In this project, spell checker for English language is implemented.
The module named "spelling_corrector" tries to correct misspelled words in English.
Function which is named as "correct_word" will have single misspelled word and return at most five probable suggestions and their probabilities from your system:
correct_word(word)
The system is trained with Brown Corpus which has over one million tokens.
correct_word('said')
[('said',0.9902),('aids',0.0049),('maids',0.0049)]
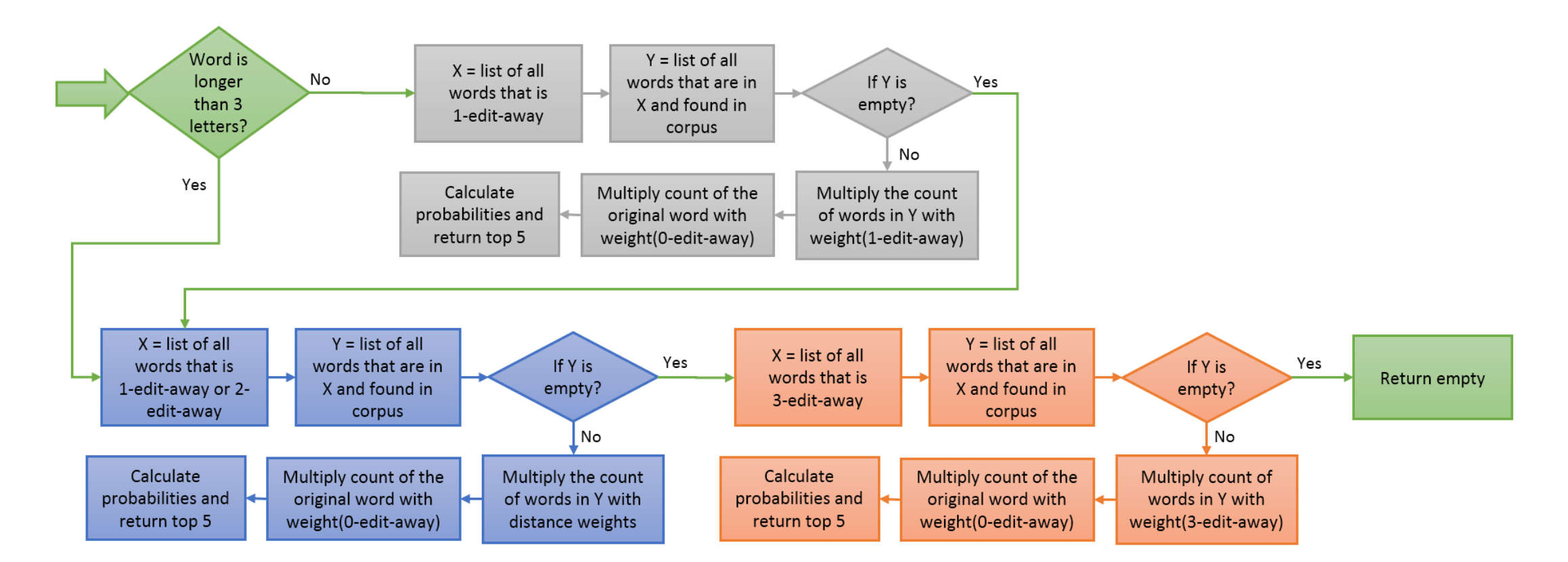
In this spell checker, the main idea is based on taking a word and creating possible variations of the word by deleting, inserting, transposing or replacing letters. After creating variations, their existence are checked at Brown corpus and their occurrences are weighted according to their distance to the original word. With this idea, if the original word is found on corpus without any modification, its probability is increased. On the other hand, as the distance from the original word increases, probability of seeing modified word is decreased.
While increasing and decreasing probabilities, numbers taken from Design of an interactive spell checker: optimizing the list of offered words is used. According to this paper where typing experiments are undertaken, probability of 1-edit-away is calculated as 94% and 2-edit-away is 5% and 3-edit-away is 1%. Using these percentages, counts of the created words are multiplied as following:

