By David Durkin
Implementation
// memoryleak.cpp: where is my mind
#include <cassert>
#include <cstdlib>
#include <ctime>
#include <algorithm>
#include <iostream>
#include <utility>
const int NITEMS = 1<<10;
const int TRIALS = 100;
using namespace std;
template <typename T>
class Array {
public:
typedef T* iterator;
// Constructor
Array(const int n = 0) : length(n), capacity(n ? n : 8), data(new T[capacity]) {}
// Destructor
~Array() { delete [] data; }
// Copy Constructor
Array(const Array<T>& other) : length(other.length), capacity(other.capacity), data(new T[capacity]) {
copy(other.data, other.data + length, data);
}
// Assignment Operator
Array<T>& operator=(Array<T> other) {
swap(other); // Copy and swap idiom
return *this;
}
// Swap method
void swap(Array<T>& other) {
std::swap(length, other.length);
std::swap(capacity, other.capacity);
std::swap(data, other.data);
}
void push_back(const T &value) {
if (length >= capacity) { // Check capcity and grow
capacity = capacity * 4 / 3;
T *tmp = new T[capacity];
copy(data, data + length, tmp);
delete [] data;
data = tmp;
}
data[length] = value;
length++;
}
const size_t size() const { return length; }
T& operator[](const int i) { return data[i]; }
iterator begin() { return data; }
iterator end() { return data + length; }
private:
size_t length;
size_t capacity;
T* data;
};
bool duplicates(int n) {
Array<int> randoms;
for (int i = 0; i < NITEMS; i++) {
randoms.push_back(rand() % 1000);
}
for (int i = 0; i < n; i++) {
if (find(randoms.begin(), randoms.end(), randoms[i]) != randoms.end()) {
return true;
}
}
return false;
}
void array_test() {
Array<int> a0;
for (int i = 0; i < NITEMS; i++) {
a0.push_back(rand() % 1000);
}
Array<int> a1(a0);
for (int i = 0; i < NITEMS; i++) {
assert(a0[i] == a1[i]);
}
Array<int> a2;
a2 = a0;
for (int i = 0; i < NITEMS; i++) {
assert(a0[i] == a2[i]);
}
}
int main(int argc, char *argv[]) {
srand(time(NULL));
for (int i = 0; i < TRIALS; i++) {
if (duplicates(NITEMS)) {
cout << "Duplicates Detected!" << endl;
}
}
array_test();
return 0;
}
- An array with dynamic memory management
Attributes:
- size()
- operator[](i)
Modification:
- insert(it, val)
- push_back(val)
- erase(it)
- a sequence container consisting of nodes linked by reference to other nodes
Implementation
/ linked_list_raii.cpp: Singly Linked List (RAII)
#include <cstdlib>
#include <iostream>
#include <stdexcept>
const int NITEMS = 10;
// List declaration ------------------------------------------------------------
template <typename T>
class List {
protected:
struct Node {
T data;
Node *next;
};
typedef Node * iterator;
Node *head;
size_t length;
public:
List() : head(nullptr), length(0) {}
iterator front() { return head; };
~List(); // Destructor
List(const List<T> &other); // Copy Constructor
List<T>& operator=(List<T> other); // Assignment Operator
void swap(List<T> &other); // Utility
size_t size() const { return length; }
T& at(const size_t i);
void insert(iterator it, const T &data);
void push_back(const T &data);
void erase(iterator it);
};
// List implementation --------------------------------------------------------
// Post-condition: Clears all nodes from list
template <typename T>
List<T>::~List() {
Node *next = nullptr;
// Need next otherwise invalid reads (use valgrind)
for (Node *curr = head; curr != nullptr; curr = next) {
next = curr->next;
delete curr;
}
}
// Post-condition: Copies all nodes from other
template <typename T>
List<T>::List(const List<T> &other)
: head(nullptr), length(0) {
for (Node *curr = other.head; curr != nullptr; curr = curr->next) {
push_back(curr->data);
}
}
// Post-condition: Clears existing list and copies all nodes from other
template <typename T>
List<T>& List<T>::operator=(List<T> other) {
swap(other);
return *this;
}
template <typename T>
void List<T>::swap(List<T> &other) {
std::swap(head, other.head);
std::swap(length, other.length);
}
template <typename T>
T& List<T>::at(const size_t i) {
Node *node = head;
size_t n = 0;
while (n < i && node != nullptr) {
node = node->next;
n++;
}
if (node) {
return node->data;
} else {
throw std::out_of_range("invalid list index");
}
}
template <typename T>
void List<T>::insert(iterator it, const T& data) {
if (head == nullptr && it == nullptr) {
head = new Node{data, nullptr};
} else {
Node *node = new Node{data, it->next};
it->next = node;
}
length++;
}
template <typename T>
