A Git implementation built from first principles in Go to understand how distributed version control actually works. No libraries for Git operations - just hash-based storage, tree structures, and commit graphs.
Core features: Content-addressable storage, staging area, commit history, tree-based snapshots
Learning-focused, not production-ready
git clone https://github.com/codetesla51/go-git.git
cd go-git
./install.sh
# Or build manually:
go build -buildvcs=false -o go-git
ln -s $(pwd)/go-git ~/.local/bin/go-gitTry it:
mkdir my-project
cd my-project
go-git init
go-git config # Set your name and email
echo "Hello World" > README.md
go-git add README.md
go-git commit -m "Initial commit"
go-git logContent-Addressable Storage - Files stored by SHA-256 hash (deduplication built-in)
Staging Area (Index) - Git's "three-tree" architecture with staging layer
Tree Objects - Directory structure stored as nested tree objects
Commit History - Full commit chain with parent references
Compression - zlib compression for all objects (blobs, trees, commits)
Config Management - User name/email stored in .git/config
go-git init # Initialize repository
go-git config # Set user name and email
go-git add <files...> # Stage files (supports directories)
go-git commit -m "message" # Create commit
go-git log # View commit history
go-git help # Show available commandsInitialize Repository
go-git init
Creates .git/objects/ for content storage, .git/refs/heads/ for branch pointers, and HEAD pointing to main branch.
Configure User Identity
go-git config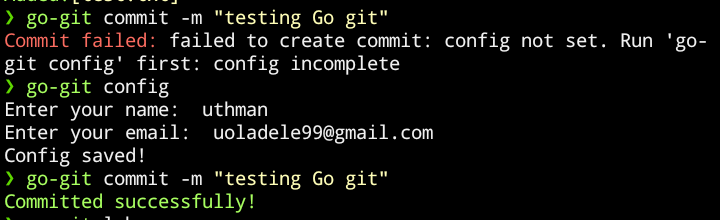
Prompts for user name and email, then writes them to .git/config. Every commit includes this information in the author field.
View Commit History
go-git log
Reads commit hash from HEAD → refs/heads/main, loads commit object, displays info, follows parent pointer, repeats until no parent exists.
Get Help
go-git help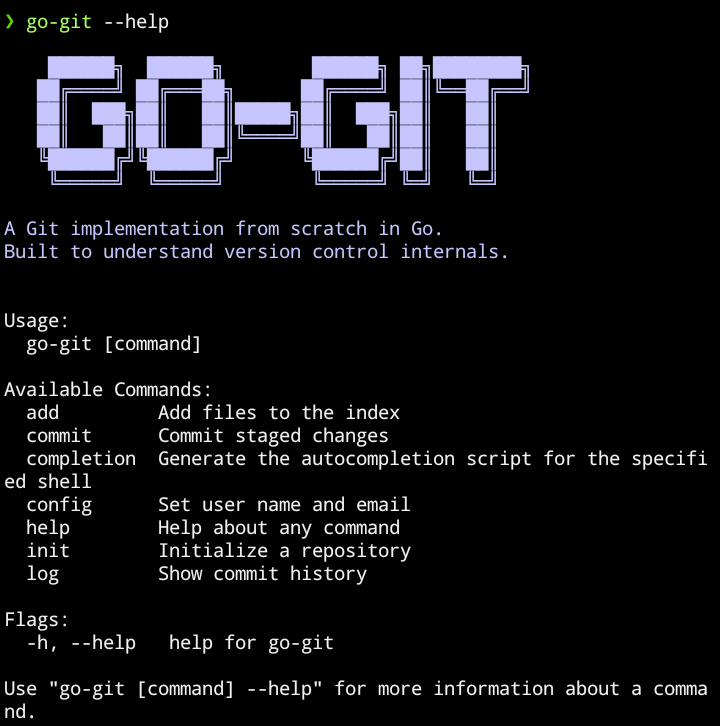
Displays CLI help menu with all available commands and their descriptions.
Every object (file, directory, commit) is stored by its SHA-256 hash:
.git/objects/ab/c123def456... ← File content stored here
↑↑ ↑↑↑↑↑↑↑
│ └─ Rest of hash (filename)
└───── First 2 chars (subdirectory)
Why this matters: Same content = same hash = automatic deduplication. Store README.md 100 times, uses disk space once.
Git tracks files through three conceptual "trees":
Working Directory → Staging Area (Index) → Repository (.git/objects)
(your files) (.git/index) (committed history)
go-git add moves files from working directory → staging area
go-git commit snapshots staging area → repository
Files are stored as blobs. Directories are stored as trees.
Example structure:
project/
README.md
src/
main.go
lib/
helper.go
Git stores this as:
Root Tree
├─ blob: README.md (hash: abc123)
└─ tree: src/ (hash: def456)
├─ blob: main.go (hash: ghi789)
└─ tree: lib/ (hash: jkl012)
└─ blob: helper.go (hash: mno345)
The trick: Trees must be built bottom-up (deepest first) because parent trees need their children's hashes.
Building order:
- Build
src/lib/tree (containshelper.go) → get hashjkl012 - Build
src/tree (containsmain.go+lib/tree with hashjkl012) → get hashdef456 - Build root tree (contains
README.md+src/tree with hashdef456) → done
This was the hardest part to implement. Understanding why trees reference other trees (not their contents) took multiple attempts.
A commit is just a pointer to a tree + metadata:
commit <size>\0
tree abc123def456... ← Snapshot of entire project
parent 789xyz... ← Previous commit (forms history chain)
author Uthman <email> timestamp
committer Uthman <email> timestamp
Initial commit
Commits form a directed acyclic graph (DAG):
C3 (HEAD) → C2 → C1 (root)
go-git log traverses this chain backwards from HEAD.
Every object (blob, tree, commit) follows this format:
<type> <size>\0<content>
Compressed with zlib, stored at .git/objects/<hash[:2]>/<hash[2:]>
Example - Blob:
blob 13\0Hello, World!
Hash this → a0b1c2d3... → Store at .git/objects/a0/b1c2d3...
Example - Tree:
tree 74\0100644 README.md\0<32-byte-binary-hash>040000 src\0<32-byte-binary-hash>
↑ ↑ ↑ ↑ ↑ ↑
mode name null byte mode name null + hash
Mode meanings:
100644= regular file040000= directory (tree object)
Critical detail: Hashes in tree objects are binary bytes, not hex strings. Took me an hour to debug this.
.git/index is a simple text file:
100644 abc123... README.md
100644 def456... src/main.go
100644 ghi789... src/lib/helper.go
Format: <mode> <hash> <path>
When you go-git add, we:
- Hash the file content → get blob hash
- Store blob in
.git/objects/ - Update index with path → hash mapping
Note: This implementation stores the index as plain text for simplicity. Real Git stores the index in a binary format for performance and to support additional metadata (timestamps, file sizes, etc.).
.git/refs/heads/main is a text file containing one line: the current commit hash.
abc123def456...
When you commit:
- Create tree from index
- Create commit pointing to that tree
- Update
.git/refs/heads/mainwith new commit hash
.git/HEAD points to the current branch:
ref: refs/heads/main
Deduplication: Identical files stored once (hash collision = same content)
Compression: zlib reduces object size by ~60-70%
Scalability: Linear time for add/commit operations
Not optimized for speed (built for learning), but functional for small-to-medium repos.
├── cmd/
│ └── cmd.go # CLI with Cobra (init, add, commit, log, config)
├── internals/
│ ├── init.go # Repository initialization
│ ├── config.go # User configuration (name/email)
│ ├── hash.go # SHA-256 hashing + zlib compression
│ ├── log.go # Commit history traversal
│ ├── index/
│ │ └── index.go # Staging area management
│ └── objects/
│ ├── blobs.go # File content hashing
│ ├── trees.go # Directory tree building
│ └── commit.go # Commit object creation
├── install.sh # Automatic installation script
└── main.go # Entry point
- Blobs (file hashing): Straightforward - read file, hash content, compress, store
- Staging area: Simple text file tracking path → hash mappings
- Commits: Just string formatting + hashing
1. Tree Building (5+ hours of debugging)
The problem: How do you build a tree for src/ when it contains a subdirectory lib/?
Initial attempt: Build trees top-down (root first). Failed - you don't have child tree hashes yet.