In addition, it is observed that short words can easily be converted to other words in 2 edits and those created words can be very popular in corpus. In such situations, very different words are suggested for correction. In order to eliminate this, when number of letters is less than 4, only 1-edit distance is considered.
Flow of operations is shown as a diagram:
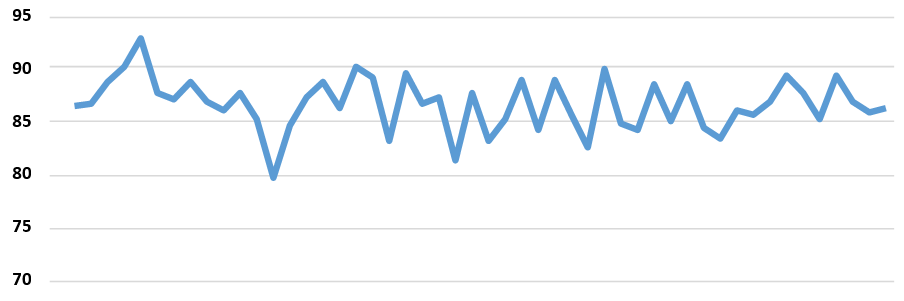
The method is quantitatively analyzed by a test file written for this purpose. When 1 point is given to the 1st suggestion, 0.8 to the 2nd and so on, the following statistics are found for a series of trials:

Moreover, positions of the correct suggestions are analyzed as following:
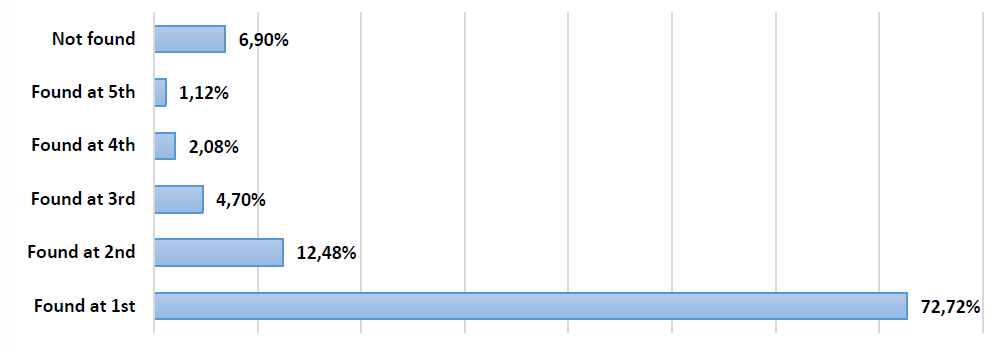
As can be seen from above figures, on the average model returns with 86 points out of 100 with a small standard deviation. In addition, at 70% of the time the model suggests the correct word at 1st location; on the other hand nearly at 7% the model fails to correct given word.
The main problem related to this model is that if a very popular word is created by manipulating the original word, it is returned as correction. For some cases, this suggestion is not acceptable. For instance,

In order to solve this problem, instead of one word, bigrams can be used so that a more meaningful suggestion can be provided.
Secondly, this implementation does not consider the role of the word in context. If there would be an improvement that considers the POS tag of the word, it could yield better solutions. For instance, where “take” is a verb, “the” is suggested by model. Likewise, where “have” is a verb, a pronoun “he” is suggested as correction.

In order to solve this problem, again not only the one word but also other words or the complete sentence is required.
The third problem of this model is the computational problems when 3-edit-away words are searched especially for long words. In some cases, computer can even freeze while listing 3-edit-away words. To solve this problem, number of words to create by 3 edits can be limited.
Considering the overall success level of 86 points, and 70% of correct suggestion at 1st location, when the possible problems are solved, this model can be used more effectively.