YARN-11402 Plenty of useless logs printed during ResourceManager startup and recover containers of unknown application #5247
Conversation
…tup and recover containers
| private void killOrphanContainerOnNode(RMNode node, | ||
| NMContainerStatus container) { | ||
| if (!container.getContainerState().equals(ContainerState.COMPLETE)) { | ||
| LOG.warn("Killing container " + container + " for unknown application"); |
There was a problem hiding this comment.
Will this change result in more log output? Does this mean that all apps that enter this judgment must be printed?
There was a problem hiding this comment.
Thank you very much for your contribution, but I think different people may have different understandings of the log output. This does not seem to be a general change, and I have not seen much value from this change.
There was a problem hiding this comment.
Will this change result in more log output? Does this mean that all apps that enter this judgment must be printed?
@slfan1989 Not really, Only the orphan container which status is unfinished will be killed and logged here. What is really matters is the minority ones be handled not the majority ones be skipped.
There was a problem hiding this comment.
I took a quick look at it yesterday, and today I'll take a closer look at the code.
|
💔 -1 overall
This message was automatically generated. |
|
We're closing this stale PR because it has been open for 100 days with no activity. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. |
Tens of thousands of meaningless logs are frequently printed during ResourceManager startup and recover container.
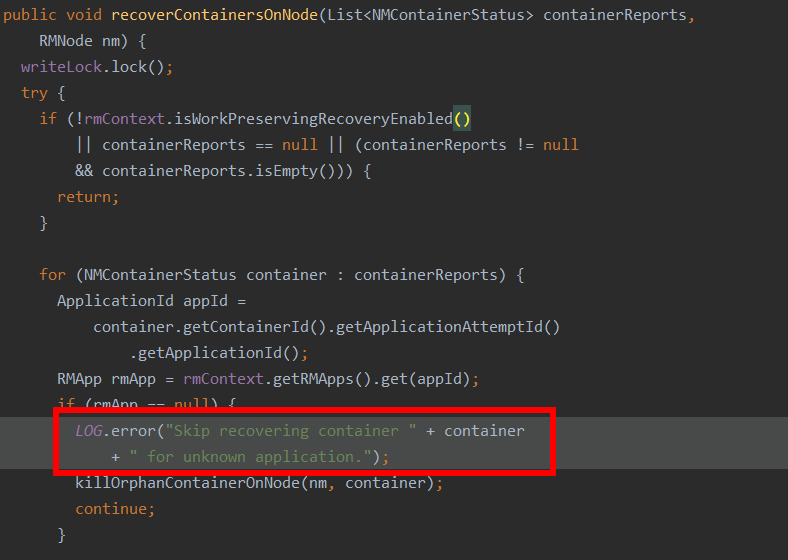
As we know, ResourceManager will always keep 10k application information by default. In our very big scale cluster, it is very usual that resourcemanager try to recover the containers which already finished and does not exist in ResourceManager but still reported by nodemanager.
Under this case, below logs will be frequently printed, more importantly, this log is meaningless, in real production setups, the maintainers actually more care about which containers are properly recovered or killed not the ones are skipped.
The related code are as follows,
So we move the log into function killOrphanContainerOnNode().
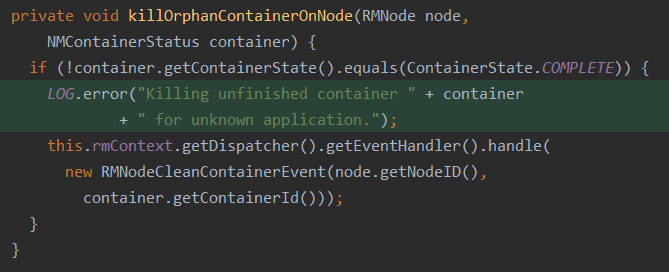
Only the containers to be killed need to be loged which is vital for trouble shooting to distinguish whether the containers are kill by hadoop inner mechanism or by users themselves.