5.8 million unique GitHub commit emails (git config user.email) extracted from https://www.githubarchive.org from 2011-02-12 to 2015-12-31. 2016-06-03: emails removed from this repo after request from GitHub. 2016-08-11: emails on GitHub Archive hashed. 2016-08-30: privacy policy updated (because of this repo?! We shall never know). 2018-02-21: dangling commits actually removed… :-)
Cite this repo: Related: https://cirosantilli.com/all-github-commit-emails
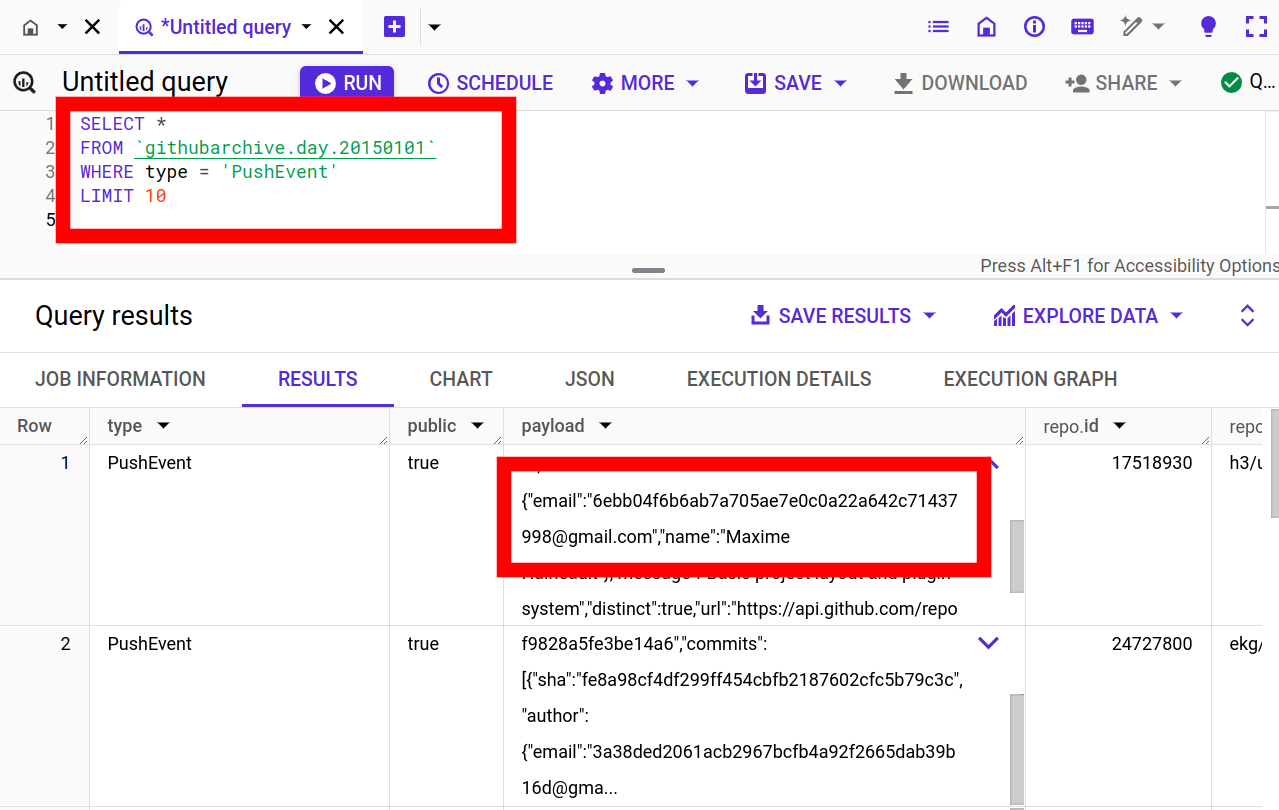
How it looked like before takedown:
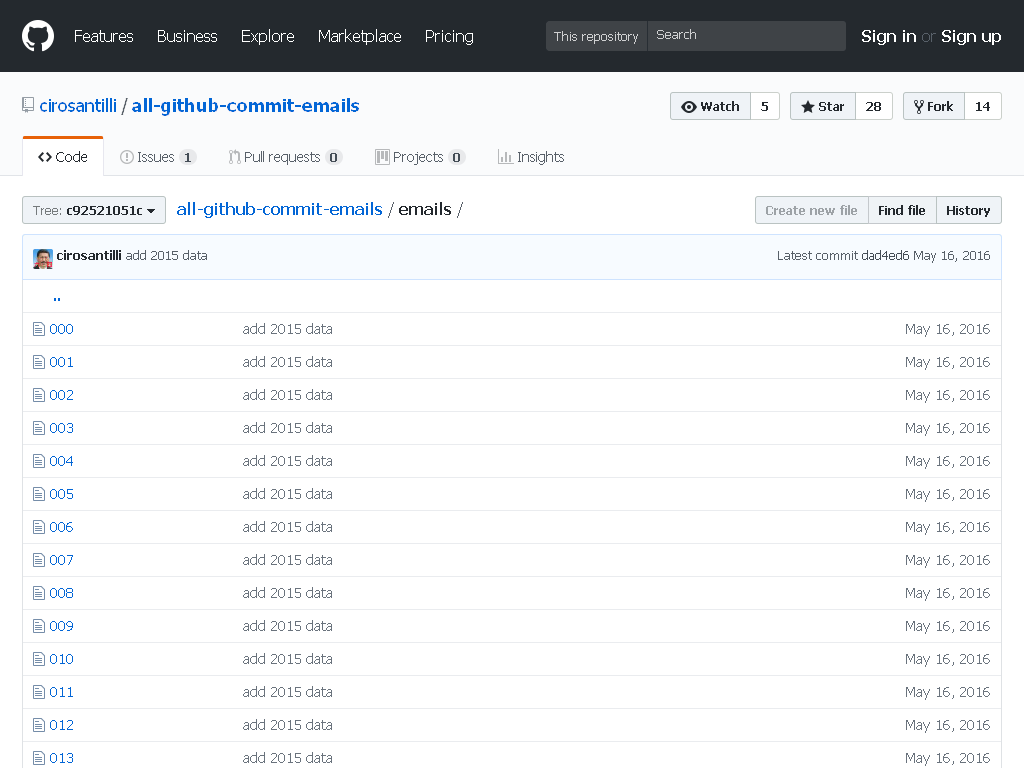
It was brought to my attention in previous days that the dangling commits were still visible, and in particular that you can easily download the full repo, as explained at: https://stackoverflow.com/questions/872565/remove-sensitive-files-and-their-commits-from-git-history/32840254#32840254
I then contacted GitHub staff, and they replied that it was because the now deleted pull request 2: https://github.com/cirosantilli/all-github-commit-emails/issues/2 pointed to it. They requested to delete it, and I approved, and now the dangling commits are gone AFAIK.
This means that for more than an year after the original removal attempt, the emails were still easily extractable :-)
It also taught us that GitHub staff has the power to completely delete issues: https://stackoverflow.com/questions/3081521/how-to-completely-remove-an-issue-from-github/25324423#25324423
The new privacy statement covers more explicitly. I forgot to take a web archive snapshot at that time, but here is the current one: http://web.archive.org/web/20171224084808/https://help.github.com/articles/github-privacy-statement/#public-information-on-github :
If you would like to compile GitHub data, you may only use any public-facing Personal Information you gather for the purpose for which our user has authorized it. For example, where a GitHub user has made an email address public-facing for the purpose of identification and attribution, do not use that email address for commercial advertising. We expect you to reasonably secure any Personal Information you have gathered from GitHub, and to respond promptly to complaints, removal requests, and "do not contact" requests from GitHub or GitHub users.
I’ve checked it today, and the emails seem to have been removed from GitHub Archive: the either null, or of form <username sha>@<host>.
