ARTEMIS-1476 HdrHistogram support on verbose SyncCalculation#1605
ARTEMIS-1476 HdrHistogram support on verbose SyncCalculation#1605franz1981 wants to merge 1 commit intoapache:masterfrom
Conversation
c7eb0b9 to
45edc47
Compare
|
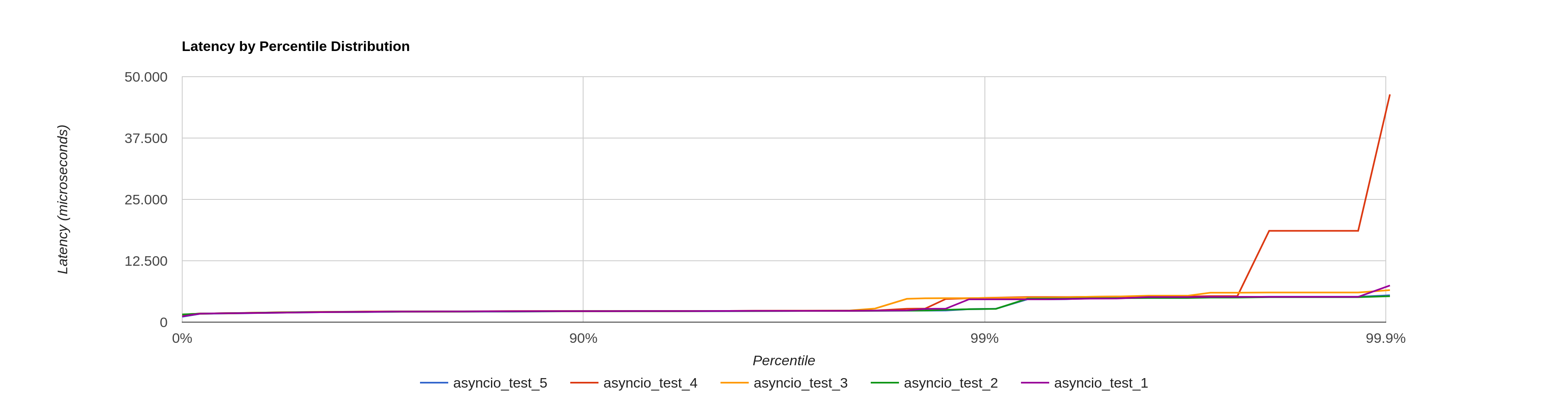
One example of the possible usage of the results using http://hdrhistogram.github.io/HdrHistogram/plotFiles.html is: |
| for (int ntry = 0; ntry < tries; ntry++) { | ||
|
|
||
| //perform a gc on each test iteration to help cleanup of callbacks/garbage | ||
| System.gc(); |
There was a problem hiding this comment.
I wouldn't do this.
The previous version was pretty much garbage free... if you must do this, I wouldn't merge the commit at all.
Besides... System.gc() will start a gc in parallel, and you will be already measuring the next write iteration.. which will affect the performance.
There was a problem hiding this comment.
Good point, I'm addressing all these things, but I need feedback on that too :)
I see 2 options here:
- preallocate and cache the
blocksIO callbacks (but could be a large number too) in order to be garbage free again - let the IO callbacks to size the (young) GC regions in the first test but uses a better way (ie more reliable) to be sure GC won't affect the measurements
I'm pushing the second solution right now, using the code used by the official microbenchmark tool of the OpenJDK JMH (http://hg.openjdk.java.net/code-tools/jmh/file/e96cad1fc480/jmh-core/src/main/java/org/openjdk/jmh/runner/BaseRunner.java#l309) to perform reliable GC, but feel free to give me feedbacks and suggest me to try the first one too, although I'm not 100% sure could be a better way (cachin a large number of instances in not optimal!!).
There was a problem hiding this comment.
We can always write the same thing. Why cache large numbers of Anything? Just write and send the same thing over and over.
This thing is settled. Not under production. We should leave this one as is IMO.
There was a problem hiding this comment.
Not under production I mean. This is only used once to create the server. Just leave it be.
| factory = new NIOSequentialFileFactory(datafolder, 1).setDatasync(datasync); | ||
| ((NIOSequentialFileFactory) factory).disableBufferReuse(); | ||
| if (bufferReuse) { | ||
| ((NIOSequentialFileFactory) factory).enableBufferReuse(); |
There was a problem hiding this comment.
This is also wrong... you are changing the semantic of this test...
We are measuring how much write the system can do... Using the buffer will defeat the purpose of the test...
