{kind=link}
¿Qué es un audio o señal de audio?
El audio consiste en la tensión eléctrica o magnética proporcional a un sonido, y éste se genera a través de transductores (Es decir, aquellos elementos que transforman una magnitud física en una señal eléctrica). Estos transductores pueden ser, por ejemplo, los micrófonos.
Para poder utilizar los audios existen representaciones visuales como:
- Forma de onda
- Espectro
- Espectrograma
De estas 3 representaciones la más completa es el espectrograma ya que permite identificar las diferentes variaciones de la frecuencia y la intensidad del sonido a lo largo de un periodo de tiempo.
Cada eje de un espectrograma se visualiza de diferentes formas:
- El tiempo está representado por el eje horizontal.
- El eje vertical muestra la frecuencia.
- El color que marque el espectrograma ayuda a identificar la intensidad del sonido.
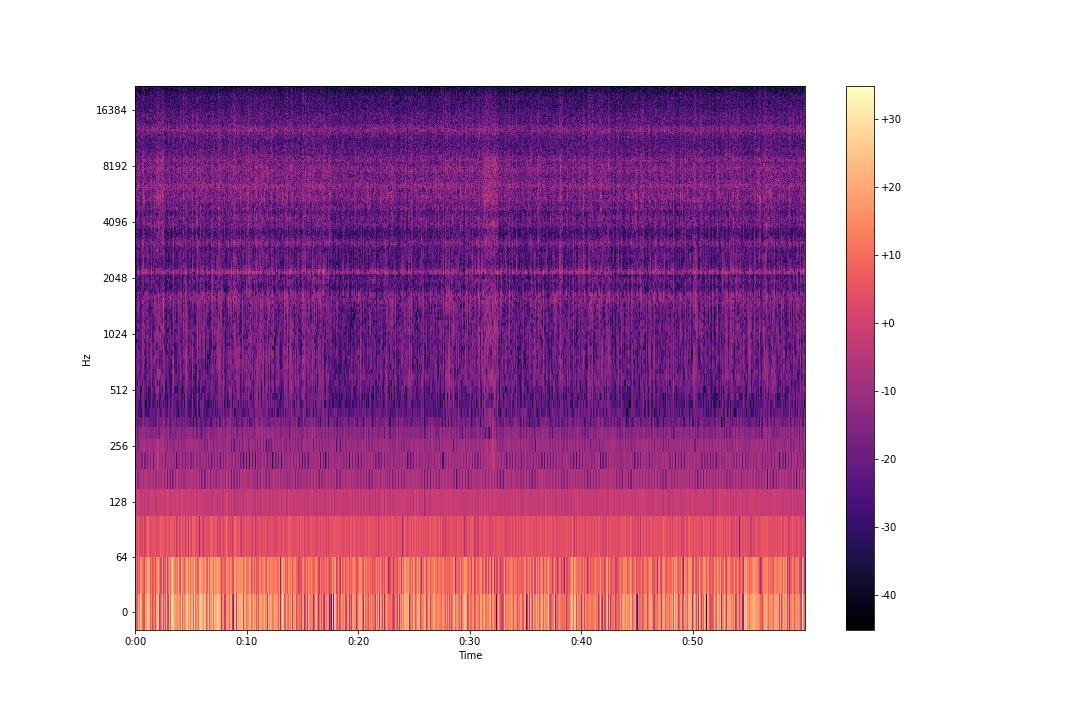
Dado que en la actualidad se puede grabar, obtener audio de todo tipo de cosas (animales, maquinaria, personas, etc.) de manera "sencilla" y almacenar en gran cantidad, se pueden tratar distintos problemas, ideas relacionadas con el audio mediante la creación de modelos relacionados con la respectiva problemática.
Por ejemplo:
- Separación de fuentes: Separación vocal de una fuente de entrada de audio.
- Reconocimiento automático de voz: Transcribir automáticamente audio en tiempo real o pregrabado a texto.
- Clasificador de géneros musicales: Reconocimiento y etiquetado automático de géneros musicales.
En el siguiente ejercicio vamos a abordar el problema de un cliente relacionado con el monitoreo de torres de alta tensión.
