How to reduce code execution time using Python and Pytorch
When inferring I use 5 DL at ~25k. images simultaneously.
The script took about 4 hours to run.
The problem is that this is not a batch job that runs overnight...
Various people in the company required it to run "real time" several times a day.
Solution?
The first thing that might come to your mind is to start using some fancy optimizer (e.g. TensorRT).
Although it has to be done sometime...
First you should ask yourself:
- I/O bottlenecks: reading and writing images
- pre-processing and post-processing - can they be parallelized?
- are CUDA cores used to their maximum potential?
- is the bandwidth between CPU and GPU limited?
- can we move more calculations to the GPU?
Optimization
- interface samples were grouped
Batch batching is not only useful for training, but also significantly speeds up inference time.
Otherwise you will waste CUDA GPU cores.
Instead of going through models one sample at a time, I now process 64.
- Pytorch data loader used
This has 2 main advantages:
- parallel loading and preprocessing of data across multiple processes (NOT threads)
- copying input images directly to pinned memory (avoid CPU -> CPU copy operations)
- Moved most of the post-processing to the GPU
I saw that the tensor was moved too early on the CPU and mapped to the NumPy array.
I refactored the code to keep it on the GPU as much as possible, which had 2 main advantages:
- tensors are processed faster on GPU
- at the end of the logic I had smaller tensors, which resulted in smaller transfers between CPU and GPU
- Multi-threading for all my write IO operations
When dealing with I/O bottlenecks, using Python threads is extremely efficient.
I moved all my writes to 𝘛𝘩𝘳𝘦𝘢𝘥𝘗𝘰𝘰𝘭𝘌𝘹𝘦𝘤𝘶𝘵𝘰𝘳, grouping my writes.
Please note that I only used good old Python and PyTorch code.
When your code is poorly written, no tool will save you
Only now is the time to add fancy tools like TensorRT.
To optimize your PyTorch code by 82%:
- Inference samples were grouped
- The DataLoader module from PyTorch was used
- Moved most of the post-processing to the GPU
- Multi-threading for all my write I/O operations
Podczas wnioskowania używam 5 DL przy ~ 25 tys. obrazów jednocześnie.
Uruchomienie skryptu zajęło około 4 godzin.
Problem w tym, że nie jest to zadanie wsadowe uruchamiane przez całą noc...
Różni ludzie w firmie wymagali, aby działał on „w czasie rzeczywistym” kilka razy dziennie.
Rozwiazanie?
Pierwszą rzeczą, która może przyjść Ci do głowy, jest rozpoczęcie korzystania z jakiegoś wymyślnego optymalizatora (np. TensorRT).
Choć kiedyś trzeba to zrobić...
Najpierw powinieneś zadać sobie pytanie:
- Wąskie gardła we/wy: odczytywanie i zapisywanie obrazów
- przetwarzanie wstępne i przetwarzanie końcowe - czy można je zrównoleglić?
- czy rdzenie CUDA są wykorzystywane z maksymalnym potencjałem?
- czy przepustowość pomiędzy CPU i GPU jest ograniczona?
- czy możemy przenieść więcej obliczeń do GPU?
Optymalizacja
- pogrupowano próbki interfejsu
Grupowanie wsadowe jest nie tylko przydatne w szkoleniu, ale także znacznie przyspiesza czas wnioskowania.
W przeciwnym razie zmarnujesz rdzenie GPU CUDA.
Zamiast przeglądać modele po jednej próbce, przetwarzam teraz 64.
- Wykorzystywany moduł ładujący dane Pytorch
Ma to 2 główne zalety:
- równoległe ładowanie i wstępne przetwarzanie danych w wielu procesach (NIE wątkach)
- kopiowanie obrazów wejściowych bezpośrednio do przypiętej pamięci (unikaj operacji kopiowania procesora -> procesora)
- Przeniesiono większą część przetwarzania końcowego na GPU
Widziałem, że tensor został przeniesiony zbyt wcześnie na procesorze i zmapowany na tablicę NumPy.
Dokonałem refaktoryzacji kodu, aby jak najwięcej trzymać go na GPU, co miało 2 główne zalety:
- tensory są przetwarzane szybciej na GPU
- na koniec logiki miałem mniejsze tensory, co skutkowało mniejszymi transferami między CPU i GPU
- Wielowątkowość dla wszystkich moich operacji zapisu IO
W przypadku wąskich gardeł we/wy użycie wątków Pythona jest niezwykle wydajne.
Przeniosłem wszystkie moje zapisy do 𝘛𝘩𝘳𝘦𝘢𝘥𝘗𝘰𝘰𝘭𝘌𝘹𝘦𝘤𝘶𝘵𝘰𝘳, grupując moje operacje zapisu.
.
Pamiętaj, że użyłem tylko starego, dobrego kodu Python i PyTorch.
Gdy kod jest źle napisany, żadne narzędzie Cię nie uratuje
Dopiero teraz nadszedł czas na dodanie wymyślnych narzędzi, takich jak TensorRT.
Więc pamiętaj...
Aby zoptymalizować kod PyTorch o 82%:
- Pogrupowano próbki wnioskowania
- Wykorzystano moduł DataLoader firmy PyTorch
- Przeniesiono większość postprocessingu na GPU
- Wielowątkowość dla wszystkich moich operacji zapisu we/wy
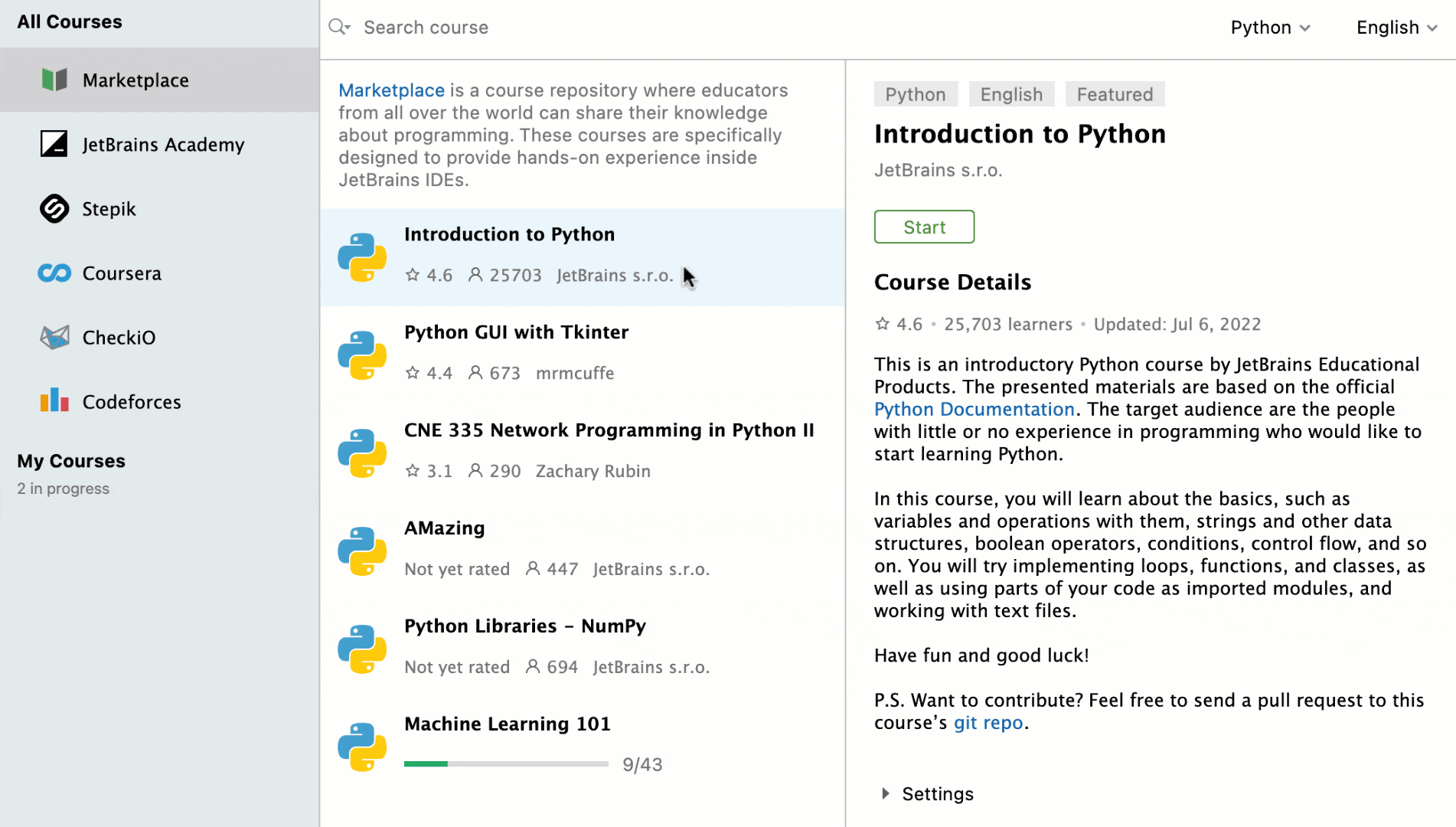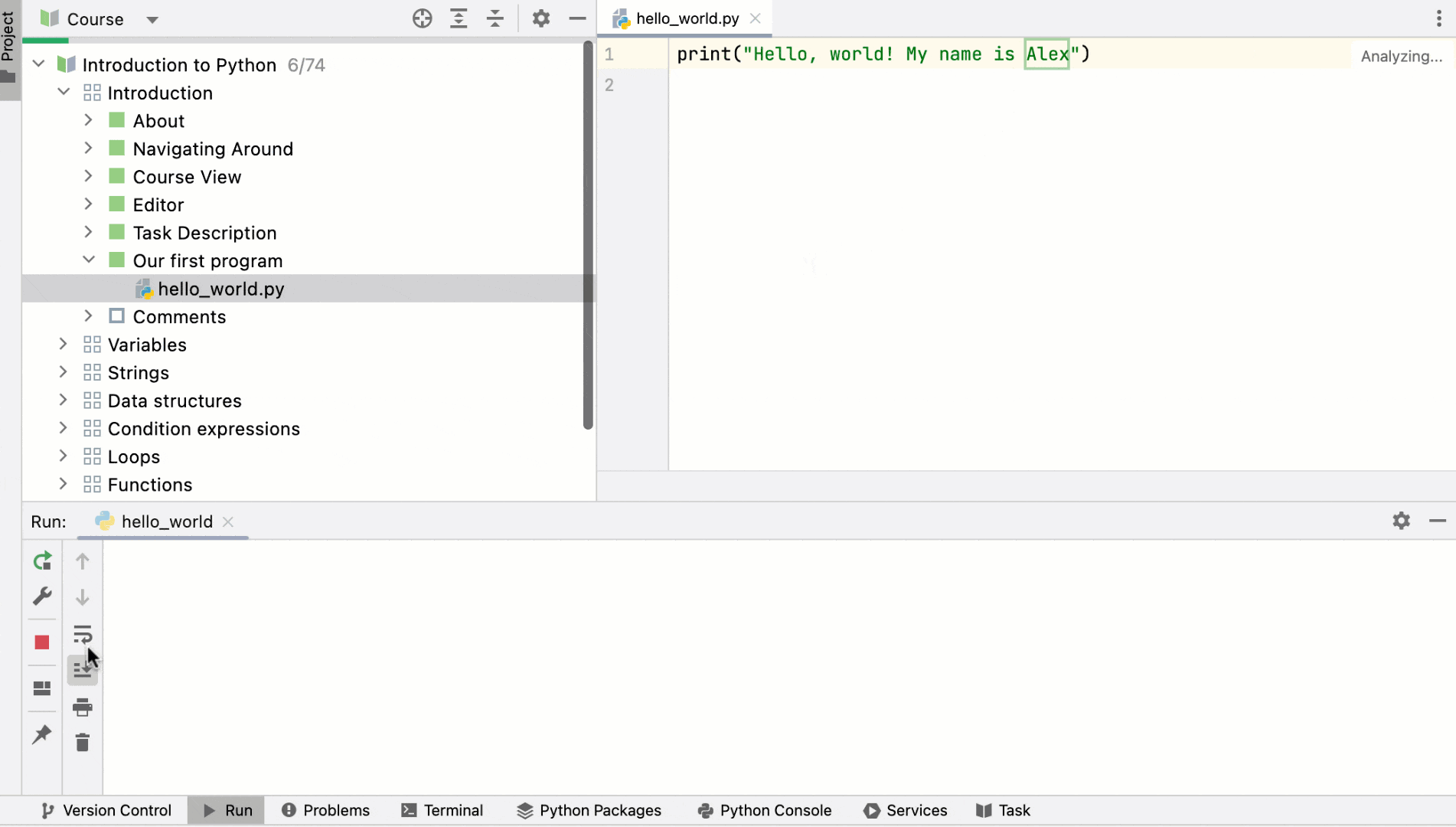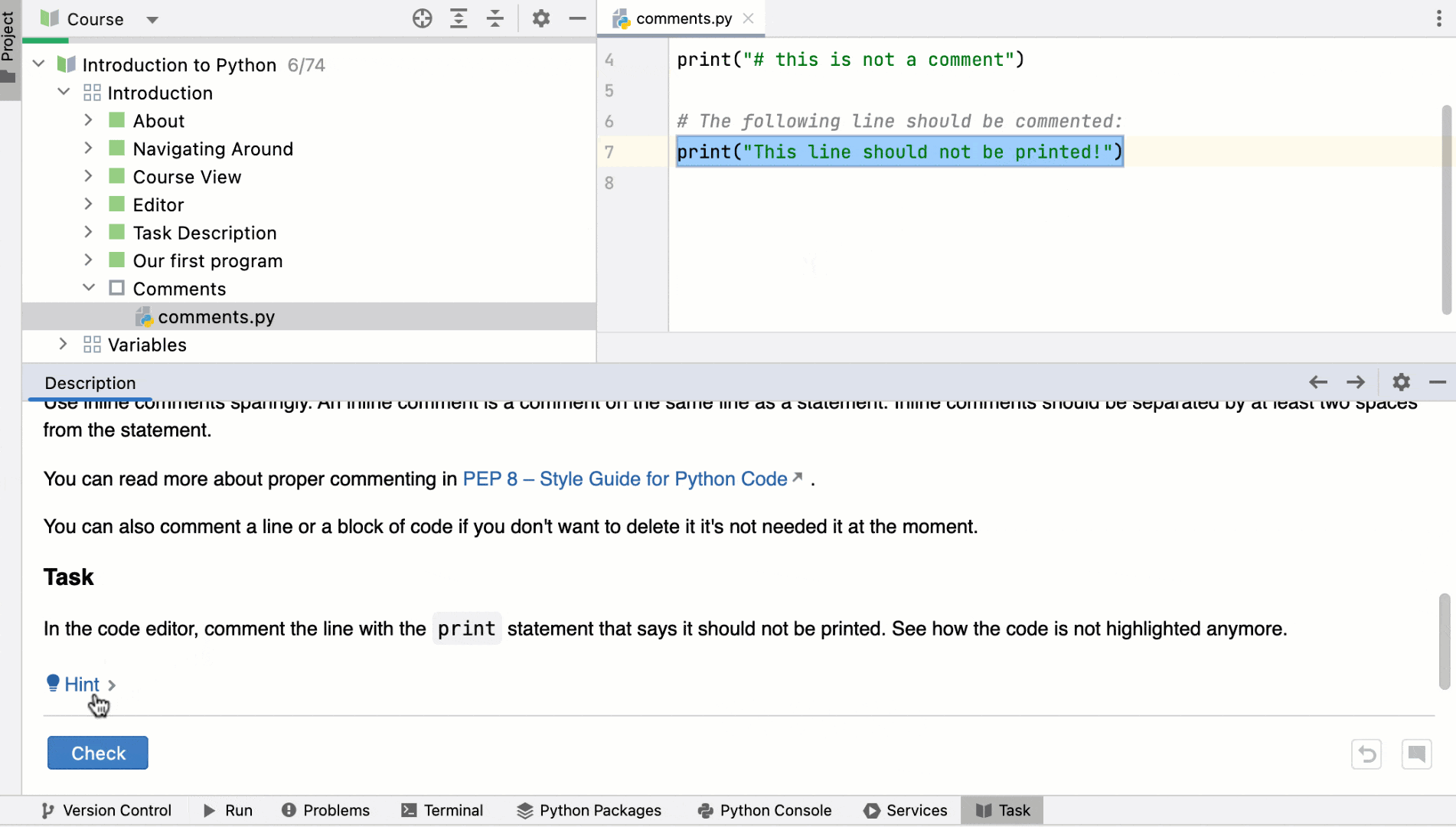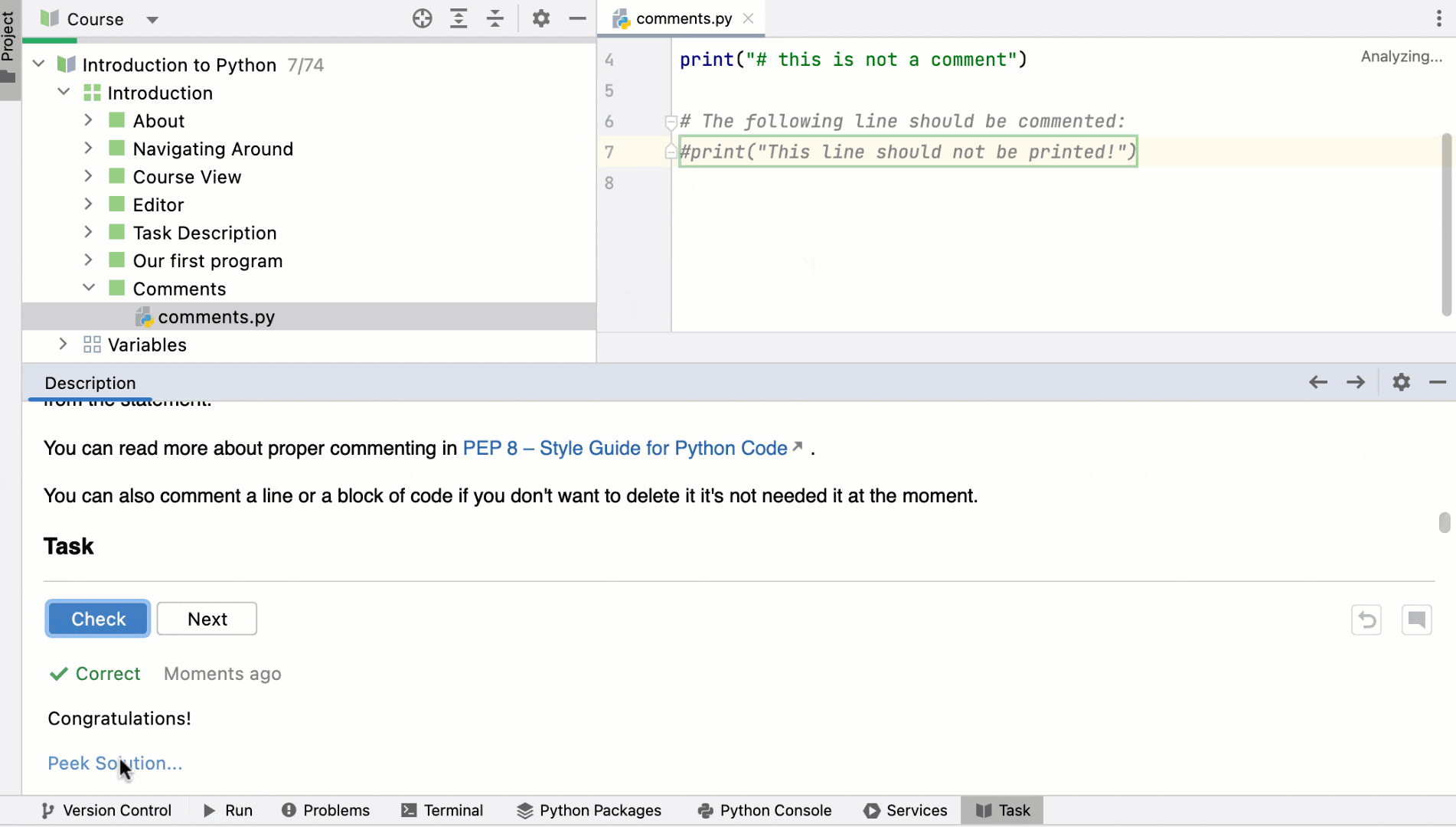
Learn Python with PyCharm for Education
in your IDE
Perfect your existing skills
Create educational courses
Solve coding challenges
Whether you are just starting with Python or you are ready to share your programming knowledge with others, you can do it right in the IDE.
Install PyCharm, go to the Learn tab, and click Enable Access. That’s it! You can now enjoy learning or teaching Python.
Study Python in a way you like! No matter whether you choose to follow a step-by-step course, build an application, or participate in a contest, you’ll learn Python while gaining experience with the IDE, which is a must for a career as a developer.
Choose courses based on your proficiency level and learn the basics of Python, or improve your skills in specific subjects like NumPy or Tkinter.
There is no way to learn programming without practice. In our courses, theory is followed by coding exercises to ensure that the concepts really stick.
Receive instant feedback on your assignments and get extra assistance with hints and helpful error messages whenever you feel like you are stuck on a task.
With the JetBrains Academy integration, you can learn Python by creating applications, such as your own spam filter, chat bot, and a simple search engine.
If you have experience in Python, challenge yourself with a Codeforces contest. Leverage PyCharm’s features to save some time and get ahead of the competition.
Our CheckiO integration provides gamified coding challenges that you can solve right in your IDEs. Select your proficiency level, start the game, and have fun!