Waterfall: Scalable Framework for Robust Text Watermarking and Provenance for LLMs [EMNLP 2024 Main Long]
Gregory Kang Ruey Lau*, Xinyuan Niu*, Hieu Dao, Jiangwei Chen, Chuan-Sheng Foo, Bryan Kian Hsiang Low
TL;DR: Training-free framework for text watermarking that is scalable, robust to LLM attacks, and applicable to original text of multiple types

-
Watermark original text
$T_o$ with watermark key$\mu$ → watermarked text$T_w$ with same semantic content -
Adversaries try to claim IP by plagiarizing text (e.g. paraphrasing), or by using text to train their own LLMs without authorization
-
Clients can quickly verify whether a suspected text
$T_{sus}$ contains the watermark and originated from$T_o$
Note: This code has been slightly modified from the implementation of the experiments in the paper. Refer to Appendix L.6 for details.
Protecting intellectual property (IP) of text such as articles and code is increasingly important, especially as sophisticated attacks become possible, such as paraphrasing by large language models (LLMs) or even unauthorized training of LLMs on copyrighted text to infringe such IP. However, existing text watermarking methods are not robust enough against such attacks nor scalable to millions of users for practical implementation. In this paper, we propose Waterfall, the first training-free framework for robust and scalable text watermarking applicable across multiple text types (e.g., articles, code) and languages supportable by LLMs, for general text and LLM data provenance. Waterfall comprises several key innovations, such as being the first to use LLM as paraphrasers for watermarking along with a novel combination of techniques that are surprisingly effective in achieving robust verifiability and scalability. We empirically demonstrate that Waterfall achieves significantly better scalability, robust verifiability, and computational efficiency compared to SOTA article-text watermarking methods, and also showed how it could be directly applied to the watermarking of code.
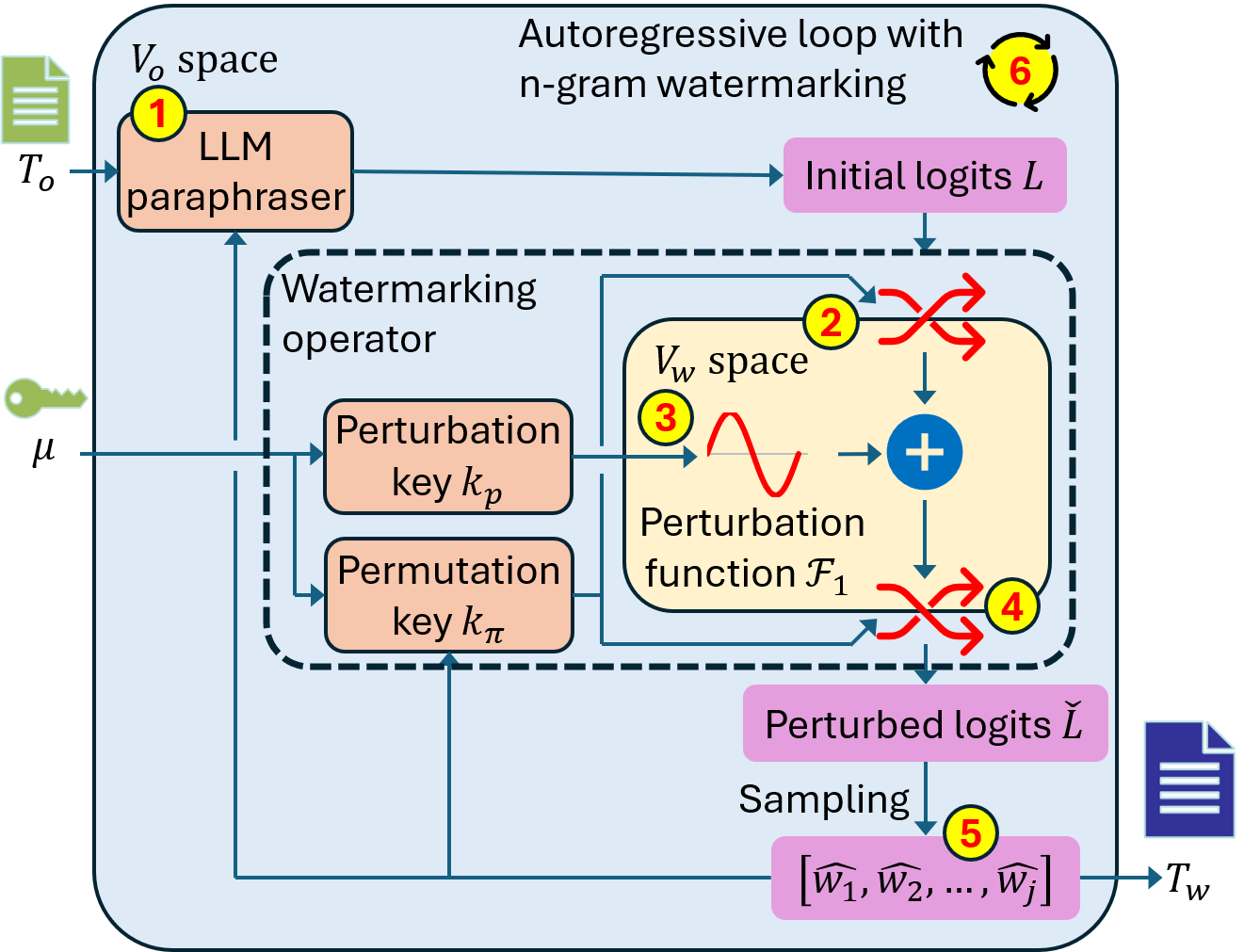
-
Original text
$T_o$ is fed into LLM paraphraser to produce initial logits$L$ . -
Unique ID
$\mu$ and preceding$n-1$ tokens form the permutation key$k_\pi$ which seed a pseudo-random permutation which permutes the initial logits from$V_o$ space into$V_w$ space. -
Perturbation key
$k_p$ selects a perturbation function$\mathcal{F}_1$ out of a family of orthogonal functions.$\mathcal{F}_1$ is added to the permuted logits. -
The perturbed logits are permuted back from
$V_w$ space into$V_o$ space with the inverse of the permutation in step 2. -
A token is sampled from the perturbed logits
$\check{L}$ and is appended to the watermarked text. -
Append the generated token to the prompt and continue autoregressive generation (steps 1-5) until the
eostoken.

-
For each token
$\hat{w}$ in the watermarked text$T_w$ (original text is not required), use the unique ID$\mu$ and preceding$n-1$ tokens to permute the token index of$\hat{w}$ from$V_o$ space into$V_w$ space. -
Count the tokens to get a cumulative token distribution
$C$ in$V_w$ space. -
Calculate the watermark score
$q$ by taking the inner product of the cumulative token distribution$C$ with the perturbation function$\mathcal{F}_1$ . -
Watermarked text will have
$C$ that resembles$\mathcal{F}_1$ , resulting in high$q$ . Unwatermarked text or text watermarked with different ID$\mu$ will have a flat$C$ , and text watermarked with different$k_p$ will have a$C$ that is orthogonal to$\mathcal{F}_1$ , resulting in low watermark score$q$ .
-
Perform steps 1-2 in verification.
-
Calculate the watermark scores
$q$ for all perturbation functions$\mathcal{F}_1$ in family of orthogonal functions. -
Extracted
$k_p$ corresponds to the perturbation function$\mathcal{F}_1$ with the highest scoring watermark score in step 2.
Install our PyPI package using pip
pip install waterfall[Optional]
If using conda (or other pkg managers), it is highly advisable to create a new environment
conda create -n waterfall python=3.11 --yes `# Compatible with python version higher than 3.10`
conda activate waterfallClone and install our package
git clone https://github.com/aoi3142/Waterfall.git
pip install -e Waterfall `# Install in 'editable' mode with '-e', can be omitted`Use the command waterfall_demo to watermark a piece of text, and then verify the presence of the watermark in the watermarked text
waterfall_demo* Ensure that your device (cuda/cpu/mps) has enough memory to load the model and perform inference (~18GB+ for default Llama 3.1 8B model)
Additional arguments
waterfall_demo \
--T_o "TEXT TO WATERMARK" `# Original text to watermark` \
--id 42 `# Unique watermarking ID` \
--k_p 1 `# Additional perturbation key` \
--kappa 2 `# Watermark strength` \
--model meta-llama/Llama-3.1-8B-Instruct `# Paraphrasing LLM` \
--watermark_fn fourier `# fourier/square watermark` \
--device cuda `# Use cuda/cpu/mps`* By default, --device automatically selects among cuda/cpu/mps if not set
To watermark texts
from waterfall.watermark import watermark_texts
id = 1 # specify your watermarking ID
texts = ["...", "..."] # Assign texts to be watermarked
watermarked_text = watermark_texts(texts, id) # List of stringsTo verify watermark strength of texts
from waterfall.watermark import verify_texts
id = 1 # specify your watermarking ID
test_texts = ["...", "..."] # Suspected texts to verify
watermark_strength = verify_texts(test_texts, id) # np array of floatswatermark.py: Sample watermarking script used by withwatermark_democommand, includes beam search and other optimizationsWatermarkerBase.py: Underlying generation and verification code provided byWatermarkerclassWatermarkingFn.py: Abstract classWatermarkingFnfor watermarking functions, inherit it to create new perturbation functionsWatermarkingFnFourier.py: Fourier watermarking functionWatermarkingFnFourierinherited fromWatermarkingFnWatermarkingFnSquare.py: Square watermarking functionWatermarkingFnSquareinherited fromWatermarkingFn
@inproceedings{lau2024waterfall,
title={Waterfall: Scalable Framework for Robust Text Watermarking and Provenance for {LLM}s},
author={Lau, Gregory Kang Ruey and Niu, Xinyuan and Dao, Hieu and Chen, Jiangwei and Foo, Chuan-Sheng and Low, Bryan Kian Hsiang},
booktitle={Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing},
year={2024},
month={nov},
address={Miami, Florida, USA},
url={https://aclanthology.org/2024.emnlp-main.1138/},
doi={10.18653/v1/2024.emnlp-main.1138},
pages={20432--20466},
}