Besides you are using the timeouts from where? this is not the intention of this calculation.
|
You told me you would just add verbose output here.. not change semantics of the test for no reason. There was a lot of testing around this... changing the semantics like this out the blank without the proper testing won't help much. |
|
This adds complexity that we don't need.. you're even requiring GCs to perform now.. the previous version wouldn't generate any garbage during the measurements (just simple buffer.write all the time.. always the same buffer). |
45edc47 to
9cd7303
Compare
|
@clebertsuconic I've pushed the second solution right now, using a method to perform reliable GCs (+ await them to happen) used in the official microbenchmark tool of the OpenJDK JMH too (http://hg.openjdk.java.net/code-tools/jmh/file/e96cad1fc480/jmh-core/src/main/java/org/openjdk/jmh/runner/BaseRunner.java#l309). Feel free to give me feedbacks on it and if we need something similar in other parts (a more reliable way to perform/await GCs to happen) I can put it in our utlity classes too. |
64fa4b5 to
8138e53
Compare
|
@clebertsuconic As a note: now without
|
|
The issue is on the performWrite. You are creating buffers and callbacks for each write. |
|
In the last version I've pushed I'm reusing the same buffer |
|
Here: |
| <artifactId>commons-lang3</artifactId> | ||
| <version>${commons.lang.version}</version> | ||
| </dependency> | ||
| <dependency> |
There was a problem hiding this comment.
Whats the license of this?
pom.xml
Outdated
| <groupId>org.hdrhistogram</groupId> | ||
| <artifactId>HdrHistogram</artifactId> | ||
| <version>${org.hdrhistogram.version}</version> | ||
| <!-- License: Apache 2.0 --> |
There was a problem hiding this comment.
I don't believe it is Apache license.
There was a problem hiding this comment.
Yep: super good point!! It is not obvious at all...I'm checking it!!!
There was a problem hiding this comment.
This one: https://github.com/HdrHistogram/HdrHistogram/blob/master/LICENSE.txt
Argh!!!
There was a problem hiding this comment.
Seems BSD 2 mmmmm
|
The license says public domain. And if you need a license BSD. |
8138e53 to
faf1050
Compare
|
@clebertsuconic I'm not a lot familar with these, but:
what kind of licence I've to report on the |
|
Lets use it under free public domain. As they allow it. |
c0ea557 to
999dd38
Compare
|
@clebertsuconic ok!! I'm updating the PR with it! |
31ae9b8 to
f357d78
Compare
|
@clebertsuconic Done! |
f357d78 to
482985e
Compare
|
@franz1981 i really like the ability to get a histogram of the sync test so you can see the percentiles of the disk performance from activemq's view. I do share some concerns with @clebertsuconic that it is quite a re-write in the logic, this is quite a core tool to get the journal settings right, i know @clebertsuconic spent a lot of time with us previously getting it to work and fix issues. To mitigate this concern, have we an ability to validate the result is the same before and after this change? e.g. some sort of test? If we can't then at least could we manually check it on a few different disks which will perform differently, e.g. SAN, HDD, SSD and check the output manually. The difference in previous in the conversation above, actually isn't negligible when talking about SSD over SATA or NVMe. eg. NVMe i believe buffer-timeout can be as low as 4000 on newest of kit. in general +1 this though. HDR is fairly standard lib, we use it lots too here :) |
Right now the calculation of the timeout isn't changed at all while the test methodology (and the output of course) is changed only if The other improvements (without affecting the no |
|
@franz1981, this makes sense and good to know +1, ill leave some comments in place in code in a sec, where looks like some bits still leaked into existing logic. and let you comment. |
| SequentialFileFactory factory = newFactory(datafolder, fsync, journalType, blockSize * blocks, maxAIO); | ||
|
|
||
| final Supplier<? extends SyncIOCompletion> ioCallbackFactory; | ||
| final Histogram writeLatencies; |
There was a problem hiding this comment.
Should this be just in the if verbose section?
| JournalType journalType) throws Exception { | ||
| SequentialFileFactory factory = newFactory(datafolder, fsync, journalType, blockSize * blocks, maxAIO); | ||
|
|
||
| final Supplier<? extends SyncIOCompletion> ioCallbackFactory; |
There was a problem hiding this comment.
can this be just in the verbose section?
There was a problem hiding this comment.
essentially i would be expecting to see no diff in the code, except an if (verbose) statement with all the change only in that section.
Currently there is too much diff to be sure the logic is the same.
There was a problem hiding this comment.
TBH I've provided a couple of fixes too :P: like the one on the file size with alignment != 1.
I've tried to have a common logic while grouping the differences in order to have a simpler and maintainable code: probably that's the reason why you are seeing such differences on the source code.
I've already evaluated (ie JitWatch on the rescue) such abstraction won't affect the performance of the 2 cases, but if you think that is better to put everything under a big if (verbose) I can understand your reasons too: that's why having 6 eyes on it is more than wellcome IMO :)
There was a problem hiding this comment.
For me trying to understand the code just for a review and understand the differences/changes right now is a bit hard, as too much has moved, its not impossible just is making it tricky to be sure.
If you're not too much against it, it might be easier to do the "if", then it is simply cleaner / easier from a review POV to see what is changed / get comfortable that actually the old behaviour is as is.
Then anyhow as we get more confident it might the if statement always equates to true anyhow and the other side of the if block is removed entirely.
If theres a couple of fixes in existing this can still be there, but then it be obvious what changes are done to fix as well.
