问题背景
算法本身很简单,G6 已有的实现:

目前已有WebGL 版本:https://nblintao.github.io/ParaGraphL/
在该实现中,由于 WebGL 不支持 ComputeShader,因此只能将节点位置计算放在 FragmentShader 中进行(常见的 WebGL GPGPU 实现),值得一提的是依然采用 sigma(SVG)渲染节点。
另有 Unity 版本:https://github.com/l-l/UnityNetworkGraph/blob/master/Assets/Shaders/GraphCS.compute。
我们希望在 WebGPU 版本中,渲染和计算都在 GPU 侧完成。为了达到最佳的渲染和计算效率:
- 节点位置计算在 ComputeShader 中进行。
- 考虑内存友好的布局方式组织节点数据。
其中算法的迁移(JS -> GLSL)本身并不复杂,值得一提的是第二点。
内存友好的布局方式
AoS vs SoA
按照 OOP 常规的编程习惯,很容易使用 AoS(Array-of-Structures),
在处理一组对象时,如果只需要对象的部分属性,就会造成 CPU 缓存的浪费。例如只需要 name 属性,也必须读入一整行:
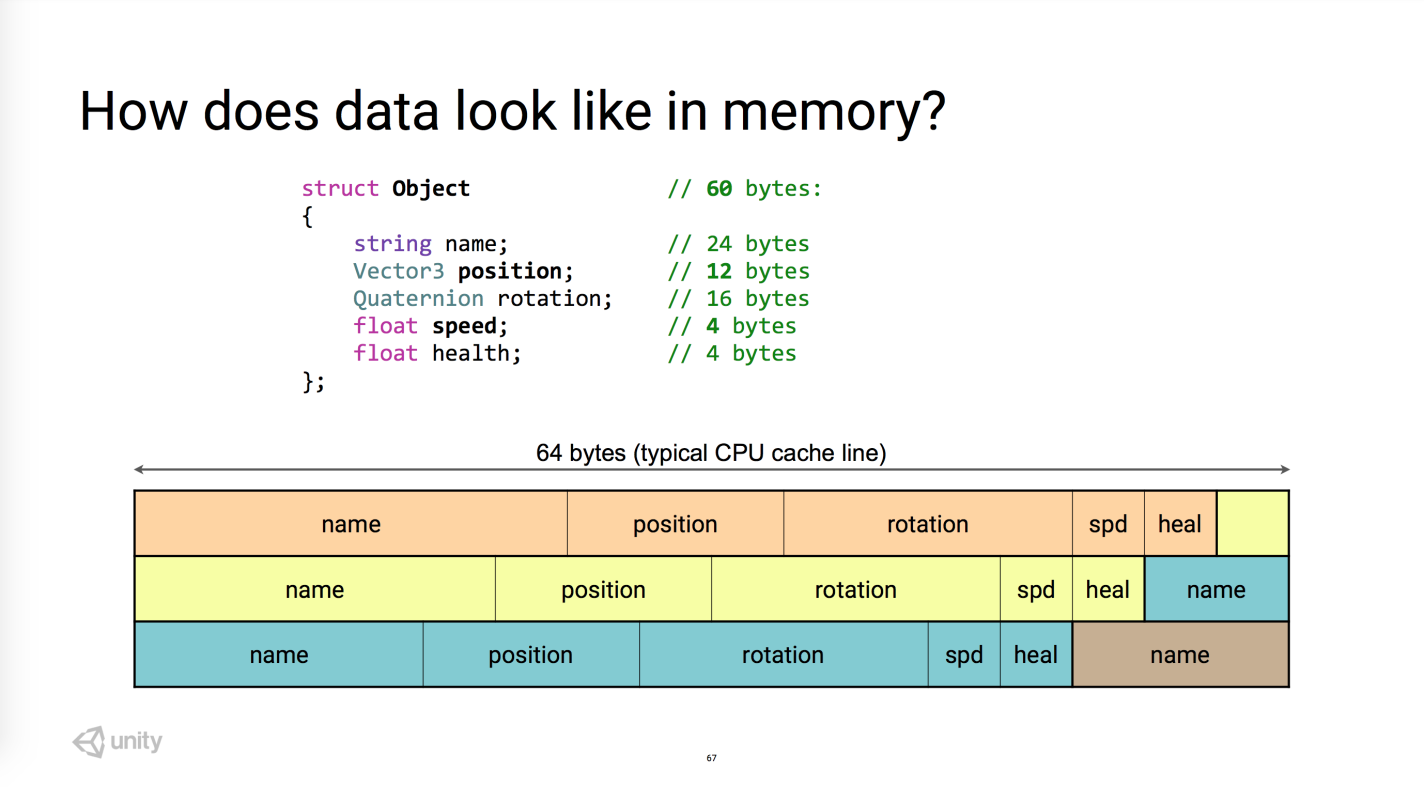
而 SoA 对于 CPU 缓存更友好,读取第一个对象的某个属性时顺便把后续几个也一并读入缓存了,尤其在大量遍历对象的场景:

因此我们在引擎设计时也使用了 ECS 架构,同样基于以上考虑。
回到该算法本身,我们也可以使用类似思路组织 Nodes 和 Edges,充分考虑 GPU 内存的顺序读性能。
组织 Nodes & Edges 数组
在 JS 实现(G6)中,并不需要考虑连续读的内存友好性:https://github.com/antvis/G6/blob/master/src/layout/fruchterman.ts#L236-L237:
// 计算吸引力
edges.forEach(e => {
if (!e.source || !e.target) return;
const uIndex = this.nodeIdxMap[e.source];
const vIndex = this.nodeIdxMap[e.target];在 https://nblintao.github.io/ParaGraphL/ 的实现中,就充分考虑到了 GPU 内存的顺序读,同时尽可能压缩(例如每一个 Edge 的 rgba 分量都存储了临接节点的 index):

以斥力计算(G6 的实现)为例,需要遍历除自身外的全部其他节点,这全部都是顺序读操作。
同样的,在计算吸引力时,遍历一个节点的所有边也都是顺序读。
随机读只会出现在获取端点坐标时才会出现。
后续优化
Offscreen Canvas
看到目前 G6 中已有将布局计算放在 WebWorker 中进行的实践,实际上渲染也可以,完成主线程与渲染线程的分离,这样主线程处理交互和其他重计算任务就有了更多空间,这便是 Offscreen Canvas 技术。
例如 Babylon.js 目前已经实现:
https://doc.babylonjs.com/how_to/using_offscreen_canvas
https://www.babylonjs.com/demos/offscreen/
在主线程创建 canvas 并转移控制权:
const canvas = document.getElementById("renderCanvas");
const offscreen = canvas.transferControlToOffscreen();后续在 Worker 中完成绘制:
onmessage = (evt) => {
canvas = evt.data.canvas;
const engine = new BABYLON.Engine(canvas, true);
// Your scene setup here
}目前支持 WebGPU 的各个浏览器还未实现:
gpuweb/gpuweb#403
降低迁移门槛
之前我们设想让开发者使用类 TS 语法完成算法从 CPU 侧到 GPU 侧的迁移(JS/TS -> GLSL/WSL/Tint),减少迁移成本。
但在实际实现过程中,如果想进一步提升 GPU 的计算效率,不可避免的需要考虑数据结构在 GPU 内存中的存储,这会影响到:
- Shader 中数据访问部分的实现
- CPU 侧如何构建供 Shader 访问的初始数据,例如 ParaGraphL
因此,帮助开发者完成迁移,保证算法能在 GPU 中运行只是第一步,如何帮助开发者写出更高效的算法需要更多思考。
问题背景
算法本身很简单,G6 已有的实现:

目前已有WebGL 版本:https://nblintao.github.io/ParaGraphL/
在该实现中,由于 WebGL 不支持 ComputeShader,因此只能将节点位置计算放在 FragmentShader 中进行(常见的 WebGL GPGPU 实现),值得一提的是依然采用 sigma(SVG)渲染节点。
另有 Unity 版本:https://github.com/l-l/UnityNetworkGraph/blob/master/Assets/Shaders/GraphCS.compute。
我们希望在 WebGPU 版本中,渲染和计算都在 GPU 侧完成。为了达到最佳的渲染和计算效率:
其中算法的迁移(JS -> GLSL)本身并不复杂,值得一提的是第二点。
内存友好的布局方式
AoS vs SoA
按照 OOP 常规的编程习惯,很容易使用 AoS(Array-of-Structures),

在处理一组对象时,如果只需要对象的部分属性,就会造成 CPU 缓存的浪费。例如只需要 name 属性,也必须读入一整行:
而 SoA 对于 CPU 缓存更友好,读取第一个对象的某个属性时顺便把后续几个也一并读入缓存了,尤其在大量遍历对象的场景:

因此我们在引擎设计时也使用了 ECS 架构,同样基于以上考虑。
回到该算法本身,我们也可以使用类似思路组织 Nodes 和 Edges,充分考虑 GPU 内存的顺序读性能。
组织 Nodes & Edges 数组
在 JS 实现(G6)中,并不需要考虑连续读的内存友好性:https://github.com/antvis/G6/blob/master/src/layout/fruchterman.ts#L236-L237:
在 https://nblintao.github.io/ParaGraphL/ 的实现中,就充分考虑到了 GPU 内存的顺序读,同时尽可能压缩(例如每一个 Edge 的 rgba 分量都存储了临接节点的 index):

以斥力计算(G6 的实现)为例,需要遍历除自身外的全部其他节点,这全部都是顺序读操作。
同样的,在计算吸引力时,遍历一个节点的所有边也都是顺序读。
随机读只会出现在获取端点坐标时才会出现。
后续优化
Offscreen Canvas
看到目前 G6 中已有将布局计算放在 WebWorker 中进行的实践,实际上渲染也可以,完成主线程与渲染线程的分离,这样主线程处理交互和其他重计算任务就有了更多空间,这便是 Offscreen Canvas 技术。
例如 Babylon.js 目前已经实现:
https://doc.babylonjs.com/how_to/using_offscreen_canvas
https://www.babylonjs.com/demos/offscreen/
在主线程创建 canvas 并转移控制权:
后续在 Worker 中完成绘制:
目前支持 WebGPU 的各个浏览器还未实现:
gpuweb/gpuweb#403
降低迁移门槛
之前我们设想让开发者使用类 TS 语法完成算法从 CPU 侧到 GPU 侧的迁移(JS/TS -> GLSL/WSL/Tint),减少迁移成本。
但在实际实现过程中,如果想进一步提升 GPU 的计算效率,不可避免的需要考虑数据结构在 GPU 内存中的存储,这会影响到:
因此,帮助开发者完成迁移,保证算法能在 GPU 中运行只是第一步,如何帮助开发者写出更高效的算法需要更多思考。