GitHub has asked me to take the emails down, and since they are also talking to GitHub Archive and GHTorrent, I took the emails down in good faith. GitHub Archive data was still available.
support@github.com 2016-06-03 email:
Hi Ciro,
I’m reaching out on behalf of GitHub’s Support team. A number of users have contacted us with questions about the following repository: https://github.com/cirosantilli/all-github-commit-emails.
We read through the repository’s README, and appreciate your point about how easy it can be for spammers to scrape users' email addresses. We also appreciate that you’ve brought this to the community’s (and our) attention. We thought you’d like to know we’ve been working with GitHub Archive and GHTorrent to scrub this data from their archives, and that both organizations have agreed to refrain from collecting this data in the future. Additionally, we’ll be working with other research organizations to encourage them to comply with our policies on data minimization.
In keeping with these efforts to better protect our users' privacy, we’re asking you to take down your all-github-commit-emails repository. We’d like for you to remove it voluntarily. However, because it does violate our policies on user privacy and spam, we will remove it after one week if you do not.
Please let me know if you have any questions.
Best, Elizabeth
My reply:
Hi there.
Were you thinking about this before, or was it I that brought it to your attention?
Can we do it like this: I force push the actual emails out (already done), keep the README intact, and then you tell the engineering team to do a git gc to remove old commits from your APIs? This way I get to keep my heard earned stars and URL. The extraction method itself is trivial once you know the words "GitHub Archive extract commit emails".
I’ll expect a future blog post on the matter from GitHub when you’ve got things sorted out, clarifying / quoting your data scraping policy, and saying that GitHub Archive and GHTorrent were not compliant. Will you forbid mass scrapping entirely, or just remove the emails? Will you modify the current events API as well?
Please state somewhere official (above blog post or some repository a la https://github.com/github/dmca ) that my repository was taken down and why. If you found my contribution considerable, please mention it on the blog post.
:-)
Goal: let spamees find how their email leaked via Google. Spammers can get this data any time since it is public.
Please don’t email me privately to take this down / remove your email from the list.
