glimpse #131
glimpse #131
Conversation
|
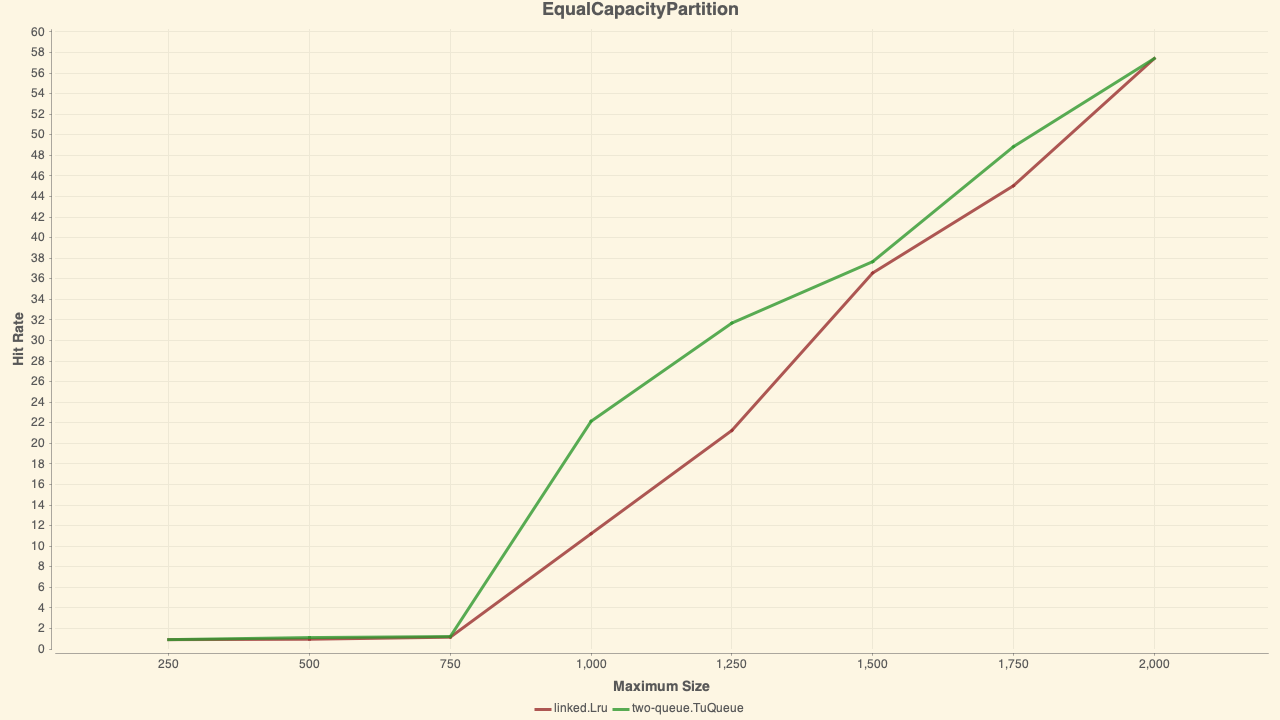
fyi, when I try in the simulator's version of this policy (TuQueue) I get better hit rates than LRU. Maybe there is a bug in yours clock adapted variant? ./gradlew simulator:simulate -q \
--title=EqualCapacityPartition \
--maximumSize=250,500,750,1000,1250,1500,1750,2000 \
-Dcaffeine.simulator.files.paths.0=gli.trace.gz \
-Dcaffeine.simulator.admission.0=Always \
-Dcaffeine.simulator.policies.0=two-queue.TuQueue \
-Dcaffeine.simulator.policies.1=linked.Lru \
-Dcaffeine.simulator.tu-queue.percent-hot=0.33 \
-Dcaffeine.simulator.tu-queue.percent-warm=0.33
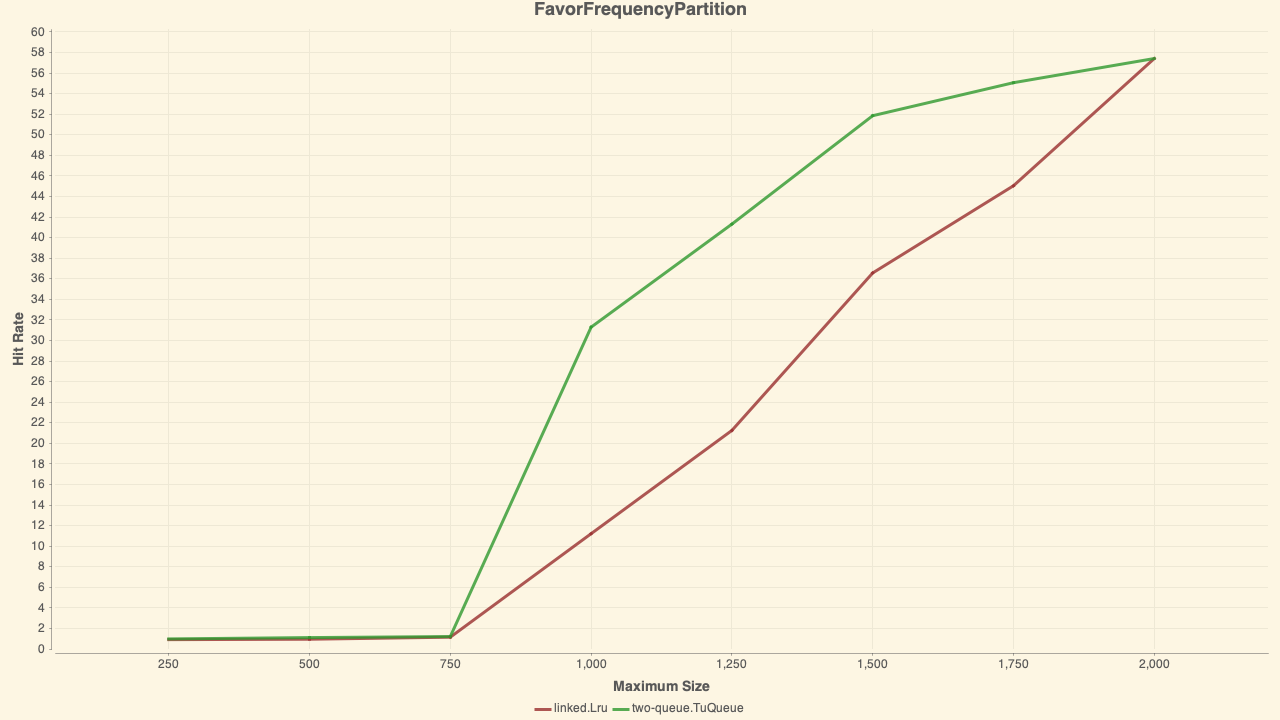
./gradlew simulator:simulate -q \
--title=FavorFrequencyPartition \
--maximumSize=250,500,750,1000,1250,1500,1750,2000 \
-Dcaffeine.simulator.files.paths.0=gli.trace.gz \
-Dcaffeine.simulator.admission.0=Always \
-Dcaffeine.simulator.policies.0=two-queue.TuQueue \
-Dcaffeine.simulator.policies.1=linked.Lru \
-Dcaffeine.simulator.tu-queue.percent-hot=0.1 \
-Dcaffeine.simulator.tu-queue.percent-warm=0.8
|
|
@ben-manes yeah - for sure not a good result. Previously I had only tested against Zipf distributions and traces from production systems (similar to your Wikipedia efficiency test). Thanks for providing the comparison with 2Q. ConcurrentLru uses FIFO queues for all buffers instead of a linked list LRU for the Am buffer in 2Q (there are other differences, but I suspect this is why it is much worse here). I used queues because .NET already has a performant ConcurrentQueue and in my earlier tests the results were decent with that simplification. For the glimpse trace, ConcurrentLru is not a good solution. I will retest with EqualCapacityPartition and FavorRecencyPartition (allocate larger hot queue), out of curiosity to see if there is scope for tuning or it still tanks. I replicated your efficiency tests from Caffeine, and this looks like the toughest workload. For the ARC workloads ConcurrentLru is comparable or slightly worse than LRU. For Wikipedia, ConcurrentLru does much better. |
|
I think you are using memcached's 2Q inspired policy? If so, then the terms from the 2Q paper can be confusing since it is not the same policy. In this blog post the author names his variant TU-Q. I would have expected your fifo idea to be pretty decent, actually. If I understand correctly, you use it as a Second Chance fifo where the mark bit lets it re-insert the item when searching for the victim. That's a pseudo LRU that matches very closely, with a worst case of O(n) as it has to sweep over all entries unmarking them to find the victim. Since it seems to be stuck even when the cache size increases, I think maybe something is wrong like it is not using up free capacity (e.g. does it evict if hot + cold are full and warm is empty?). glimpse is a loopy workload so MRU is optimal, making LRU-like policies struggle. It's a nice stresser for scan resistance, but is probably not as realistic as the db/search traces. I think it is a multi-pass text analyzer (this tool if I'm right). |
|