Las torres de alta tensión por el tiempo y distintos factores generan un sonido característico llamado efecto corona. El efecto corona es un fenómeno que consiste en una descarga eléctrica debido a la ionización del fluido que circunda a un conductor energizado. El ruido provocado consiste en un zumbido constante tipo interferencia de radio provocado por el movimiento de los iones.
Lo requerido era que mediante el audio generado por una torre poder clasificar si iba a fallar o no.
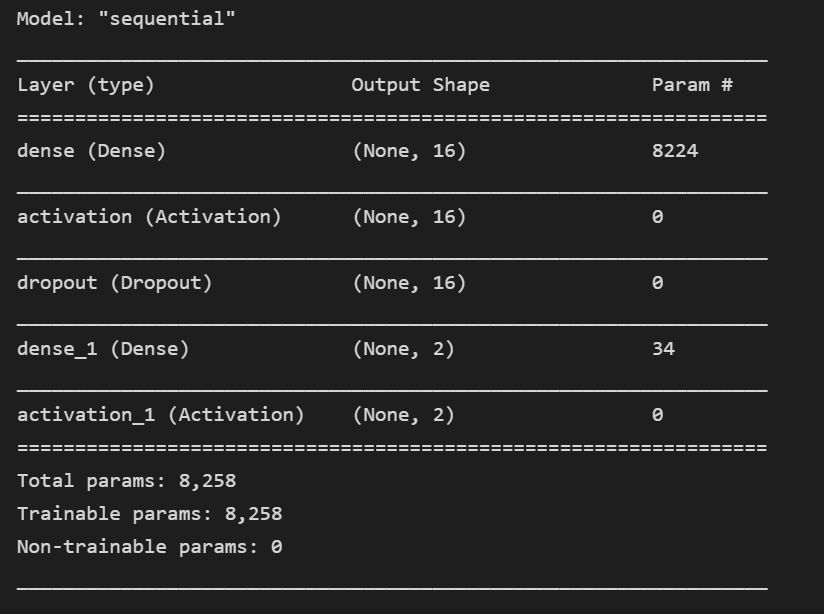
Lo que se hizo para resolver el problema fue utilizar el modelo de clasificación Multilayer Perceptron haciendo uso del espectrograma para clasificar si una torre iba a fallar o no.
Se proporcionaron un total de 198 audios de formato wav con una duración de 30 a 60 segundos y sample rate de 44100 Hz, de los cuales hay 2 tipos
- Audio Normal: Se le asigno la etiqueta 0
- Audio Anomalo: Se le asigno la etiqueta 1
A continuación se muestra la arquitectura del ciclo de vida de un modelo de machine learning de un proyecto de análisis de audio.

Características genéricas que se extrajeron a los audios proporcionados
- File name
- Channels: Number of channels (1 for Mono, 2 for Stereo)
- Sample width: Number of bytes in each sample (1 for 8 bit, 2 for 16 bit, 4 for 32 bit)
- Frame rate/Sample rate: Number of samples per second. Common values are 44100, 48000, 22050, 24000, 12000
- Frame width: Number of bytes for each frame. A frame contains a sample for each channel. frame width = channels * sample width
- Length: Duration in seconds
- Frame count: Number of frames in milliseconds
- Intensity: The loudness in dBFS (db relative to the maximum possible loudness)
- Frame size: Los valores más habituales son: 512, 1024, 2048, 8192.
- Hop length: Los valores más habituales son: 256, 512, 1024, 2048, 4096.
- Number of frames: El número de frames es igual a lo siguiente: ((samples - frame size) / hop length) + 1
- Window: Existen varias funciones de ventana como: Hann, Hamming, flattop, boxcar, triang, entre otras. Hann funciona bien el 95% de los casos.
Se escogieron los siguientes parámetros:
- Frame size = 1024
- Hop lenght = 512
- Window = Hann
El número de frames va a depender del número de samples que posea el audio.
Multilayer Perceptron es una red neuronal feedforward , lo que significa que los datos se transmiten desde la capa de entrada a la capa de salida en la dirección de avance.
Además aprende la relación entre datos lineales y no lineales.
Para el entrenamiento del modelo se utilizó el 75% de los datos.
Los hiperparametros son los siguientes:
- Batch size = 25
- Hidden units = 16
- dropout = 0.3
- epochs = 50
Las métricas escogidas son:
- accuracy: Es la fracción de predicciones que el modelo realizó correctamente
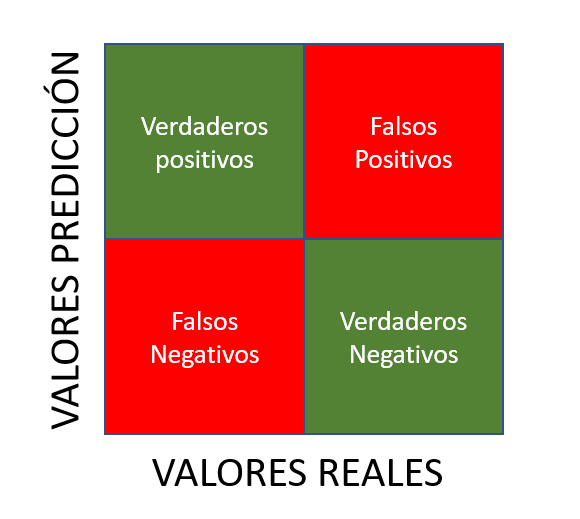
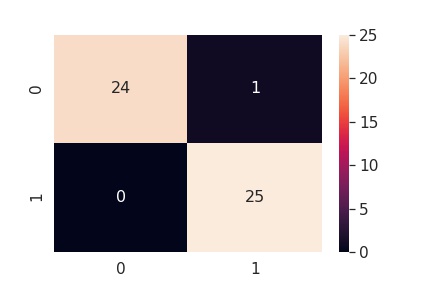
- matriz de confusión: Es una herramienta que permite visualizar el desempeño del modelo, nos permite ver cuántos aciertos y errores hemos obtenido.
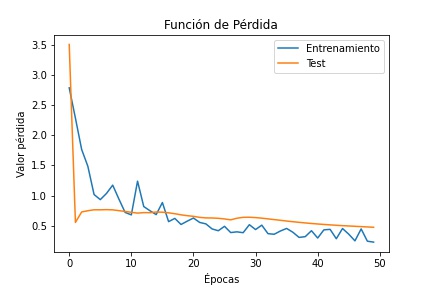
La función de perdida, es una función que evalúa la desviación entre las predicciones realizadas por la red neuronal y los valores reales de las observaciones utilizadas durante el aprendizaje. Cuanto menor es el resultado de esta función, más eficiente es la red neuronal.
La función de perdida que se utilizo es la más utilizada para problemas de clasificación binaria, 'binary cross entropy', es el promedio negativo del logaritmo de las probabilidades predichas corregidas. En otras palabras, compara cada una de las probabilidades predichas con la salida de la clase real, que puede ser 0 o 1. Luego calcula la puntuación que penaliza las probabilidades en función de la distancia desde el valor esperado. Eso significa qué tan cerca o lejos del valor real.
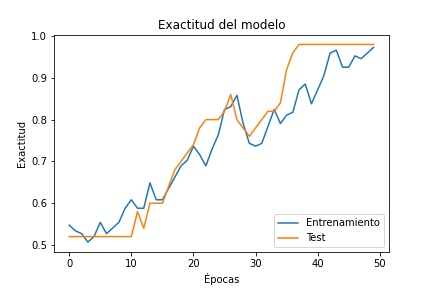
En el entrenamiento y en el testeo se obtuvo como resultado 97.30% y 98% respectivamente.
En el entrenamiento y en el testeo se obtuvo como resultado 0.2297 y 0.4756 respectivamente.
- Se guardan las rutas y los nombres de los audios para poder extraer los metadatos y obtener los espectrogramas.
- Se obtienen los metadatos de los audios.
- Se escogen los parámetros del preprocesamiento (frame size = 1024, hop length = 512, window = Hann)
- Se cargan los audios
- Se calcula la Short-time Fourier transform (stft)
- Por medio de la stft se obtiene el espectrograma, el cual es una matriz de tamaño m x n donde: m = (frame size / 2) + 1 ; n = number of frames.
- Se calcula la media de cada fila del espectrograma y se guarda como "espectrograma scaled", la cual se utiliza para entrenar el modelo.
- Se dividen los datos en entrenamiento y testeo, para el testeo se utiliza un 25%.
- Se utiliza el modelo de clasificación Multilayer Perceptron.
- Se grafica la exactitud (accuracy), la función de perdida y la matriz de confusión.