void List<T>::push_back(const T& data) {
if (head == nullptr) {
head = new Node{data, nullptr};
} else {
Node *curr = head;
Node *tail = head;
while (curr) {
tail = curr;
curr = curr->next;
}
tail->next = new Node{data, nullptr};
}
length++;
}
template <typename T>
void List<T>::erase(iterator it) {
if (it == nullptr) {
throw std::out_of_range("invalid iterator");
}
if (head == it) {
head = head->next;
delete it;
}
else {
Node *node = head;
while (node != nullptr && node->next != it) {
node = node->next;
}
}
if (node == nullptr) {
throw std::out_of_range("invalid iterator");
}
node->next = it->next;
delete it;
}
length--;
}
Attributes:
- size()
Access:
- at()
Modification:
- insert(it, val)
- push_back(val)
- erase(it)
Problems:
- special cases for empty Lists
- push_back is O(n)
- can only insert at the end (unless there is a tail pointer)
- Erase is O(n)
Doubly linked lists are the same but instead have a pointer to both next and previous
- ADT
- LIFO
Operations:
- push(value) inserts an element at the top
- pop() delete an element from the top
- top() access an element at the top
- empty() whether or not there are any elements
Array implementation:
- top of stack is back of the Array
- array must be dynamic to prevent overflow
Linked list implementation:
- top of the stack is the front of the list
template <typename T>
class vector_stack {
std::vector<T> data;
public:
bool empty() const { return data.empty(); }
const T& top() const { return data.back(); }
void push(const T& value) {
data.push_back(value);
}
void pop() {
data.pop_back();
}
};
- ADT
- FIFO
Operations:
- push(value) insert an element at the back
- pop() delete an element at the front
- front() access an element at the front
- empty()
Array Implementation:
- cant efficiently push/pop the front
- need to keep track of front and back index
- alternative: start in the middle til the end is reached then resize or shift
Linked List Implementation:
- can't efficiently push or pop at the back with a singly linked List
- need a tail pointer to push at the back
- need doubly-linked to pop at the back of the list
Implementing a Queue with two Stacks
template <typename T>
class stack_queue {
std::stack<T> in, out;
void in_to_out() {
while (!in.empty()) {
out.push(in.top());
in.pop();
}
}
public:
bool empty() const { return in.empty() && out.empty(); }
const T& front() {
if (out.empty()) in_to_out();
return out.top();
}
const T& back() const { return in.top(); }
void push(const T& value) {
in.push(value);
}
void pop() {
if (out.empty()) in_to_out();
out.pop();
}
};
Operations:
- push_{front,back}(value) Insert an element at front/back
- pop_{front,back}() Delete the element at the front/back
- front() Access element at the front
- back() Access element at the back
- empty() Whether or not queue has any elements
In STL, deque is nether a linked list or an dynamic array. Linked lists don't have proper locality and dynamic arrays invalidate pointers when resizing and it is difficult to find a sizable contiguous block in memory
- ADT
Ordered collections which support some sort of select Operation
- select(i) returns the (i+1)th smallest element
Operations:
- push(value) Insert value into collection
- pop() Erase the largest element
- top() Return the largest element
- empty() Whether or not queue has any elements
No real diffference in complexity for array vs linked list implementations priority_queue pq; <- STL
Rules:
- Entry contained by a node is never less than either of the nodes children
- Tree is a complete binary tree
- Every level except the lowest is completely filled
Push (aka reheapification upward):
- Place new entry in first available location (completeness)
- While the new entry's parent is less than the new entry, swap the two nodes (ordering)
Pop (aka reheapification downward):
- Save the top of the Heap (pop from the top)
- Move the last entry to the root
- while the out-of-place entry is less than one of its children, swap the top entry with the highest child
- return the saved top
Properties:
- Consists of linked nodes
- each node has exactly one parent
- each node has links to up to two children
- each node has no more than one sibling
- top most node = root
- bottom most modes = leaves
- Depth = number of steps away from the root
- FULL tree = every leaf has the same depth and every non leaf has two children.
- COMPLETE tree = every level except the deepest has the max amount of nodes.
Array Implementation:
- Breadth first order: root, children, grandchildren etc.
- Traversal equations:
- Parent(i) = floor((i-1)/2)
- Left Child(i) = 2i+1
- Right Child(i) = 2i+2
Node Implementation
- Each node has a pointer to a left and right child node
struct Node{
T data;
Node *left;
Node *right;
}
Traversals
Bui's Slides
-
Breadth-First
-
Travels through the tree horizontally from left to right
-
Implementation (using a queue) :
- python
BFS(root): # Level-by-level Queue q q.push(root) while not q.empty(): n = q.pop() print n if n.left: q.push(n.left) if n.right: q.push(n.right)- C++
template <typename T> void bfs(Node<T> *root) { queue<Node<T>*> q; q.push(root); while (!q.empty()) { auto n = q.front(); q.pop(); cout << n->data << " "; if (n->left) q.push(n->left); if (n->right) q.push(n->right); } cout << endl; }
-
-
Depth-First
-
Starts at the root and travels as far as possible downwards before backtracking
-
Implementation (using a stack) :
- Python
DFS(root): Stack s s.push(root) while not s.empty(): n = s.pop() print n # Pre-Order if n.right: s.push(n.right) if n.left: s.push(n.left)- C++
template <typename T> void dfs(Node<T> *root) { stack<Node<T>*> s; s.push(root); while (!s.empty()) { auto n = s.top(); s.pop(); cout << n->data << " "; if (n->right) s.push(n->right); if (n->left) s.push(n->left); } cout << endl; }
-
-
Depth-First (recursive)
-
Implementation:
- Python
DFS_Recursive(root): if not root: return print root if root.left: DFS_Recursive(root.left) if root.right: DFS_Recursive(root)- C++
template <typename T> void dfs_recursive(Node<T> *root) { if (root == nullptr) { return; } cout << root->data << " "; if (root->left) dfs_recursive(root->left); if (root->right) dfs_recursive(root->right); }
-
General Traversals
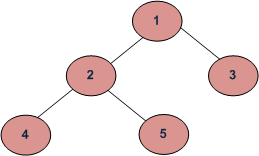
(all depth-first)
A. inorder
- Traverse the left subtree, i.e., call Inorder(left-subtree)
- Visit the root.
- Traverse the right subtree, i.e., call Inorder(right-subtree)
Result: 42513
C Code:
void printInorder(struct node* node)
{
if (node == NULL)
return;
/* first recur on left child */
printInorder(node->left);
/* then print the data of node */
printf("%d ", node->data);
/* now recur on right child */
printInorder(node->right);
}
B. preorder
- Visit the root.
- Traverse the left subtree, i.e., call Preorder(left-subtree)
- Traverse the right subtree, i.e., call Preorder(right-subtree)
Result: 12453
C Code:
void printPreorder(struct node* node)
{
if (node == NULL)
return;
/* first print data of node */
printf("%d ", node->data);
/* then recur on left sutree */
printPreorder(node->left);
/* now recur on right subtree */
printPreorder(node->right);
}
C. postorder
- Traverse the left subtree, i.e., call Postorder(left-subtree)
- Traverse the right subtree, i.e., call Postorder(right-subtree)
- Visit the root.
Result: 45231
C Code:
void printPostorder(struct node* node)
{
if (node == NULL)
return;
// first recur on left subtree
printPostorder(node->left);
// then recur on right subtree
printPostorder(node->right);
// now deal with the node
printf("%d ", node->data);
}
Good:
- efficient insert, erase, and search
- straight forward implementation
Bad:
- No balancing mechanism
- poor data locality
A generalization of a BST, but improving upon the negatives of a BST in that a node can:
- Have more than two children (more balanced)
- Contain more than just a single entry (data locality)
Used often in files systems and databases
Every node meets the following invariants:
- At least MINIMUM entries and MINIMUM+1 children (except root)
- At most 2MINIMUM entries and 2MINIMUM+1 children
- Entries of each node stored in a sorted array
- An entry at index i is greater than all the entries in subtree i of the node and an entry at index i is less than all the entries in subtree i + 1
- Every leaf has same depth
Properties
- A b-tree node grows/shrinks at the root
- Best, average, worst case all O(log(n))
- However, managing a B-Trees internal structure is complicated and takes up a lot of space
Good
- Efficient insert, search, erase
- good data locality
Bad
- complex balancing mechanisms
- potentially wasteful memory usage
Essentially a B-Tree overlayed on top of a BST
Combine the guarantees of a B-Tree with the compact structure of a BST
Invariants
- Every B-node is a 2-node, a 3-node, or a balanced 4-node
- Every path has the same number of B-nodes
- The root is black
- No path has two red nodes in a row i.e. Every red node has two black children
- Every path has the same number of black nodes
Rotation

Inverts the parent/child relationship. Swap position and color.