Excellent point - the policy is flawed during warmup and doesn't use the empty warm buffer at all - fixing that is the purpose of this PR. I started building out all the hit rate tests so I could validate whether fixing this actually matters. After I read your Caffeine wiki/TinyLfu paper I had the realization that it is most likely better to enlarge the warm buffer by default, favoring frequent items (similar to Caffeine's default allocation of 80% protected 20% probation - I figured you did that for a reason). And 80% warm worked better in the Zipf test (90% and 70% were worse). But with the smaller hot+cold, it is harder for items to get into warm and as you point out it gets stuck (I hadn't yet made the connection that this is likely what caused glimpse to get stuck - really good observation). It's also completely unintuitive that 80% of the allocated cache capacity won't be used until an item is accessed twice. Terminology is confusing - reading that blog post they write In the OpenBSD code, they are named hot, cold, and warm, and each is an LRU queue. I interpreted LRU as not FIFO - thinking hard on that now, i'm still not totally sure what it means :) Looking at your TuQueue code for In ConcurrentLru, each item list is a FIFO queue. I was thinking this simplification hurt the glimpse test, but the empty warm buffer is a more likely cause. Another difference, in ConcurrentLru cache hits don't move items at all - only the accessed flag is updated. Items only move across queues on miss. This has the effect of making hits on hot items very cheap but makes the LRU order less accurate. In steady state if there are no misses and only hits, ConcurrentLru has almost no overhead. On miss, items transition across queues only when a queue is above capacity (else item order remains fixed and new items are simply enqueued). The victim search is more limited than an O(n) search. Eventually over several misses the whole of warm is searched. In the context of a single cache miss each of warm and cold are cycled only when above capacity and at most twice. Worst case cache miss it will cycle warm and cold twice each, so there are 4x dequeue + 4x enqueue ops as overhead. Scanning warm O(n) to find and discard the first non-accessed item would be an interesting test. |
|
Those new numbers in that PR is really great! congrats 😃 In TuQueue, To follow TU-Q more strictly, your
The worst case is that all entries have For W-TinyLFU the SLRU paper recommended 20/80 to avoid cache pollution, and this made sense as we expected the probabilistic sketch would make some admission mistakes. At one point I saw it help on the wiki trace compared to an LRU main region, but that easily could have been (since fixed) flaws in my CountMin4 which it corrected for. It's likely that the SLRU is not needed anymore for similar quality, but theoretically I like the Edit: Rereading the TU-Q blog entry, code, and code comments... I am not sure if my implementation is correct. Maybe HOT is a FIFO after all? I may have been confused by calling each region an LRU and other odd phrasing. It seems oddly pointless to make HOT a fifo as that only serves to disallow promotions to WARM until its aged. Certainly the author made the explanations unnecessarily confusing... |
|
The memcached pr matches what I implemented. I think the OpenBSD code follows how you interpreted it, though. The important part of memcached's description is,
However, This text was modified also in the official docs,
The blog post has a similar description,
I guess my implementation is wrong by making HOT an LRU instead of a FIFO. I don't see a good reason for that, though, so will keep it as is for the time being. That misinterpreted structure was helpful as it led me to clarify my thinking for W-TinyLFU. |
|
