WMTheme: support macOS #246
Conversation
|
|
src/util/FFstrbuf.c
Outdated
| uint32_t bufSize = (uint32_t)strlen(str) + 1; | ||
| ffStrbufInitA(strbuf, FASTFETCH_STRBUF_DEFAULT_ALLOC > bufSize ? FASTFETCH_STRBUF_DEFAULT_ALLOC : bufSize); | ||
| memcpy(strbuf->chars, str, bufSize); | ||
| strbuf->length = bufSize - 1; |
There was a problem hiding this comment.
Is this really faster than an init and an append?
There was a problem hiding this comment.
Ok, but isn't this a bug?
https://github.com/LinusDierheimer/fastfetch/blob/master/src/util/FFstrbuf.c#L100
There was a problem hiding this comment.
https://github.com/LinusDierheimer/fastfetch/blob/master/src/util/FFstrbuf.c#L112
Shouldn't be strbuf.length + length + 1?
There was a problem hiding this comment.
No, ffStrbufEnsureFree ensures that there is enough space to append the given length, including the null byte.
|
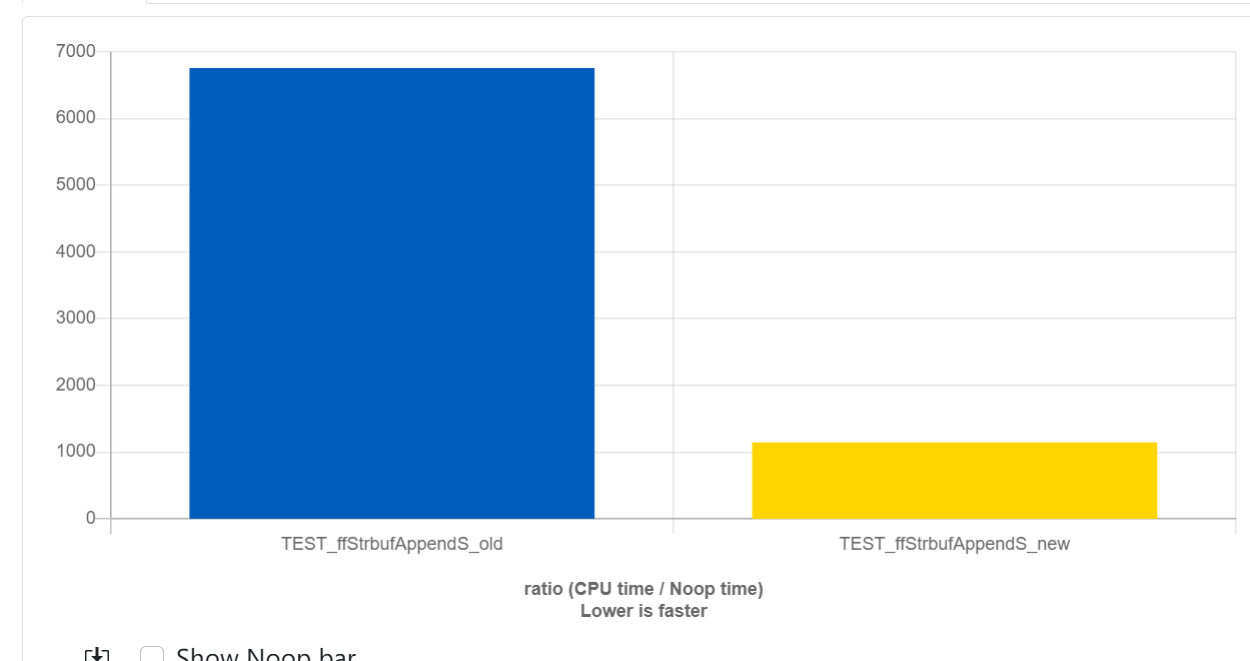
Ok, I misunderstood. However I'd say that the existing code is not optimised. void ffStrbufAppendS(FFstrbuf* strbuf, const char* value)
{
if(value == NULL)
return;
for(uint32_t i = 0; value[i] != '\0'; i++)
{
if(i % 16 == 0)
ffStrbufEnsureFree(strbuf, 16);
strbuf->chars[strbuf->length++] = value[i];
}
strbuf->chars[strbuf->length] = '\0';
}
Quick benchmark: https://quick-bench.com/q/rv4D5N9zynZRRcWb2Td7y0BVneI
|
|
Makes sense. Thanks for looking into this. |
|
ffStrbufAppendS can be further optimised by make it inline-able. static inline void ffStrbufAppendS(FFstrbuf* strbuf, const char* value)
{
if(value == NULL)
return;
ffStrbufAppendNS(strbuf, (uint32_t)strlen(value), value);
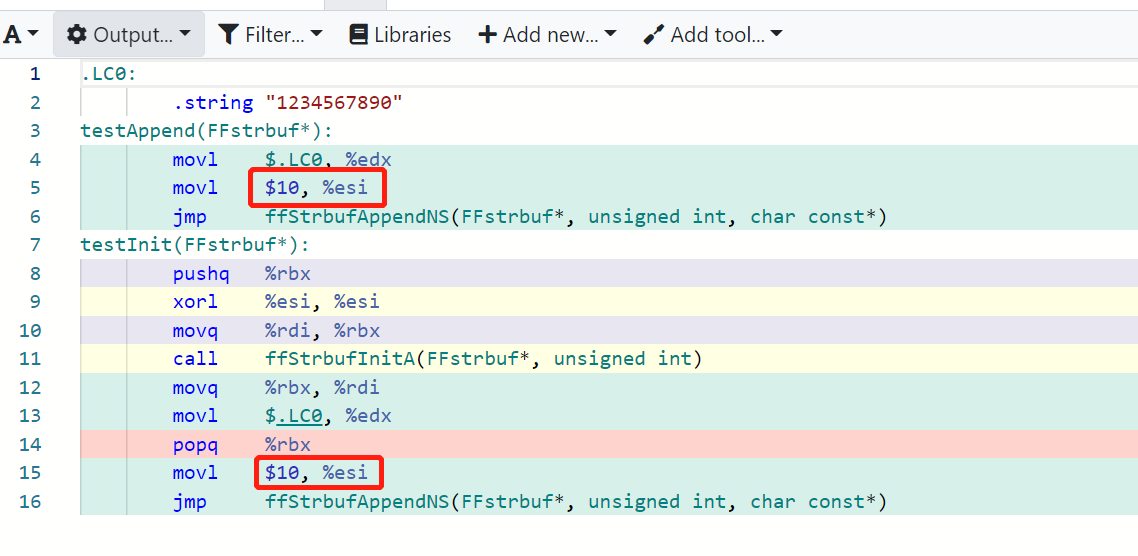
}If the value is a string literal, its length can be known at compile time. In which case // Before compiling
ffStrbufAppendS(&strbuf, "123456789");
// After compiling
ffStrbufAppendNS(&strbuf, 9, "123456789"); |
|
With the current implementation it might even make sense to force inline it. |
|
Quick test: https://gcc.godbolt.org/z/z3rrn9vfa
|
|
I don't know enough much about that, but i don't think this applies to fastfetch, because the method implementation is in another compilation unit. Might not be a problem with IPO tho. If we want to make sure it is getting inlined, we'd have to implement it as inline method in the header. |
|
Yes. A inline-able function must be in the header. Just move them into |
Note the
AppleAccentColorpart was not tested because theAppleAccentColordoesn't exist in the plist file