If you have a new argument, open a public issue.
Even better, tell GitHub, GitHub Archive, and http://ghtorrent.org/ (not used here) to drop this data instead.
If they all do that, I will also take this / your email down.
Otherwise, it makes no sense to take this down, since this data is still easily extracted from the source.
GitHub has a setting to use a dummy email for web UI operations: https://help.github.com/articles/keeping-your-email-address-private/ , but it does not affect visibility of commits done locally.
Getting the commit email of a particular user is trivial through the API as explained at: http://stackoverflow.com/a/32456486/895245 , so it is not much of a use case here, so usernames are not included in this data.
GitHub Archive started scraping in 2011-02-12 so older commits are not considered with the method.
In 2014-12-31, GitHub started using the new Events API.
Data is pushed daily to Google Big Query, and we will update this yearly with all the commits of the previous year.
This data is not shown on the GitHub web interface, but it is of course public because it can be seen after cloning.
GitHub also makes this data available on the PushEvent of the GitHub events API https://developer.github.com/v3/activity/events/types/#pushevent which GitHub Archive uses to export to a Google BigQuery table.
Download the query data as explained at: http://stackoverflow.com/questions/18493533/google-bigquery-download-all-data/37274820#37274820
Extract data up to 2014-12-31
SELECT payload_commit_email FROM [githubarchive:github.timeline] WHERE type = 'PushEvent' GROUP BY payload_commit_email ORDER BY payload_commit_email ASC
Extract data starting from 2015-01-01:
SELECT JSON_EXTRACT(payload, '$.commits[0].author.email')
FROM (
TABLE_DATE_RANGE([githubarchive:day.events_],
TIMESTAMP('2015-01-01'),
TIMESTAMP('2015-01-02')
))
WHERE type = 'PushEvent'
TODO: it would have been more intelligent to GROUP BY to only select unique values, and also do more cleaning on the server. Untested:
SELECT JSON_EXTRACT_SCALAR(payload, '$.commits[0].author.email')
AS email
FROM (
TABLE_DATE_RANGE([githubarchive:day.events_],
TIMESTAMP('2015-01-01'),
TIMESTAMP('2015-01-02')
))
WHERE
type = 'PushEvent'
AND email <> ''
GROUP BY email
ORDER BY email
The above query does not work, says email is not a field of the table.
This would reduce the output size by an order of magnitude.
TODO: extract all emails of a given push. We currently only extract the first one at commits[0]. Many JSON path implementations accept [*], but BigQuery does not: http://stackoverflow.com/questions/28719880/how-to-get-all-values-of-an-attribute-of-json-array-with-jsonpath-bigquery-in-bi 99% percent of the time it’s the same email however.
-
Clean up a bit if not done on the query:
cat * | sed -E '/^$/d' | sort -u > emails-big
-
Merge data from the two queries:
sort -u emails-old emails-new > emails-big
-
Split into multiple files:
split -a4 -C150k -d emails-big emails/
GitHub limits: hard limit: 100M per file, larger cannot be pushed web UI show limit: * TODO file size * 1000 files per directory
+ TODO: split data further into subdirectories:
00/00,00/01, …99/99to make loading faster on GitHub http://superuser.com/questions/443972/using-coreutils-split-file-into-pieces-to-different-directories
Count emails:
wc -l *
Most frequent hostnames:
cat * | sed -E 's/.*@(.*)$/\1/' | sort | uniq -c | sort -n | tail -n 1000
TODO: how many emails are valid: not simple since not parsable by regex:
Some common invalid emails
grep -E '[^0-9a-zA-Z!#$%&'"'"'*+-/=?^_`{|}~@]' * | wc
grep -v '@' * | wc
-
invalid characters: http://stackoverflow.com/questions/2049502/what-characters-are-allowed-in-email-address
-
no
@
About 4% of the emails failed the above checks.
In particular, emails containing <>\n may fsck unhappy, and may fail to push.
For fun:
grep 'password' *
Also contains some interesting long lines:
grep '.\{80\}' *
-
https://www.troyhunt.com/8-million-github-profiles-were-leaked-from-geekedins-mongodb-heres-how-to-see-yours/ the scrapper database of a company called Geekedin went public, and Troy said it was serious, But I think they don’t have any data not readily available form GitHub Archive.
Mostly from GitHub traffic.
Humans:
-
https://arxiv.org/pdf/1908.05354.pdf (archive) "Large-Scale-Exploit of GitHub Repository Metadata and Preventive Measures" by "David Knothe" and "Frederick Pietschmann" published on August 16, 2019.
-
2019-05 https://quassel.flyingyeti.ovh/ The software is https://en.wikipedia.org/wiki/Quassel_IRC by … https://en.wikipedia.org/wiki/Fly_Yeti ???
-
2016-09 https://www.zhihu.com/question/46957710 https://web.archive.org/web/20160920062505/https://www.zhihu.com/question/46957710
Internal security tools flashing a red light and leaking "internal" URLs:
Not sure: