered stopwords for the English language are :
[i, me, my, myself, we, our, ours, ourselves, you, you’re, you’ve, you’ll, you’d, your, yours, yourself, yourselves, he, most, other, some, such, no, nor, not, only, own, same, so, then, too, very, s, t, can, will, just, don, don’t, should, should’ve, now, d, ll, m, o, re, ve, y, ain, aren’t, could, couldn’t, didn’t, didn’t]Examples:
Calculation
After all the text processing steps are performed, the final acquired data is converted into the numeric form using TF-IDF.
Calculating TF

Calculating IDF

Calculating TF-IDF

A Step-by-Step Example
Let's look at an actual example of this, lets say we have the following documents:

As we discussed earlier, we need to perform some pre-processing on the data. In our case we did the following; removed stop words, removed punctuation marks, and converted all the words to lowercase.
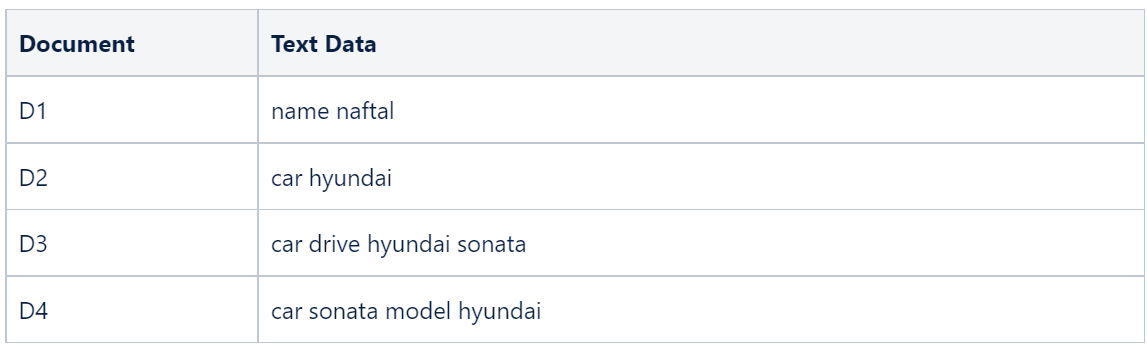
Then we do tokenization, following which the unique words that we have in all documents are name, naftal, car, hyundai, drive, sonata, and model. Let's identify the frequency of occurrence in the various documents.
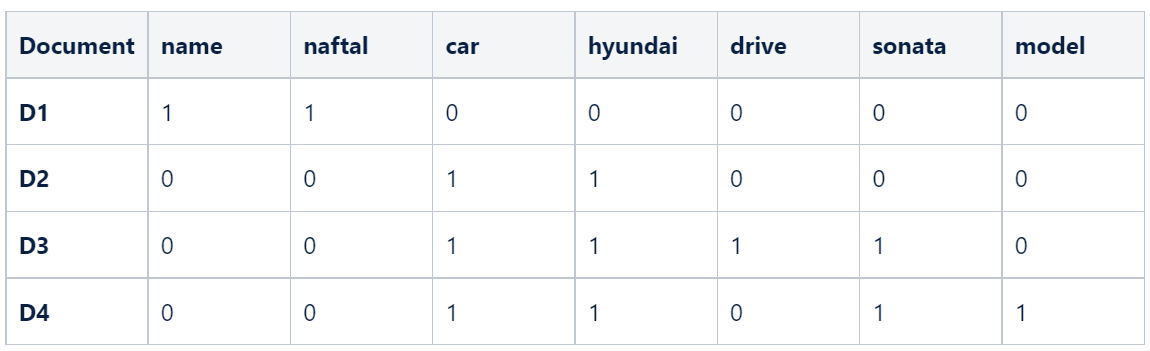
Let's normalize this data across the rows to sum it to one for each document to generate our final TF table.
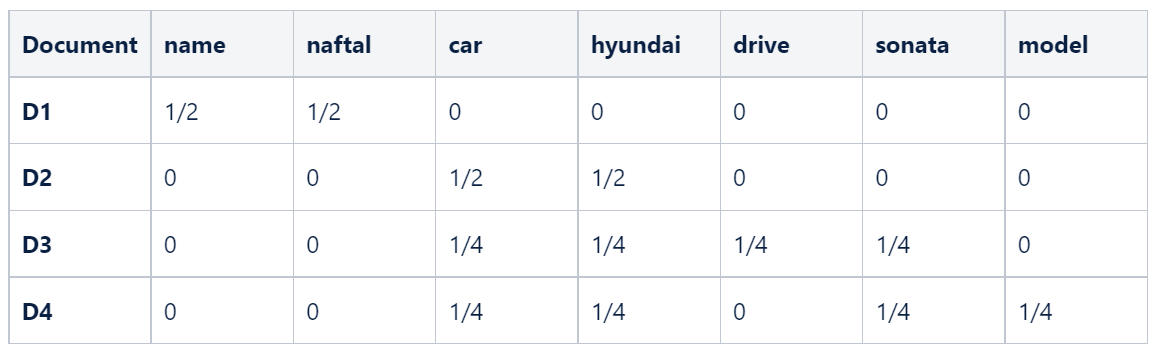
Now let's calculate the IDF values, remember all we need to do for this is find the log of the ratio of the number of documents versus the total number of documents where that word occurs. Let's take the case of the word “name”. It appears once in document one and not in any of the other 3 documents. Its IDF will be:

The computed IDF values for the words are as follows:

The finalized TF-IDF table is as follows:
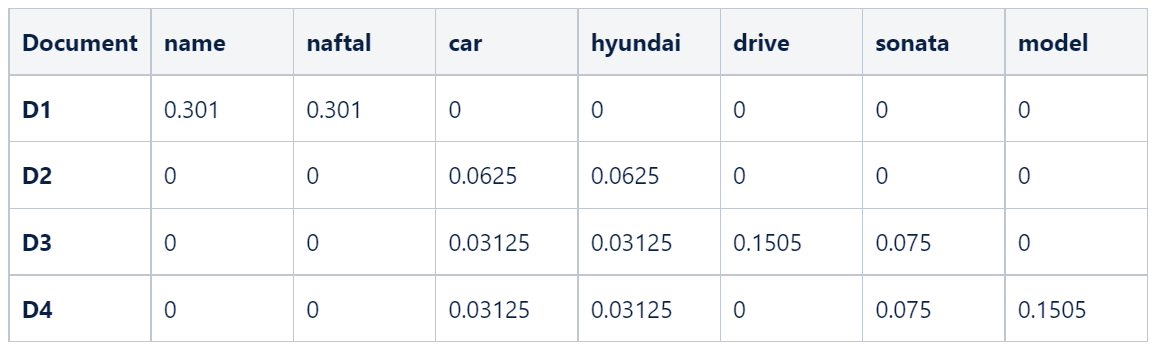
Note that the table above represents what we expected, more frequently occurring words have higher TF-IDF values for the documents in which they occur.
Task
Given four text files, write a program to construct the TF-IDF matrix for unique significant words.
First, read the text from the files programmatically, pre-process the text as per the aforementioned steps, and then construct and print the TF-IDF matrix.
The contents of the four text files are given as follows:
file1.txt
file2.txt
file3.txt
file4.txt
Beta Was this translation helpful? Give feedback.
All reactions