Turned out much better than I expected! 😃 I missed this detail with the hot buffer re-circulating - I had never seen the OpenBSD docs, only the memcached blog post. It's a good thing to try - I can implement it pretty easily and compare against this as baseline. Hopefully I will get some time to try it next week. I'm curious if it makes much difference in practice, behavior in both cases would be pretty similar - except a slot in warm would effectively be swapped for hot in the case of a very high frequency key. This could give slightly more warm capacity since transient hot keys would not be retained in warm at the expense of longer-lived repeat keys. Key takeaway is that without adaptive queue sizing, the problem I fixed in the warmup PR still exists - it's just masked because glimpse is a repeat pattern. In other words, if I ran the Wikipedia bench, then glimpse, it would be back to 1.38% hit rate for the glimpse part. So, I think your addition of hill climbing is very important. It's an edge case, but one that is good to cover. BTW I think your hint on the queue sizing/warmup probably saved me weeks of thinking/debugging/testing - thank you! And also, I got a huge head start by looking at your tests - you distilled down the most interesting scenarios without which it would be tough to draw conclusions about adaptive queue sizes etc. I was using the hit rate test methodology from the 2Q paper, which now I look is from 1994. |
|
For hill climbing I took a very straightforward approach. It uses a high sampling period (10x max size) and decays from an initially large step size for convergence. This came about when charting multiple traces and their configurations, where none was optimal for all, and realizing I could simply walk the curve for that workload. I was surprised that no one else seemed to do that, with ARC taking a less direct route (as did my early attempts at feedback). I tried small periods and small step sizes, but the climber got confused due to noise. I also tried gradient descent but couldn't figure out the derivative for the slope, so all of its variations (popularized by ML articles) didn't work. However they have some neat optimizations like momentum and an adaptive learning rates (step sizes) to speed up the convergence. I was able to borrow the adaptive learning rate idea when implementing it in the library (our paper is before that, where the code was merely an early PoC). I think that that adding momentum would be a nice improvement, but I have not seen a workload justifying that experiment (so the simplest code wins out without data). My hypothesis is to start with a small sample period that gradually gets larger (e.g. 0.5x ... 10x) and a large step size that gradually decays (e.g. 5% ... 0%). Then hopefully early on it makes rapid guesses that are large enough to dampen the noise but is more likely to be wrong, finds the configuration to oscillates around, and slowly converges to that optimal, long-term value. That intuitively seems nicer for a large cache, but I don't know yet. Similarly, I don't have data to justify trying to adapt a very tiny cache where the current math fails (10 entries x 5% = 0 initial step size). I'm sure it is not optimal, but miniscule caches are probably safe to be given a higher value and likely not monitored, so their usefulness is a developer's random guess anyway. Again without data I'd probably do more harm if I tried, so I am waiting for some unfortunate user to complain. Outside of eviction, I was also quite happy with how my approaches towards concurrency (replay buffers) and expiration (hierarchical timing wheels) turned out. Lots of tradeoffs that aren't right for everyone, but fun problems and those overlooked techniques were enjoyable to code. |
For the Glimpse scenario ConcurrentLru performs significantly worse than LRU: