Add logic to broadcast current scheduler info to workers in CLI #46
Conversation
|
Clearly I should have tested this locally first. :) I'll get a test setup going to fix these errors. |
|
Hi @lastephey ! Thanks for doing this. In principle this looks good to me, and seems to resolve the problem. I suspect that @kmpaul has thoughts though, and he may also be able to shed some light on the CI failures. I think that he only works M-Th though, so we may not hear back from him for the next day or two. |
|
I conda install openmpi or mpich on my personal linux machine for testing
dask-mpi
…On Mon, Dec 16, 2019 at 12:47 AM Laurie Stephey ***@***.***> wrote:
Hi @mrocklin <https://github.com/mrocklin> , thanks for the info! I'll
keep thinking about this and hopefully @kmpaul <https://github.com/kmpaul>
has some insight. One issue is that I don't have a great setup for
testing-- we can't use mpirun on Cori. Sorry for the noise from using your
web CI for troubleshooting.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#46?email_source=notifications&email_token=AACKZTGVDDNBFYDIT2AAE4TQY4QA3A5CNFSM4J2XY3Q2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEG5WA2I#issuecomment-565928041>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AACKZTCWGYBIUUGJMTZCEGDQY4QA3ANCNFSM4J2XY3QQ>
.
|
|
Thanks for the advice, I'll do that. |
|
@lastephey Thanks for looking at this! As @mrocklin pointed out, I have a short work schedule, so I couldn't respond until today. @mrocklin is correct. The best way to test is to do it via a conda install with |
|
So, these kinds of errors have come up quite frequently when running with MPI. The work-around has always been to disable the I'm going to look a little further to see if I can figure out what is happening. I've always suspected that MPI does not like it when you fork/spawn new processes from a running MPI process. If that is the case, then I think that maybe we need to always use the |
|
Thanks for looking into this @kmpaul . Oddly all the tests pass for me on my laptop using conda installed |
|
Interesting! I'm able to reproduce the errors both on my laptop and in a docker container. Have you checked out your development branch? |
|
Yes. I checked out the What kind of mpi are you using/how did you install it?
|
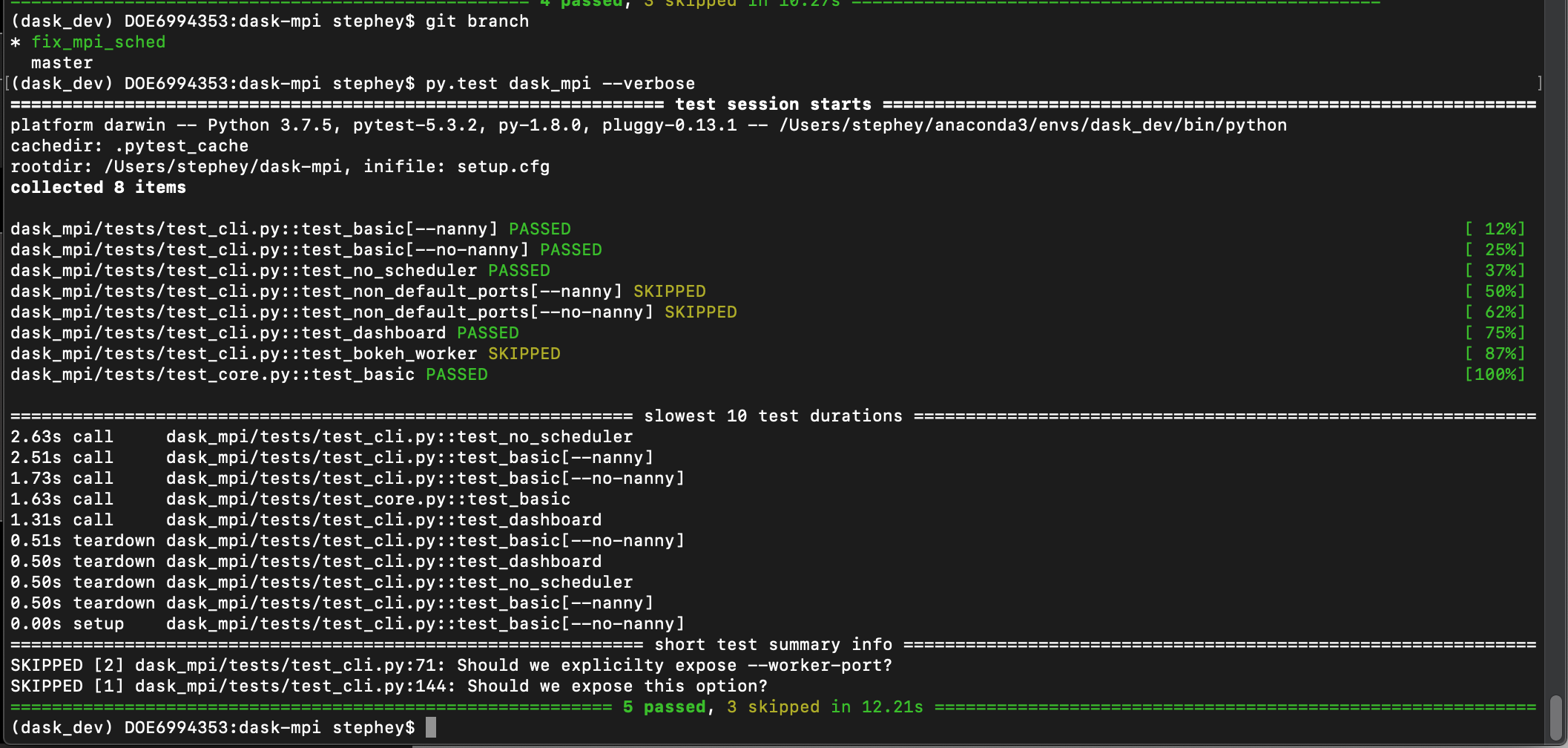
|
Everything is installed from the $ docker run -it continuumio/miniconda:latestAnd then from the container run: $ git clone https://github.com/lastephey/dask-mpi
$ cd dask-mpi
$ git checkout fix_mpi_sched
$ export PYTHON=3.6
$ export MPI=mpich
$ export ENV_NAME=dask-mpi-dev
$ .circleci/install.sh
$ conda activate dask-mpi-dev
$ pytest --verbose dask_mpi/tests/ |
|
Thanks @kmpaul . I followed your directions exactly except I needed to additionally But... this change in |
|
Looking at the |
|
Well, I've tried playing with these fixtures a bit but to no avail. Still hanging. I'm going to look more at this tomorrow. |
|
@lastephey Just so you know, I've had problems with the testing framework in the past. It has been challenging to test without problems. I believe you that the implementation in |
|
@kmpaul Thanks for your help with this. I'll try poking at it as well. |
|
@lastephey I believe I know what is happening. If you look at the dask-mpi/dask_mpi/tests/test_cli.py Lines 24 to 37 in de00068 What we want to do is change line 31 (of @mrocklin Perhaps you have some ideas on this? |
dask_mpi/cli.py
Outdated
| scheduler_address = comm.bcast(None, root=0) | ||
| dask.config.set(scheduler_address=scheduler_address) | ||
| comm.Barrier() |
There was a problem hiding this comment.
Again, you probably want to preface these lines with something like:
if not scheduler_file:There was a problem hiding this comment.
i also added this if not scheduler_file and it causes the program to hang. i believe we want to send the scheduler info no matter what, so i'm going to leave this out.
| cmd = mpirun + ["-np", "4", "dask-mpi", "--scheduler-file", fn, nanny, "&"] | ||
|
|
||
| with popen(cmd): | ||
| with Client(scheduler_file=fn) as c: |
There was a problem hiding this comment.
Line 31, above, is the culprit line causing the tests to hang. It is in this line that the distributed.Client is being initialized and told to find the Scheduler by looking up the address parameter in the scheduler_file. The scheduler_file (called fn in this test) is not being used by dask-mpi, so no information is being written to the scheduler_file from the Scheduler. Hence, the Client keeps waiting and doesn't know how to find and connect to the Scheduler.
It is unclear to me how this should change if the Scheduler uses an MPI broadcast to tell the Workers to what address to connect. The Client is left out of the broadcast, and so has no means of knowing where the Scheduler is located. (This is different in the core.py code, where the Client's process actually participates in the broadcast, and therefore knows where to the Scheduler is located.)
The correct solution to this problem probably requires some discussion.
There was a problem hiding this comment.
I might also note that when you run dask-mpi by hand, as is commonly done, then you can get the address of the Scheduler from the log messages, and you can connect your Client to that. In this case, though, when you are automating the launch of dask-mpi in the test, the only way I know of getting the Scheduler address is (1) through a scheduler_file or (2) scrubbing STDOUT (or the log file) from the Scheduler process to find the address. Option (1) defeats the purpose of using the MPI broadcast, and Option (2) seems messy to me.
There was a problem hiding this comment.
There was a problem hiding this comment.
You are more than welcome, @lastephey! And I very much appreciate your PR. Help on OSS is always appreciated. 😄
I wouldn't call this a corner case. The difficulty in getting this test to pass with the previous code changes was a sign that something was wrong. And the issue was that by using an MPI broadcast to send the scheduler info to the workers, there was no way to also send the scheduler info to the client (i.e., the client created in the test). Not without using a scheduler_file, and the use of a scheduler_file seems redundant if you are using an MPI broadcast.
Codecov Report
@@ Coverage Diff @@
## master #46 +/- ##
==========================================
+ Coverage 96% 96.15% +0.15%
==========================================
Files 3 3
Lines 75 78 +3
==========================================
+ Hits 72 75 +3
Misses 3 3
Continue to review full report at Codecov.
|

There was a problem hiding this comment.
I am afraid I am not understanding why you want to implement these changes, now. I think I need to better understand why you need to MPI broadcast the scheduler info to the workers and save the scheduler info in a scheduler_file. Since both of these methods allow the workers to find the scheduler, only one is needed. Correct?
There also exists another issue (which I've alluded to in previous comments on this PR) of how do you send the scheduler info to the client (not just the workers). Both the workers and the client can get the scheduler info from the scheduler_file. However, only the workers will get the scheduler info from an MPI broadcast. (This is why the existing tests in test_cli.py hang.)
If you want to use an MPI broadcast to communicate the scheduler info to both the workers and the client, then you have to have the client process started via mpirun in the same way that the scheduler and worker processes are started. This functionality already exists in the dask_mpi.core.initialize method.
If communicating the scheduler info to the client isn't something you need or care about, then I can see modifying the dask-mpi CLI to use either a scheduler_file or an MPI broadcast to communicate the scheduler info to the workers. If that is indeed what you want, then you need to have a way of disabling the scheduler_file approach in the code (currently, it is always enabled). You would also need to add a test or two for the new MPI broadcast only approach...and as I've mentioned before, I'm not sure how to write those tests because you would need a client (in the test) to find the scheduler.
Are my concerns clear? Am I misunderstanding something? I really appreciate the PR, and I don't mean to be difficult. I'm just afraid I'm misunderstanding your goal.
dask_mpi/cli.py
Outdated
| scheduler_address = comm.bcast(None, root=0) | ||
| dask.config.set(scheduler_address=scheduler_address) | ||
| comm.Barrier() |
|
Hi @kmpaul I think we are approaching this problem from two different viewpoints. I think you are viewing the client as a part of the cluster (hence assigning it to rank=1 in core.py) and we would prefer to run the client separately for ease of viewing the dashboard on our shared system. This is why we wanted to use MPI to sync the scheduler info between the scheduler and the workers, but continue to use the To give you an idea of how we are using dask-mpi at NERSC at the moment, you can check out some of @rcthomas notebooks: https://gitlab.com/NERSC/nersc-notebooks/tree/master/dask Does this help make our motivation more clear? Of course if there is a better way to make our setup work, we are open to suggestions. |
|
@lastephey Ok. I'm very sorry for missing the reason for wanting both a However, I still don't think you actually need to MPI broadcast. I think you just need some appropriately placed MPI Barriers to make sure that the Scheduler has started (and wrote the new |
|
If you could accomplish this with just MPI Barriers, then it might be nice to add a test demonstrating the problems you experience with lingering stale |
|
@kmpaul ok good, I'm glad we are on the same page. We should have been more clear about our setup-- sorry for the confusion. Yes I think appropriately placed barriers would do just as well. Let me try to get that working and I'll add a stale scheduler file unit test, too. |
|
Cool! Again, I'm really sorry for all the confusion. I feel like I just asked you to do a bunch of work that may not be necessary at all. Sorry. I would hate to have done that. My first thoughts might be to just remove the Tricky problem, but I think we might be narrowing on the solution. 😄 |
|
The barrier solution seems to work ok even without the asyncio sleep, so i left it out. I'll work on the unit test now. |
|
I have no idea why the tests failed before and passed now. I didn't make any meaningful changes. |
|
Yeah. That's very weird, but I've seen instabilities in MPI CI testing before. I've never fully understood why this happens. |
|
ok thanks @kmpaul ! do you want the new unit test as a new PR? |
|
Ach! Sorry. I was trigger happy. Yes. Another PR would be great. |
|
Hi @kmpaul, just wondering if you're planning a release any time soon? I see the last release was Oct 2019 and this patch went in Jan 2020. It would be great to have a release install of installing from a commit. |
|
@lastephey: This is now done. Version 2.21.0 of dask-mpi is released on PyPI and conda-forge. |
|
...though the conda-forge release may take a bit to propagate out. Should be available for download soon. |
|
Thank you very much for the fast turnaround! |
|
You're welcome. 😄 I wish I could be this fast all the time. |
This PR addresses the problem described in @rcthomas issue #45
I think there was some confusion in this issue-- at NERSC our idea at the moment is to recommend that our users start Dask via the dask-mpi CLI (which never touches core.py, as far as we can tell.)
This PR implements the same logic in cli.py that already exists in core.py. It first starts the scheduler and then broadcasts the scheduler address to the workers before they can start. This behavior prevents the workers from reading an old scheduler.json file (which may have been left behind after a non-clean exit) and then hanging while they try to connect to a scheduler which does not exist.