Solution: Build bottom-up (deepest directories first). But how do you know the order?
Final approach:
// Sort directories by depth (count slashes)
sort.Slice(dirs, func(i, j int) bool {
return strings.Count(dirs[i], "/") > strings.Count(dirs[j], "/")
})Then for each directory, check if any already-built trees are its children:
for subdir, hash := range treeHashes {
if filepath.Dir(subdir) == currentDir {
// This tree is a child - add it as an entry
entries = append(entries, Entry{
Filename: filepath.Base(subdir),
BlobHash: hash, // Use tree hash, not blob hash
FileMode: "040000" // Directory mode
})
}
}Why this was hard: Trees reference other trees by hash. You need to build children before parents so you have their hashes to reference. Took multiple attempts to understand this wasn't just "parse directories recursively."
2. Binary vs Hex Hash Encoding
Tree objects store hashes as 32 binary bytes, not 64-character hex strings.
Initial bug:
content += entry.BlobHash // Wrong! This is hex string (64 chars)Fix:
hashBytes, _ := hex.DecodeString(entry.BlobHash)
content = append(content, hashBytes...) // 32 binary bytesSymptom: Trees were twice as large as they should be. Debugging this took an hour because the error was subtle - Git could read the objects, but tree traversal was broken.
3. Excluding .git/ from staging
When you go-git add ., you don't want to add .git/objects/ to the index.
First attempt: Check if path contains .git. Failed - also excluded my.git.file.
Fix:
if d.Name() == ".git" && d.IsDir() {
return filepath.SkipDir // Skip entire directory
}Using filepath.SkipDir is the correct way to exclude directories during traversal.
Content-addressable storage is elegant: Hash = address. Same content = same hash = automatic deduplication. This is how Git handles millions of files efficiently.
Trees are graphs, not just nested structures: A tree object doesn't "contain" subtrees - it references them by hash. This indirection is what enables Git's efficiency (multiple commits can share the same tree if directory didn't change).
Building bottom-up is necessary, not optional: You can't hash a parent tree without knowing its children's hashes. The order matters fundamentally.
Go's filepath package is powerful: filepath.Walk, filepath.Dir, filepath.Base handle cross-platform path logic correctly. Don't reinvent this.
Compression matters: Without zlib, .git/objects/ would be 3-4x larger. Git uses compression everywhere.
Binary formats are tricky: Working with \0 null bytes and binary hash data required careful handling. Text formats would be easier but less efficient.
Currently manual testing via real usage. To test:
mkdir test-repo
cd test-repo
go-git init
go-git config
echo "test" > file.txt
go-git add file.txt
go-git commit -m "test commit"
go-git log # Should show your commitVerify objects:
ls -la .git/objects/ # Should see subdirectories with hashesThis is a learning project, not production software:
- No branches - Only
mainbranch exists - No merge - Can't combine commit histories
- No diff - Can't compare commits or working tree changes
- No status - Can't see modified/untracked files
- No remote operations - No push/pull/fetch
- No
.gitignore- Manual exclusion only - No packed objects - Each object is a separate file (Git packs them for efficiency)
- No index optimization - Linear scan on every operation
- Plain text index - Index stored as plain text instead of binary format (real Git uses binary for performance and metadata)
Why these limitations exist: This project focuses on Git's core - the object model, staging, and commits. Adding branches/merging/remotes would be another 2-3x the code and shift focus from fundamentals to features.
Most developers use Git daily but don't understand how it works internally. We type git add, git commit, and assume magic happens.
Building Git from scratch reveals:
- Why commits are cheap (just pointers to trees)
- How deduplication works (content-addressable storage)
- Why branching is fast (just moving a pointer)
- What "detached HEAD" actually means
- How merge conflicts arise (competing tree references)
The best way to understand a tool is to build it yourself.
This project taught me more about Git in a week than years of using it did.
- Go 1.25 - Core language
- Cobra - CLI framework
- fatih/color - Terminal colors
- Standard library only - All Git logic hand-written
No Git libraries used. Everything from hashing to object storage is custom implementation.
Built by Uthman | Portfolio | GitHub
Learning project focused on understanding version control internals