Critical worker timeout appearing once in a while in production #2682
Description
First check
- I added a very descriptive title to this issue.
- I used the GitHub search to find a similar issue and didn't find it.
- I searched the FastAPI documentation, with the integrated search.
- I already searched in Google "How to X in FastAPI" and didn't find any information.
- I already read and followed all the tutorial in the docs and didn't find an answer.
- I already checked if it is not related to FastAPI but to Pydantic.
- I already checked if it is not related to FastAPI but to Swagger UI.
- I already checked if it is not related to FastAPI but to ReDoc.
- After submitting this, I commit to one of:
- Read open issues with questions until I find 2 issues where I can help someone and add a comment to help there.
- I already hit the "watch" button in this repository to receive notifications and I commit to help at least 2 people that ask questions in the future.
- Implement a Pull Request for a confirmed bug.
Example
I am not sure if I am able to create a minimal example, see description below.
Description
I have been using FastAPI for almost a year now without almost any issues, but I met one issue which is quite hard to reproduce and I might need your help.
My backend (simplified), consists of two parts: the API, and the worker. The API is run by gunicorn, and the worker is run separately, to avoid creating duplicate instances of background tasks. They are communicating between each other via redis.
What I have is, a background task that should mark an object (invoice) as expired after certain time.
What I did is an async function, that just does asyncio.sleep, and after that it marks invoice as expired in the database.
When invoice is created (from the API, via one of the workers gunicorn is serving), an asyncio task is created to mark invoice expired later.
Also, the background worker on startup checks pending invoices if they have expired.
Seems to be working fine even after server restarts.
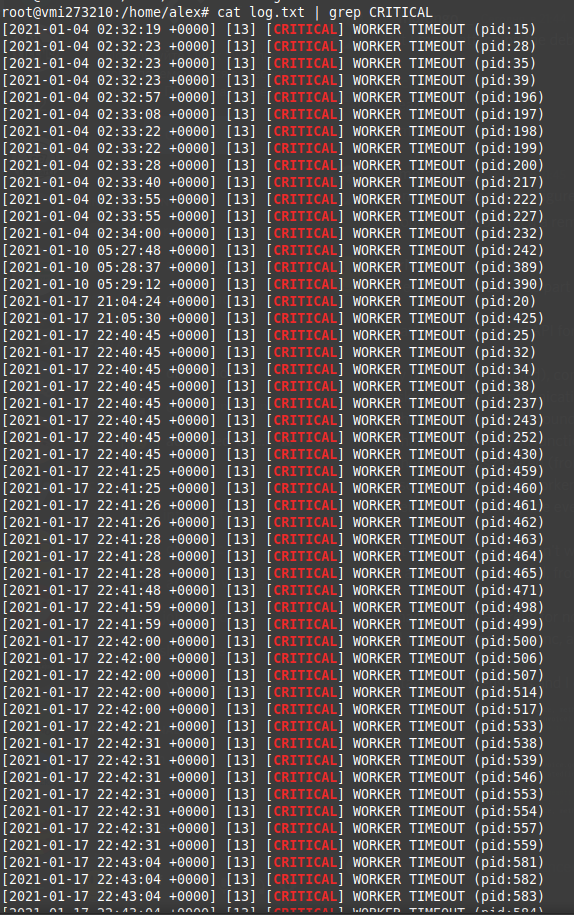
But in very cases it doesn't work, I have checked server logs, and saw a few entries with "[CRITICAL] Worker timeout"
So as far as I understand, from time to time the workers time out and get restarted, so all started async tasks are lost.
It happens quite rarely, for now 3 times: on January 4th, 10th and 17th, and every time multiple workers get restarted or get restarted multiple times.
All my functions are async, and I am not sure what exactly might cause the timeout if all the long-running functions are delegated to the worker.
Attaching screenshots, and all the code is available at github too.
I am sorry that I am unable to provide a simple example, because the project is complex, and I think that I don't have any long-running tasks in the gunicorn process (proper distribution of tasks, this system has been working great on many systems, including the demo which is running without any issues except for this for 1 month already).
I think that the issue might be just my gunicorn configuration, which is the default one almost.
I understand that it might be hard to investigate the issue, so I am ready to provide all needed details and answer all the following questions in detail. I was directed here from discord.
Environment
- OS: Linux; Docker environment with docker-compose; Custom setup:
backend component
worker component
Dockerfile - FastAPI Version: 0.63.0
- Python version: 3.6.12
Additional context
The function running as an async task:

Server logs:
How the task is started:

import multiprocessing
bind = "0.0.0.0:8000"
workers = multiprocessing.cpu_count() * 2 + 1
worker_class = "uvicorn.workers.UvicornWorker"
#!/usr/bin/env sh
set -ex
alembic upgrade head
gunicorn -c gunicorn.conf.py main:app