Combination of a BST and a max binary heap
Properties
- each node has a value and a randomly assigned priority
- uses the value to form a binary search tree, and the priority to form a max binary heap
- with a uniform distribution, the resulting tree should be relatively balanced
Invariants
- Each node's value maintains the Binary Search Tree invariants
- Each node's value is never less than any value in the left subtree
- Each node's value is always less than any value in the right subtree
- Each node's priority maintains the Max Binary Heap invariants
- Each node's value is always greater than the values in its children
Insert
- Perform standard Binary Search Tree insertion
- When location is found, create new Node with given value and random priority
- Use rotations to ensure inserted node's priority follows Max Binary Heap property
Erase
- Find the node to be deleted as in Binary Search Tree
- If node is a leaf, just delete it
- Otherwise, replace replace node's priority with minus infinite (-INF), and do appropriate rotations to bring the node down to a leaf and then delete it.
Best, average: O(log(n)) Worst: O(n)
Treaps probabilistically balance binary search trees by overlaying a max binary heap
Data Structures and their sorting algorithms
Unsorted Array == Selection Sort
Sorted Array == Insertion Sort
Binary Heap == Heap Sort
Algorithm
Moving from back to front:
- Search for the largest element
- Swap largest element with one at the back
- Reset back to next last element
Original: 5 4 7 0 1
1st Pass: 5 4 1 0 7 // 7 is largest and swaps with back 1
2nd Pass: 0 4 1 5 7 // 5 is largest and swaps with back 0
3rd Pass: 0 1 4 5 7 // 4 is largest and swaps with back 1
4th Pass: 0 1 4 5 7 // 1 is largest and already in place
Array Implementation
void selection_sort(int a[], size_t n) {
if (n <= 1) return;
for (int back = n - 1; back > 0; back--) {
int largest = 0;
for (int i = 1; i <= back; i++)
if (a[i] > a[largest])
largest = i;
swap(a[largest], a[back]);
}
}
Best and Worst Case: O(n^2)
Not Stable
Algorithm
For each slot in the array, starting from the next element and moving til the end:
- From the current element to the front of the array,
- Shift the element as long as Current < Next
Original: 5 4 7 0 1
1st Pass: 4 5 7 0 1 // 4 is shifted
2nd Pass: 4 5 7 0 1 // 7 is already in place, so do nothing
nothing
3rd Pass: 0 4 5 7 1 // 0 is shifted
4th Pass: 0 1 4 5 7 // 1 is shifted
Array Implementation
void insertion_sort(int a[], size_t n) {
if (n <= 1) return;
for (size_t back = 1; back < n; back++) {
for (size_t i = back; i > 0 && a[i] < a[i - 1]; i--) {
swap(a[i], a[i - 1]);
}
}
}
Best Case (If sorted or almost sorted): O(n), Worst Case: O(n^2)
Stable
Algorithm
- Convert container into a heap (Heapify)
- While there are still elements unsorted
- swap first element (max) with last unsorted
- reheapify down the heap portion
- decrement unsorted
- Continually pop the heap to keep number towards the back
Original: 5 4 7 0 1
0th Pass: 7 4 5 0 1 // Heapify original
1st Pass: 5 4 1 0 7 // Pop 7 & Re-heapify Down
2nd Pass: 4 0 1 5 7 // Pop 5 & Re-heapify Down
3rd Pass: 1 0 4 5 7 // Pop 4 & Re-heapify Down
4th Pass: 0 1 4 5 7 // Pop 1 & Re-heapify Down
Array Implementation
void heap_sort(int a[], size_t n) {
if (n <= 1) return;
make_heap(a, a + n);
for (size_t unsorted = n; unsorted > 1; unsorted--) {
pop_heap(a, a + unsorted);
}
}
Best and Worst Case: O(log(n))
Not Stable
Algorithm
- Divide the elements to be sorted into two groups of equal (or almost equal) size
- Sort each of these smaller groups of elements (recursively)
- Merge the two sorted groups into one large sorted list
Bui's Linked List Implementation
// merge.cpp
#include "lsort.h"
#include <iostream>
// Prototypes
Node *msort(Node *head, CompareFunction compare);
void split(Node *head, Node *&left, Node *&right);
Node *merge(Node *left, Node *right, CompareFunction compare);
// Implementations
void merge_sort(List &l, bool numeric) {
auto compare = (numeric ? node_number_compare : node_string_compare);
l.head = msort(l.head, compare);
}
Node *msort(Node *head, CompareFunction compare) {
Node *left;
Node *right;
// Base case: single node
if (head == nullptr || head->next == nullptr) {
return head;
}
// Divide list into left and right
split(head, left, right);
// Conquer left and right sublists
left = msort(left, compare);
right = msort(right, compare);
// Combine by merging left and right
head = merge(left, right, compare);
return head;
}
void split(Node *head, Node *&left, Node *&right) {
Node *slow = head;
Node *fast = head;
Node *tail = head;
while (fast && fast->next) {
tail = slow;
slow = slow->next;
fast = fast->next->next;
}
tail->next = nullptr;
left = head;
right = slow;
}
Node *merge(Node *left, Node *right, CompareFunction compare) {
Node *head;
Node *next;
if (compare(left, right)) {
head = left;
left = left->next;
} else {
head = right;
right = right->next;
}
Node *tail = head;
while (left && right) {
if (compare(left, right)) {
next = left;
left = left->next;
} else {
next = right;
right = right->next;
}
tail->next = next;
tail = next;
}
tail->next = (left ? left : right);
return head;
}
// vim: set sts=4 sw=4 ts=8 expandtab ft=cpp:
Observations
- Algorithm works top-down (post-order traversal)
- End recursion when we have 1 element
- If we split incorrectly (unevenly), then we get insertion sort
- Merge requires O(n) extra space
- Does not require random access
Best, worst case: O(log(n))
Stable
Algorithm
- Select a pivot that divides array in two
- Partition array so elements <= pivot are in the left subarray and elements >= pivot are in the right subarray
- Sort the two subarrays recursively
Bui's Linked List Implementation
// quick.cpp
#include "lsort.h"
#include <iostream>
// Prototypes
Node *qsort(Node *head, CompareFunction compare);
void partition(Node *head, Node *pivot, Node *&left, Node *&right, CompareFunction compare);
Node *concatenate(Node *left, Node *right);
// Implementations
void quick_sort(List &l, bool numeric) {
auto compare = (numeric ? node_number_compare : node_string_compare);
l.head = qsort(l.head, compare);
}
Node *qsort(Node *head, CompareFunction compare) {
Node *left;
Node *right;
// Base case: single node
if (head == nullptr) {
return head;
}
// Partition
partition(head->next, head, left, right, compare);
// Conquer left and right sublists
left = qsort(left, compare);
right = qsort(right, compare);
// Combine lists
head->next = right;
return concatenate(left, head);
}
void partition(Node *head, Node *pivot, Node *&left, Node *&right, CompareFunction compare) {
Node *next;
left = nullptr;
right = nullptr;
for (auto curr = head; curr != nullptr; curr = next) {
next = curr->next;
if (compare(curr, pivot)) {
curr->next = left;
left = curr;
} else {
curr->next = right;
right = curr;
}
}
}
Node *concatenate(Node *left, Node *right) {
if (left == nullptr) {
return right;
}
Node *tail = nullptr;
for (auto curr = left; curr != nullptr; curr = curr->next) {
tail = curr;
}
tail->next = right;
return left;
}
// vim: set sts=4 sw=4 ts=8 expandtab ft=cpp:
Observations
- End recursion when we have 1 element
- Selecting pivot is key to efficiency
- Unlucky partitioning causes algorithm to degenerate into selection sort
Best, average case: O(nlog(n))
Worst case: O(n^2)
Not Stable
Quick:
- Divide-and-conquer
- Division complicated, Combination trivial
- Unstable due to partition
Merge:
- Divide-and-conquer
- Division trivial, Combination complicated
- Stable as long as merge is stable
Used to implement unordered sets, whereas bst's are used for ordered sets.
O(1) Search, Insert, Delete Avg Case O(n) Search, Insert, Delete Worst Case
Hash table is a collection of buckets, every element is associated with a bucket. Each value maps to a bucket via the hash function. If two values map to the same bucket then there is a collision.
bucket = hashfunction(value)
A good hash function is one that is fast and provides uniform mapping of elements regardless of values
Differences in implementation occur when dealing with collisions. Two main types:
Separate Chaining:
-
Separate linked lists attached to each bucket. Simply add colliding values to the end of the linked list.
-
Possible Implementation (using a vector of sets):
#include <iostream>
#include <vector>
#include <set>
using namespace std;
#define TABLE_SIZE (1<<10)
template <typename T>
class SCTable {
public:
SCTable(int size=TABLE_SIZE) {
tsize = size;
table = vector<set<T>>(tsize);
}
void insert(const T &value) {
int bucket = value % tsize;
table[bucket].insert(value);
}
bool find(const T &value) {
int bucket = value % tsize;
return table[bucket].count(value);
}
private:
vector<set<T>> table;
int tsize;
};
int main(int argc, char *argv[]) {
SCTable<int> s;
if (argc != 2) {
cerr << "usage: " << argv[0] << " nitems" << endl;
return 1;
}
int nitems = atoi(argv[1]);
for (int i = 0; i < nitems; i++) {
s.insert(i);
}
for (int i = 0; i < nitems; i++) {
s.find(i);
}
return 0;
}
Open Addressing:
-
Instead of using a container, each bucket only contains one value
-
When there is a collision, we use a probing sequence to search through alternate buckets. Need a sentinel value to mark buckets as unused.
-
Usually probing function is like so:
Locate(table, value):
bucket = Hash(value) % tsize
while table[bucket] != value and table[bucket] != SENTINEL:
bucket = (bucket + 1) % tsize
return bucket
- Load Factor -- a measure of table occupancy
load factor = n/m
n -- number of elements (including "deleted" elements)
m -- number of buckets
When the load factor is above a certain value, resize by a constant factor.
Probing Sequences
Linear Probing
Bucket(i) = (Hash(v) + i*StepSize) % TableSize
-
Normally, step size = 1, but it is relative to the TableSize
-
TableSize is normally prime to provide a better distribution
-
Good for caching, but susceptible to clustering
Quadratic Probing
Bucket(i) = (Hash(v) + c1*i + c2*i2) % TableSize
-
c_2 is non-zero
-
common choices are c_1 = c_2 = 1/2, c_1 = c_2 = 1, c_1 = 0 and c_2 = 2
-
better avoids clustering, but misses empty buckets
Double Hashing
Bucket(i) = (Hash1(v) + i*Hash2(v)) % TableSize
-
Uses two hash functions rather than one
-
Using a second hash function minimizes repeated collisions and clustering
Cuckoo Hashing
-
Uses multiple hash functions. For example we try location at Hash_1, then Hash_2 etc. until we find an empty bucket or run out of hash functions
-
During Insertion, if there is a collision, the current value is replaced and then rehashed with the next hash function (repeated until no more collisions or empty table)
-
Allows for very high space utilization and a worst case constant lookup time
Separate Chaining vs. Open Addressing:
Separate Chaining
-
Straighforward to implement
-
More tolerant of high load factor
-
Poor locality
Open addressing
-
Requires hash function to be uniform to minimize clustering
-
Requires limited load factor (and thus memory waste)
-
Less overhead of memory allocation
Bucket Sorting
Counting Sort
-
Compute a histogram such that
count[i] = Number of items with value i -
Iterate through histogram
if count[i] is n, then we emit n i times
-
Not a comparison based sort
-
Complexity -- O(n) running time O(MAX_VALUE) memory
-
Can work with non ints if a second pass is added:
count[i] = Number of items < i
Bucket Sort
-
Distribute values into buckets based on a hash function with a constraint:
(x1 < x2) <-> h(x1) < h(x2) -
Iterate through buckets:
a. sort each bucket
b. copy each value in bucket to original input

Implementation:
#include <algorithm>
#include <cassert>
#include <iostream>
#include <random>
#include <vector>
using namespace std;
#define MIN_VALUE (0)
#define MAX_VALUE (1000000)
template <typename T>
void bucket_sort(vector<T> &v, size_t nbuckets) {
// Initialize buckets
vector<vector<T>> buckets(nbuckets + 1);
size_t bucket_size = MAX_VALUE / nbuckets;
// Distribute v values into buckets
for (auto i : v) {
buckets[(size_t)(i) / bucket_size].push_back(i);
}
// Sort buckets and copy values back to v vector
size_t index = 0;
for (auto bucket : buckets) {
sort(bucket.begin(), bucket.end());
for (auto item : bucket) {
v[index++] = item;
}
}
}
int main(int argc, char *argv[]) {
if (argc != 3) {
cerr << "usage: " << argv[0] << " nitems nbuckets" << endl;
return EXIT_FAILURE;
}
size_t nitems = atoi(argv[1]);
size_t nbuckets = atoi(argv[2]);
vector<double> v(nitems);
default_random_engine generator;
uniform_int_distribution<int> distribution(MIN_VALUE, MAX_VALUE);
for (size_t i = 0; i < nitems; i++) {
v[i] = distribution(generator);
}
bucket_sort(v, nbuckets);
for (size_t i = 1; i < nitems; i++) {
assert(v[i] >= v[i - 1]);
}
return EXIT_SUCCESS;
}
O(n+k) avg running time
O(n+k) memory
Radix Sort
-
Hash on ith digit or character
-
Perform bucket sort as internal sort on ith+1 digit or character
Data Structure defined by a set of vertices with edges that connect one vertex to another
Undirected vs. Directed
- Undirected if edge (x, y) implies (y, x)
Weighted vs. Unweighted
- In weighted graphs, each edge is assigned a value or weight
Cyclic vs. Acyclic
- An acyclic graph does not contain any cycles
Simple vs. Non-simple
- Simple graphs avoid any double edges or self-loops
Connected vs. Disconnected
- A connected graph has a path between every pair of vertices
Graph Representations:
Adjacency Matrix
- Represent Graph G using an n x n matrix M where element M(i,j) is 1 if (i, j) is an edge of G. (Or instead of 1 the value is the weight of the edge)

-
Usually implemented as a 2D array or vector of ints or bools
-
Good for checking if an edge is present in the graph, but can take up a lot of space
Adjacency List
- Represend Graph by using lists to store neighbors adjactent to a certain vertex

- More space efficient, but not as good for checking if an edge is present
Adjacency Set
-
The same thing but with an array of sets
-
Efficient edge searching but restricted to simple graphs
Graph Operations Complexities
| Implementation | Add/Remove Edges | Checking if an edge is present | Iterating through each edge |
|---|---|---|---|
| Adjacency Matrix | O(1) | O(1) | O(v) |
| Adjacency List | O(v) | O(v) | O(e) |
| Adjacency Set | O(log(v)) | O(log(v)) | O(e) |
Graph Traversals:
DFS and BFS
Traversal(g, v):
frontier = []
marked = {}
frontier.push(v)
while not frontier.empty():
v = frontier.pop()
if v in marked:
continue
Process(v)
marked.insert(v)
for u in g.edges[v]:
frontier.push(u)
-
for DFS, use a queue for the frontier
-
for BFS, use a stack for the frontier
-
Each node passes through three phases
-
unseen
-
frontier
-
marked
-
DFS Recursive
DFS_Rec(g, v, marked):
if v in marked:
return
Process(v)
marked.insert(v)
for u in g.edges[v]:
DFS_Rec(g, u, marked)
Kahn's Algorithm:
Determines a linear ordering such that the dependency constraints are maintained
-
visit one vertex at a time; each time we visit a vertex, must remove the edges associated with that vertex
-
as we update the incoming degrees due to this removal, we add any vertices with an incoming degree of 0 to the frontier
INSERT
| Best | Average | Worst |
--------- |--------------|---------------|---------------| Unsorted | O(1) | O(1) | O(1) | Sorted | O(n) | O(n) | O(n) | BST | O(log(n)) | O(log(n)) | O(n) | RBTree | O(log(n)) | O(log(n)) | O(log(n)) | Treap | O(log(n)) | O(log(n)) | O(n) |
SEARCH
| Best | Average | Worst |
-------------|--------------|--------------------|---------------| Unsorted | O(n) | O(n) | O(n) | Sorted | O(1) | O(1) | O(1) | BST | O(log(n)) | O(log(n)) | O(n) | RBTree | O(log(n)) | O(log(n)) | O(log(n))| Treap | O(log(n)) | O(log(n)) | O(n) |