There was a problem hiding this comment.
For me trying to understand the code just for a review and understand the differences/changes right now is a bit hard, as too much has moved, its not impossible just is making it tricky to be sure.
I think is normal: I've used the splitted view on github and it helps (vs the unified one), but probably it works just if you already know by heart the original code. Your review is a good way for me to have a more objective view of that so I will provide a cleaner separation of the 2 paths as a separate commit to be squashed if it will pass the reviews (by the end of the day; I've other stuff to do first :P).
Just for the sake of completeness, I will ask to @clebertsuconic too: he knows by heart the original code for sure!
@clebertsuconic wdyt about the last implementation? Have you found difficult to trace/understand how much has changed the not --verbose path vs the original?
482985e to
4824a27
Compare
|
I want to -1 this commit @franz1981..This is supposed to be a dumb piece of code.. making IO writes at garbage free. For instance.. I told you to use the same buffer, and the same Completion over and over.. like it was before. There's not guarantees about the ordering won't be changed... trusting that just makes it more fragile. If you just added the Histogram like you said you would.. it would be one thing.. but this logic is completely changed.. and I had spent a lot of time to make sure about these calculations, using different hardwares (disk types). |
And in the not verbose case it is garbage free as it was originally :) Please use the latest commit to see it.
In the not verbose case I've reused the buffer and the IOCompletion while in the verbose case only the buffer, because I haven't found a way to maintain for each write operation its own start time: if you see a better way to do that please help me to understand it 👍
And it is the reason why I'm providing a new commit that split the 2 logic in a clean way in order to maintain the original 1:1 as it is (tiny bugs included). |
|
I am using it... I just don't understand why you would only use the last callback.. why so much complexity added? if this complexity was added around say.. for instance... JournalImpl::show statistics.. I would go for it... but here at the sync calculation? I think this is being a lot of complexity for something that is supposed to be simple. |
|
for instance.. you could have chosen to add the Histogram without making any other changes.. I don't understand why you wanted to do that? just to understand the code? (not that this would be a good reason). It just gets harder to maintain. why you wanted to just wait the last callback for instance? why such change? and why to create many callbacks? Why to add this complex System.gc code? |
+100 This is exactly the point mate :)
It seems not possible (to me at least :(): each write request (with ASYNCIO and not syncWrites) need its own start time in order to compute the latency of the operation (and record it on the histogram). |
|
@clebertsuconic @michaelandrepearce Consider the last commit code the base for a "journal's show statistics" command: i will open a different JIRA with it if it seems ok and I will drop the timeout calculation too, the histograms are enough for it. |
|
@franz1981 The Sync calculation is not part of the life cycle of the server running at all... At a later point, when we added create.. I added this sync tool to make an approximated auto-tune for the system. anything beyond that is out of context. It doesn't really matter to add histograms at the sync-calculation, or to perform any writes... However.. during the process (aka production)... it would matter... Look at TimedBuffer::logRatesTimer... there a Histogram would make a lot more sense... and actually that logRatesTimer doesn't belong into TimedBuffer maybe now that we can disable TimedBuffer optionally. |
That's the part I'm trying to understand: IMHO it matters to have a more detailed view of the sync test using standard de facto tools too as @michaelandrepearce has stated above in other comments. |
|
wouldn't be easier to keep all the original code and just add the Histogram.. without changing how callbacks are happening for example.. (The reason why you needed GCs). just use the original code... make simple changes... add the histogram (when --verbose).. and it's a lot easier to understand the impact of the changes. |
|
if you are actually measuring 99%.. do you really need to take out GCs from the calculation? just keep it simple.. this is not simple as I see this. |
There are good reasons I can't do it and one is written below:
The others was related to compilation of methods by the JIT compiler if you have > 10000 writes and very fast storages/no fsync: you need to add
I'm providing all the percentiles offered by the HDR histogram and the GC is already taken out of the async measurements (if you have enough heap) by using the IMO could be a good idea to provide this feature it is to drop at all the timeout calculation if a user just want the latencies percentiles and let the original calculation being used otherwise. I simply don't know how/in what form expose such tool, @clebertsuconic @michaelandrepearce any idea?make sense? |
|
@clebertsuconic @michaelandrepearce
I've provided an attempt to do that here: https://github.com/franz1981/activemq-artemis/tree/stat-journal-histogram while in the current PR there is the most recent version I can build that uses the original code. @michaelandrepearce Now I think it could be reviewed with ease 👍 Today I'm doing other stuff so I will probably do something on that in the weekend... |
ec33d57 to
2c36542
Compare
…and synchronous writes
2c36542 to
9525d52
Compare
|
|
||
| long[] result = new long[tries]; | ||
|
|
||
| byte[] block = new byte[blockSize]; |
There was a problem hiding this comment.
Why is this being removed?
There was a problem hiding this comment.
Ignore, just noticed you moved this into allocateAlignedBlock
|
@franz1981 this is much cleaner +1, also its good to see the existing logic remains pretty much the same, just now with HDR being captured. |
It includes: